1. 서 론
2. 방법론
2.1 데이터 수집
2.2 변수선정방법(Feature selection methods)
2.3 용수수요 추정방법 선정 시나리오
3. 결과 및 분석
3.1 변수선정방법 적용결과
3.2 성능 평가 및 적정 모델의 선정
4. 결 론
Appendix
1. 서 론
물은 인류의 역사와 함께 국가와 도시의 발달 등과 관련하여 가장 중요한 자원 중 하나로서 역할을 해오고 있다. 따라서 국가에서는 물의 안정적 공급을 위하여 다양한 수자원 시설물을 건설하여 도시의 성장과 기후변화 등에 대응하고 있다. 하지만 이러한 수자원 시설물의 건설은 막대한 건설비용과 사회, 환경적 영향을 미침에 따라 미래 안정적 물공급을 위한 정책의사결정시 다양한 영향인자들을 고려한 미래용수수요의 예측은 매우 중요하다. 우리나라는 수자원장기종합계획을 수립하기 시작한 1960년대부터 현재까지 국가의 급격한 성장과 함께 인구수와 산업단지 등의 증가를 고려하여 용수수요를 예측하고 이에 따른 수자원 시설물을 건설해왔다. 하지만 현재 우리나라 대부분 지역과 도시는 성장이 둔화하고 있으며, 특히 인구의 순증가 등으로 인한 용수수요의 급격한 증가는 드물 것으로 예상된다. 따라서 앞으로의 미래 용수수요 추정을 위해서는 기존의 시·군별 1인 1일당 급수량(Liter Per Capita Day, LPCD)과 장래인구 추정을 이용한 성장형 시·군의 용수추정방식에서 벗어나 기후변화, 산업, 인구분포 등 다양한 계절적, 지역적, 사회적 영향변수를 고려한 새로운 장래 용수추정방법이 필요하다.
그동안 국가 수자원계획의 물수급 분석시 농업용수는 시기별 특성(관개기/비관개기)과 용도별 특성(논, 밭, 축산)에 따른 시간 해상도(반순)를 적용하여 농업용수의 수요패턴을 분석해왔다. 생·공용수의 장래 용수수요추정은 환경부 상수도 수요량 예측편람(ME, 2014)에 근거하여 과거 지자체별 이용량 기반의 평균개념인 1인 1일당 급수량과 장래인구를 이용하여 용수수요를 예측하였기 때문에 연간 용수수요가 일정하다는 가정하에 미래 용수수요를 예측하였다. 그러나 과거 용수공급실적에 따르면 생·공용수의 공급은 계절 및 지역별에 따라 월별 생·공용수 수요의 변동성을 가지고 있으며, 특히 하절기에 공급량이 증가하는 계절적인 패턴이 있음을 확인할 수 있었다(Oh et al., 2022). 따라서, 장래 물수급 분석시 용수공급패턴 변화의 적용은 물부족량 전망 결과의 신뢰도 확보와 정확도 향상 측면에서 중요한 요소이다.
최근까지 장래용수수요 추정을 위한 다양한 영향변수들에 관한 연구를 살펴보면, Yoo and Yang (2005)은 대도시 804가구의 상수도 수요량 설문조사를 통해 “(a) 수돗물을 식수로 이용하지 않는 가구인 경우, (b) 세대수가 많을 경우, (c) 구성원에 65세 이상 고령인이 많을수록, (d) 공동주택보다 단독주택에 거주할 경우, (e) 가구소득이 높을수록” 상수도 사용량이 증가한다는 결과를 얻었다. Kim et al. (2008)은 전국 40가구에 대해 주택유형, 실거주인 수, 가족 구성원, 자녀 구성, 맞벌이 여부, 입주형태, 건평, 화장실 수, 목욕탕 수, 정수기 유무, 절수기 유무, 가계수입 등을 물수요에 대한 영향변수로 선정하여 분석하였다. Choi and Kim (2006)은 Mann-Kendall Test와 Spearman’s Rho Test를 통해 가정용수 수요패턴의 증감에 영향을 미치는 영향인자(세대수, 유아초등학생의 유무, 음용수 종류, 월수입, 건평수 등)를 선정하였다. Kim et al. (2008)은 전국 140여개 가구에 대해서 내부적 요인(주거형태, 거주자 생활양식, 주택구조)과 외부요인(온도, 날씨, 수도요금)이 LPCD에 미치는 영향을 연구하였다. Buck et al. (2020)은 미국 Texas주 Austin지역 산업단지의 산업단지 면적과 고용률을 물사용 패턴의 영향인자로 선정하여 상관성을 분석하였다. Xenochristou et al. (2020)은 영국 남서부 1,793개 가구의 조사를 통해서 재산 등의 사회경제적 요인과 일조량, 습도, 강우량, 기온, 지중온도 5개 기상변수를 활용하여 용수수요패턴을 분석하였다. Nunes Carvalho et al. (2021)은 브라질 Fortaleza시의 용수수요예측을 위해 인구통계변수인 남성과 여성의 비율, 고령화 비율, 세대수, 기대수명과 사회경제적 변수인 고용비율, 소득수준, 교육수준, 주거형태의 영향변수를 도시의 용수수요예측에 활용하였다. Capt et al. (2021)은 미국 남서부의 Texas주 El Paso시의 인구, 기온 등을 활용하여 용수수요를 예측하였으며, Hariharan et al. (2022)는 미국 플로리다주 Fort Myers 건설노동자 9,482명을 대상으로 기상변수인 기온, 강수량, 습도에 따른 용수수요의 변화를 분석하였다. 이와 같이 장래용수수요 추정을 위해 기상변수, 주거형태, 직업군 등 다양한 영향변수를 사용하였으나, 대부분의 연구가 시군 등의 행정단위보다는 특정가구나 지역 등 영향변수의 영향력이 잘 나타날 수 있는 소규모 지역을 연구대상으로 용수수요를 추정하였다.
앞 절에서 언급한 것과 같이 용수수요 예측에 영향을 미치는 영향변수가 선정되면 이를 이용하여 장래 용수수요를 추정하게 된다. 전통적으로 시계열자료의 미래 예측을 위하여 AR (AutoRegression), MA (Moving Average), ARIMA (AutoRegressive Integrated Moving Average)(Fattah et al., 2018) 등의 방법을 사용해왔으며, 최근에는 Random Forest (Breiman, 2001), XGBoost (Extreme Gradient Boosting)(Chen and Guestrin, 2016)와 같은 머신러닝 방법들이 시계열자료의 미래예측에 도입되고 있다. 또한, 다양한 머신러닝 방법의 적용시 미래예측에 신뢰성이 있는 영향변수를 선정하기 위해서 다양한 변수선정 방법(Feature Selection Methods) 들이 이용되고 있다(Chandrashekar and Sahin, 2014). 먼저 가장 기본적으로 사용되는 변수선정 방법으로는 Filter 선정방법이 있으며, Filter 선정방법 중 주로 사용되는 방법은 Variance 방법, Mutual Information 방법 등이 사용되고 있다. 다음으로 각 영향변수의 다양한 조합을 통해 머신러닝 모델을 평가하여 영향변수를 선정하는 Wrapper 선정방법이 있으며, 주로 사용되는 방법은 Step Forward and Backward Selection, Exhaustive 선정방법 등이 있다. 마지막으로 Filter와 Wrapper 방법을 혼합한 Embedded 방법이 있으며 주로 사용되는 방법은 Lasso, Random Forest Importance, Recursive 변수선정 등의 방법이 있다. 이를 통해서 영향력이 큰 변수를 선정하여 머신러닝에 적용함으로써 학습시간을 절약하고, 테스트시 변동성을 최소화함으로써 예측의 신뢰성과 효율성을 높일 수 있는 장점이 있다(Chandrashekar and Sahin, 2014). 최근 Pourmousavi et al. (2022) 연구에서는 Smoothness Index를 이용한 변수선정방법의 적용을 통해서 용수수요예측의 신뢰도를 향상시킬 수 있음을 보여주었다.
이와 같이 위에서 제시한 변수선정방법을 통해 선정된 영향변수와 다양한 시계열 예측방법을 이용하여 미래 용수수요를 예측할 수 있다. 하지만 앞에서 언급한 바와 같이 우리나라에서는 연간 실적을 인구로 나눈 1인 1일당 급수량과 지역별 장래 인구예측자료를 활용하여 예측한다. 미국 캘리포니아 등에서도 현재까지 실무에서는 우리나라와 유사한 방법이 사용되고 있고, 일부 지방정부에서는 토지이용과 경제적 요소도 고려하여 용수수요추정을 하고 있다(Buck et al., 2020). 연구적으로는 MLR (Multiple Linear Regression)을 활용한 방법, Monte Carlo Simulation 등도 많이 사용되어 왔으며, 최근 머신러닝과 딥러닝 (Buck et al., 2020; Maußner et al., 2025; Yang et al., 2024)을 활용한 방법 등에 대한 많은 연구도 진행되었다.
본 연구에서는 먼저 (1) 10년이상의 용수공급 데이터가 있는 10개 시군을 대상으로 과거 용수 수요예측 연구에 활용된 22개 영향변수와 종속변수인 용수공급량에 대한 데이터를 수집(‘05~21년내 12~17년 데이터)하고, (2) 조사된 22개의 영향변수를 6가지 영향력이 큰 변수선택 기법을 적용하여 빈도수가 높은 5개(동일 빈도로 인해 5개 초과시 동일 빈도변수는 모두 선택)의 영향변수를 선정하였다. 마지막으로 (3) 3가지 CASES (CASE-1: 모든 22개 영향변수를 Random Forest와 XGBoost모델에 적용, CASE-2: 영향력이 큰 영향변수를 Random Forest와 XGBoost모델에 적용, CASE-3: 용수공급량 변수를 Prophet모델의 입력자료로 단변량 분석)을 적용하여 데이터의 신뢰도와 영향변수의 영향력에 따른 시군별 적절한 미래 용수수요 추정방법론을 제시하였다.
2. 방법론
먼저 미래 용수수요추정을 위해 수집된 종속변수(월별 용수공급량)과 독립변수(22개 영향변수)의 종류, 수집경로, 데이터 기간 및 단위 등에 대해서 설명하였다(2.1). 다음으로 3가지 미래 용수수요추정 CASES 중 CASE-2의 적용시 영향력이 큰 영향변수의 선정을 위해 이용된 6가지 변수선정방법에 대해서 설명하였다(2.2). 마지막으로 시군별 종속변수의 데이터 품질, 영향변수의 종속변수에 대한 영향력 등을 고려하여 적절한 미래 용수수요 추정방법 선정을 위해 3가지 Cases의 용수수요 추정방법을 설명하였다(2.3).
2.1 데이터 수집
데이터는 서론에서 언급한 국내·외 연구의 용수수요추정에 사용된 영향변수와 통계 자료의 수집가능성을 고려하여 계절성 7개, 지역성 10개, 사회성 5개의 총 22개 독립변수(영향변수)를 수집하였다. 또한, 학습을 위한 종속변수인 10개 시·군별 용수공급량을 수집하고 다음과 같이 각 변수에 대해서 설명하였다.
2.1.1 종속변수: 월별 용수공급량
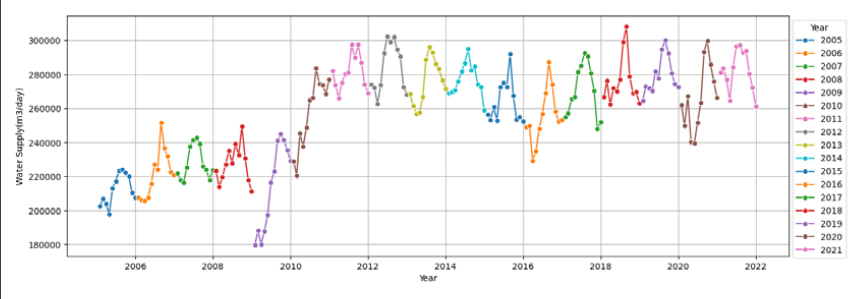
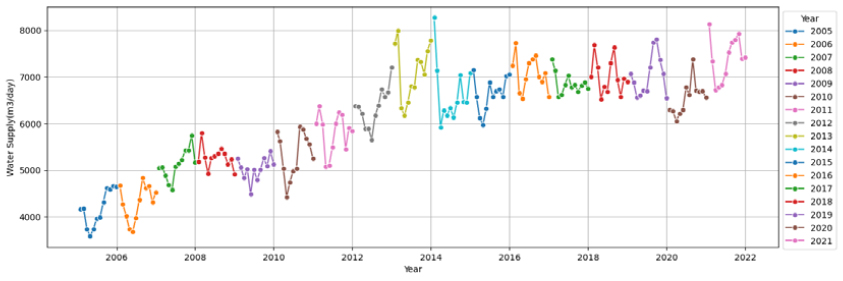
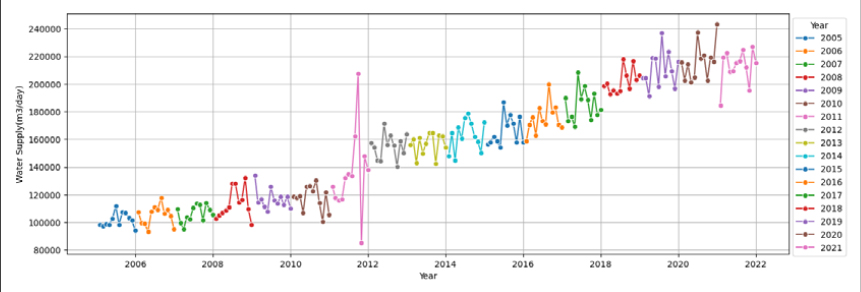
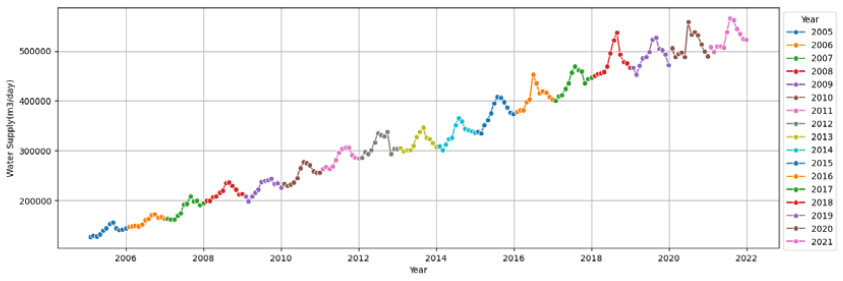
물이용 패턴의 분석과 예측을 위해서 먼저 환경부와 K-water가 발간하는 ‘가뭄기초조사 보고서’에서 제시한 지자체 지방상수도 시설의 5년간(’17~’21) 월별 공급실적자료를 수집하였다. 하지만 5년간 데이터는 데이터가 60개(5년×12개월)로 용수수요예측을 위한 모델의 구축 및 검증에는 데이터가 부족하여 K-water 자체자료로 보완가능한 10개 시·군을 선정하여 17년간(’05~’21) 월별 공급자료를 종속변수 데이터로 수집하였다. 그리고 17년간의 자료 활용시 지자체별 공급량에 대한 생활용수와 공업용수의 구분이 어려워 구분없이 합계한 용수공급실적을 데이터로 사용하였다. 단위는 월별자료(m3/월)로 수집하였으나 월별 일수로 나눠서 m3/일로 재산정하여 월별일수가 달라서 생길수 있는 변동성을 제거하였다(Table 1).
Table 1.
Target variable (1)
2.1.2 독립변수
(1) 계절성 영향변수
계절성 영향변수는 평균온도, 강수량, 상대습도, 일조시간, 지면온도, 평균풍속, 평균기압 7개의 영향변수를 선정하고 종속변수와 동일하게 17년간 관측자료를 수집하였다. 데이터는 기상청의 기상자료 개방포털(https://data.kma.go.kr)의 종관관측 기상자료와 방재관측기상자료를 활용하여 수집하였다(Table 2).
Table 2.
Seasonal independent variables (7)
(2) 지역성 영향변수
지역성 영향변수는 인구, 세대수, 세대당 인구수, 남·여 인구수, 65세이상 고령화 비율, 전력사용량, 산업체수, 100인 이상 사업장수, 산업단지 면적 총 10개의 영향변수를 선정하였다. 데이터는 인구관련 자료와 고령화 비율 자료는 행정안전부의 주민등록인구 통계(http://jumin.mois.go.kr)를 활용하여 지자체별 데이터를 구축하였다. 전력사용량은 한국전력공사의 전력데이터 개방 포털시스템(https://bigdata.kepco. co.kr), 산업체 관련자료는 고용 행정통계(https://eis.work. go.kr)와 산업입지정보센터의 자료(https://www.industryland. or.kr)를 활용하여 지자체 데이터를 구축하였다(Table 3).
Table 3.
Regional independent variables (10)
(3) 사회성 영향변수
사회성 영향변수는 가계소득(주민1인당 자체수입액), 학력수준(고등학교 졸업자 비율), 인건비, 연간평균수입대비 인건비, 취업률(고용보험자 비율) 총 5개의 영향변수를 선정하였다. 가계소득과 인건비 관련 자료는 지방재정365(지방재정통합공개시스템, https://lofin.mois.go.kr), 학력수준은 공공데이터 포털 한국교육개발원 자료(https://www.data.go. kr), 취업률과 관련된 자료는 고용행정통계(https://eis.work. go.kr), 취약계층 가구와 관련된 자료는 한국사회보장정보원의 자료(https://www.bokjiro.go.kr)를 수집하였다(Table 4).
Table 4.
Social independent variables (5)
2.2 변수선정방법(Feature selection methods)
변수선정방법은 예측하고자 하는 종속변수의 예측을 위한 다양한 영향변수가 있을 경우, 영향력 있는 변수를 선정하여 모델에 적용함으로써 모델의 예측성능 및 효율을 향상시키는 방법이다. 예측모델의 개발시 영향력이 낮은 영향변수를 포함하여 모델을 학습하게 되면 테스트 단계에서 성능이 급격히 저하되는 문제점이 발생하여 신뢰성있는 결과를 얻기 어려워진다. 또한, 많은 영향변수를 이용하여 모델을 학습할 경우, 계산을 위한 자원과 시간이 늘어나게 되는 단점이 있다. 따라서, 본 장에서는 일반적으로 많이 사용되고 있는 변수선정방법인 (1) Filter 변수선정방법, (2) Wrapper 변수선정방법, 그리고 (3) Embedded 변수선정 방법들에서 주로 사용되는 몇가지 방법들을 선정하여 영향력 있는 변수를 선정하였다.
2.2.1 Filter 변수선정방법
Filter 변수선정방법은 세 가지 방법 중 가장 간단한 방법으로 별도의 모델학습 없이 변수선정을 할 수 있어서 다른 선정방법에 비해 계산자원과 시간이 적게 소요되는 장점이 있으나 다른 선정방법들에 비해 모델성능이 떨어지는 단점이 있다. 본 섹션에서는 대표적인 Filter 변수선정방법인 Variance 방법과 Mutual Information 방법 2가지를 적용하였다.
(1) Variance 방법
Variance 방법은 영향변수의 분산이 특정 한계값(Threshold)보다 작으면 제외하는 방법이다. 영향변수의 분산이 너무 작으면 각 영향변수의 값의 변화가 종속변수의 값의 변화에 미치는 영향이 미비하여 예측하는 성능이 낮아진다고 판단하기 때문이다. Variance 방법의 단점은 영향변수의 분산만 고려하여 만약 어떤 영향변수의 분산이 작더라도 종속변수와 상관관계가 높으면 용수수요 예측시 영향을 줄 수 있으나, 분산이 작다는 이유로 제외됨으로써 모델의 성능을 저하시킬 수 있는 우려가 있다. 그리고 한계값의 설정이 주관적으로 설정되어 모델의 성능에 대한 안정성이 높지 않을 수도 있다는 단점이 있다.
(2) Mutual Information 방법
Mutual Information 방법은 영향변수와 종속변수간의 의존성을 측정하는 방법으로써 대표적인 머신러닝 Python 라이브러리인 Sklearn의 “mutual_info_classif” 함수를 사용한다. 본 방법은 영향변수와 종속변수간에 Mutual Information 점수를 정량적으로 제공해줌에 따라 좀 더 객관적으로 영향변수를 선택할 수 있다.
2.2.2 Wrapper 변수선정방법
Wrapper 변수선정방법은 모든 영향변수의 부분집합 조합에 대해 일정한 하이퍼파라미터 세팅을 이용하여 모델을 실행하고 성능을 평가한 후, 가장 성능이 좋은 조합을 찾아내는 방법이다. 따라서 많은 계산자원과 시간이 요구되는 방법이다. 하지만 일반적으로는 Wrapper 변수선정방법은 모든 영향변수의 부분집합에 대한 평가를 하기 때문에 Filter 변수선정방법에 비하면 성능이 우수하다는 장점이 있다. 각 부분집합의 성능을 평가를 위해서 Random Forest 모델, 성능지표(Performance Metric)는 결정계수(Determination Coefficient, R2)를 적용하였다. 본 섹션에서는 대표적인 Wrapper 변수선정방법인 Exhaustive 변수선정방법, Step Forward 변수선정방법, Step Backward 변수선정방법 3가지를 적용하였다.
(1) Exhaustive 변수선정방법
Exhaustive 변수선정방법은 Wrapper 변수선정방법 중에서 가장 단순하지만 모든 영향변수의 부분집합 조합에 대한 성능을 테스트하는 방법으로써 많은 계산자원과 시간을 요구한다는 단점이 있다. 예를 들면, 본 연구와 같이 22개의 영향변수를 이용했을 경우, 222-1(4,194,303개)의 영향변수 부분집합 조합에 대한 성능평가를 해야 한다. 하지만 최적의 영향변수조합을 찾는데 있어서 지역 최적해에 빠지지 않고 전역 최적해를 찾을 수 있다는 장점이 있다.
(2) Step Forward and Backward 변수선정방법
Step Forward와 Backward 변수선정방법은 Exhaustive 변수선정방법의 성능을 최대한 유지하면서 Exhaustive 탐색에 걸리는 시간을 최대한 줄여주는 방법이다. 먼저 Step Forward 변수선정방법은 아무런 영향변수가 선택되지 않은 상태에서 개별 영향변수를 하나씩 추가하면서 가장 성능이 좋은 영향변수의 조합을 찾아가는 방법이다. 반대로 Step Backward 변수선정방법은 Step Forward 변수선정방법과 반대로 모든 영향변수를 넣은 상태에서 개별 영향변수를 하나씩 제거하면서 가장 성능이 좋은 영향변수의 조합을 찾아가는 방법이다.
2.2.3 Embedded 변수선정방법
Filter 변수선정방법은 간단한 조건 등을 고려하여 모델의 적용없이 영향변수를 선택하는 방법이었고, Wrapper 변수선정방법은 다양한 영향변수의 조합을 통해서 특정모델의 성능을 평가한 후 최적의 영향변수를 선택하는 방법이었다면 Embedded 선정방법은 sklearn의 각 머신러닝모델에서 제공해주는 Feature Importance Methods을 이용하여 중요한 영향변수를 우선 선정하여 모델에 적용하여 성능을 평가하는 방법이다. 본 섹션에서는 대표적인 Embedded 변수선정방법 중 Lasso방법을 이용한 변수선정방법, Random Forest를 이용한 변수선정방법, Random Forest를 이용한 Recursive 변수선정방법 3가지를 적용하였다.
(1) Lasso and Random Forest를 이용한 변수선정방법
본 방법에서 모델과 연계해서 사용하는 Feature Importance Method는 Random Forest와 같이 트리기반 알고리즘을 사용하는 모델에 적용되는 방법이다. 트리기반 모델을 학습하면 각 영향변수마다 Feature Importance를 추출할 수 있게 된다. 이렇게 추출된 값을 고려하여 주관적으로 특정 개수의 영향변수를 선택하여 모델의 성능을 평가하는 방법이다. 본 연구에서는 Lasso와 Random Forest 머신러닝 모델을 이용하여 Feature Importance를 추출하였다.
(2) Random Forests Importance를 이용한 Recursive 변수선정방법
Recursive 변수선정방법은 위와 같이 Feature Importance를 적용하는 것은 동일하지만 영향변수를 선정함에 있어서 Embedded 방법과 유사하게 모든 조합의 영향변수 조합을 고려하여 가장 성능이 좋은 영향변수의 조합을 선정하는 방법이다. 차이점은 사용자가 원하는 영향변수의 개수를 지정하게 되고 이에 맞는 영향변수를 선택하면서 최적의 성능을 제공하는 영향변수의 조합을 제공해준다. 본 방법은 적용을 위해 sklearn의 RFE (Recursive Feature Elimination) 함수를 활용하였다.
2.3 용수수요 추정방법 선정 시나리오
앞 절에서 설명한 변수선정 방법들을 이용하여 영향력이 큰 변수를 선정하고, 선정된 변수를 활용하여 용수수요 추정시 신뢰할 수 있는 머신러닝 방법을 선정하기 위해서 Table 5와 같이 3가지 CASES에 대한 용수수요 추정방법 시나리오를 선정하였다. 일반적으로는 동일한 입력 시나리오와 평가방법을 이용하여 각 CASES들에 대해서 성능을 평가하고 가장 성능이 높은 방법을 선정해야 한다. 하지만, 본 연구는 시간적으로 월단위 시간해상도, 공간적으로 시·군단위 공간해상도의 자료를 이용하고 있다. 특히, 공간적으로 시군단위의 분석은 가정과 상업적으로 이용되는 용수이용의 특성을 구분하기 힘들고, 그 외의 공간적으로 발생하는 다양한 용수공급처에 대한 복합적 영향을 상쇄시키므로써 영향변수를 이용한 용수수요의 추정을 어렵게 하고 있는 것이 현실이다. 따라서 이러한 제약사항들을 고려하여 먼저 CASE-1에서는 조사한 전체 22개 영향변수, CASE-2에서는 변수선정방법을 통해 선정된 영향력이 큰 영향변수를 적용하였으며 머신러닝 모델로는 Regression모델로 가장 일반적으로 적용되는 Random Forest와 XGBoost모델을 적용하였다. 그리고 CASE-3는 최근 대한민국의 시군별 발전상황을 고려시 영향변수의 영향력이 크지 않은 것을 고려하여 단변량 분석방법으로 종속변수인 용수공급량만을 효율적으로 이용하여 용수수요를 예측할 수 있는 Prophet모델을 적용함으로써 (1) 영향독립변수의 사용시(CASE-1과 CASE-2)와 종속변수인 용수공급량만을 입력자료로 활용한 분석방법(CASE-3)을 비교하여 현재 이용가능한 용수공급데이터를 활용하여 가장 적합하게 이용할 수 있는 용수수요추정 방법을 제시하고자 하였다(Table 5).
Table 5.
Application Scenarios for Appropriate Water Demand Forecast Model Selection of 10 Cities
Random Forest방법은 기존의 의사결정트리(Decision Tree) 모델의 단점을 보완하기 위해서 단일의사결정트리 모델을 여러개로 늘려서 Forest를 만들면서 전체데이터셋에 Bagging방법을 활용해서 부분집합 데이터를 무작위추출하고 각 분석된 결과를 조합하여 모델의 예측을 하는 방법으로써 기존의 단일 의사결정트리의 Overfitting을 피할 수 있는 장점을 가지고 있다. XGBoost은 기존의 트리 앙상블 구조의 성능을 향상시킨 방법으로 주로 병렬컴퓨팅, 분할탐색알고리즘 등을 통한 속도향상, 결측값 처리방법 등을 통한 데이터 적용의 효율화 등 다양한 부분에서 성능을 개선한 모델이다. 마지막으로 Prophet모델은 Meta에서 개발한 시계열 분석모델로써 간단하면서도 정확도가 높고 빠르며 직관적이어서 다양한 분야의 도메인 전문가들에 의해서 많이 사용되는 모델이다. 특히, 데이터의 추세(Trend), 계절성(Seasonality)의 특성을 쉽게 적용할 수 있어 추세와 계절성의 특성을 가진 데이터의 분석에 용이하며, 공휴일 이벤트 영향도 적용할 수 있어 불규칙한 이벤트를 시계열분석에 활용할 수 있는 장점이 있다.
3. 결과 및 분석
본 장에서는 먼저 용수수요추정을 위해서 조사된 대표 10개 시·군의 22개 영향변수에 변수선정방법(2.2)를 적용하여 선정된 각 시군별 영향력이 큰 영향변수에 대해서 설명하였다. 다음으로 이를 기반으로 2.3절에서 제시한 3가지 Cases의 용수수요 추정방법 선정 시나리오를 적용하여 시·군별 적정한 용수수요 추정방법을 제시하였다.
3.1 변수선정방법 적용결과
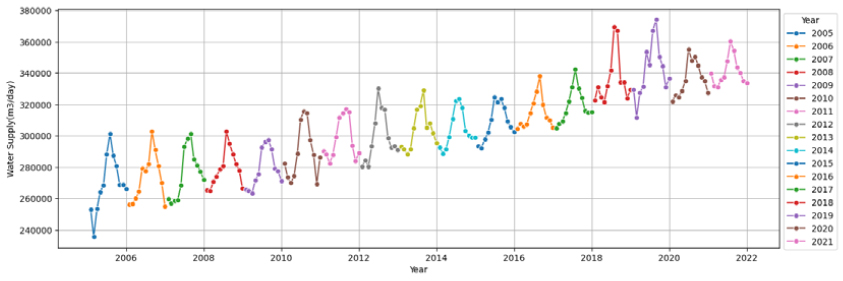
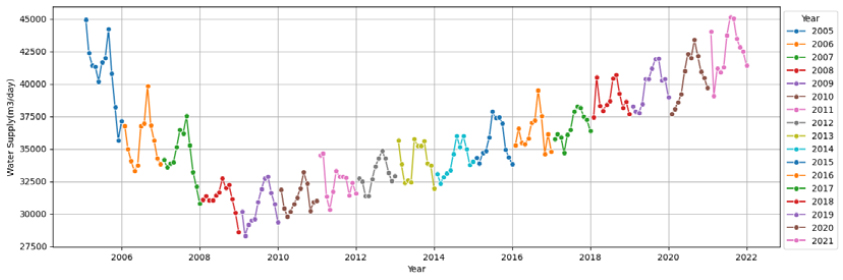
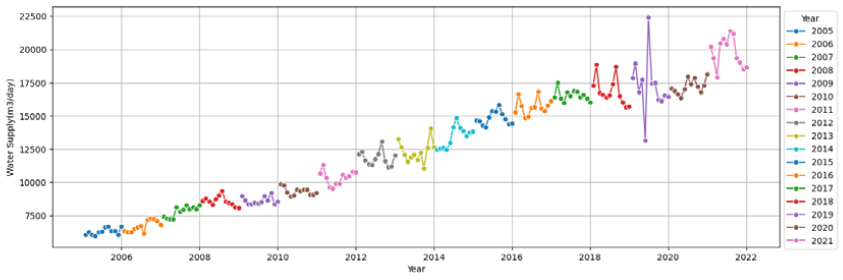
6가지 변수선정방법을 이용하여 10개 대표 시·군, 각 22개 영향변수에 대해 영향력이 큰 영향변수를 선정하였으며, Fig. 1(a)는 고양시의 예를 보여준다. 영향력이 큰 영향변수의 선정은 각 변수선정방법을 통해 선정된 영향변수를 모아서 빈도가 높은 순으로 오름차순하여 최종 빈도수가 가장 높은 영향변수 5개를 선정하는 것을 원칙으로 하였으며, 만약 다섯 번째 변수에 동일빈도의 변수들이 2개이상 있을 경우는 동일빈도 변수들을 모두 선택하는 것으로 하였다. 10개 시군에 대한 결과는 Table 6와 같다. 고양시의 경우, 계절성과 트랜드를 모두 잘 표현하는 데이터의 특성(Fig. 2)을 가지고 있음에 따라 계절적 특성을 나타내는 전력사용량(Power Usage)와 평균상대습도(Average Relative Humidity)가 영향력이 높은 독립변수로 선정되었고, 주로 트랜드적 특성을 가지고 있는 100인이상 사업장(Business Above 100)과 산업단지면적(Complex Area)이 영향력이 높은 독립변수로 선정되었다. 하지만 일반적으로 평균 풍속은 계절적 특성이 크지 않음에도 영향력이 높은 독립변수로 선정된 것을 보아 전반적으로 영향변수의 종속변수(용수공급량)에 대한 영향력이 크지 않음을 알 수 있다. 또한, 그 외 시·군도 모두 평균 풍속(Average Wind)을 포함하고 있어 전반적으로 영향변수의 종속변수(용수공급량)에 대한 영향력이 크지 않음을 짐작할 수 있다. 이외의 데이터의 월별 변화와 트랜드에 대한 결과는 Appendix 1을 참고하면 된다.
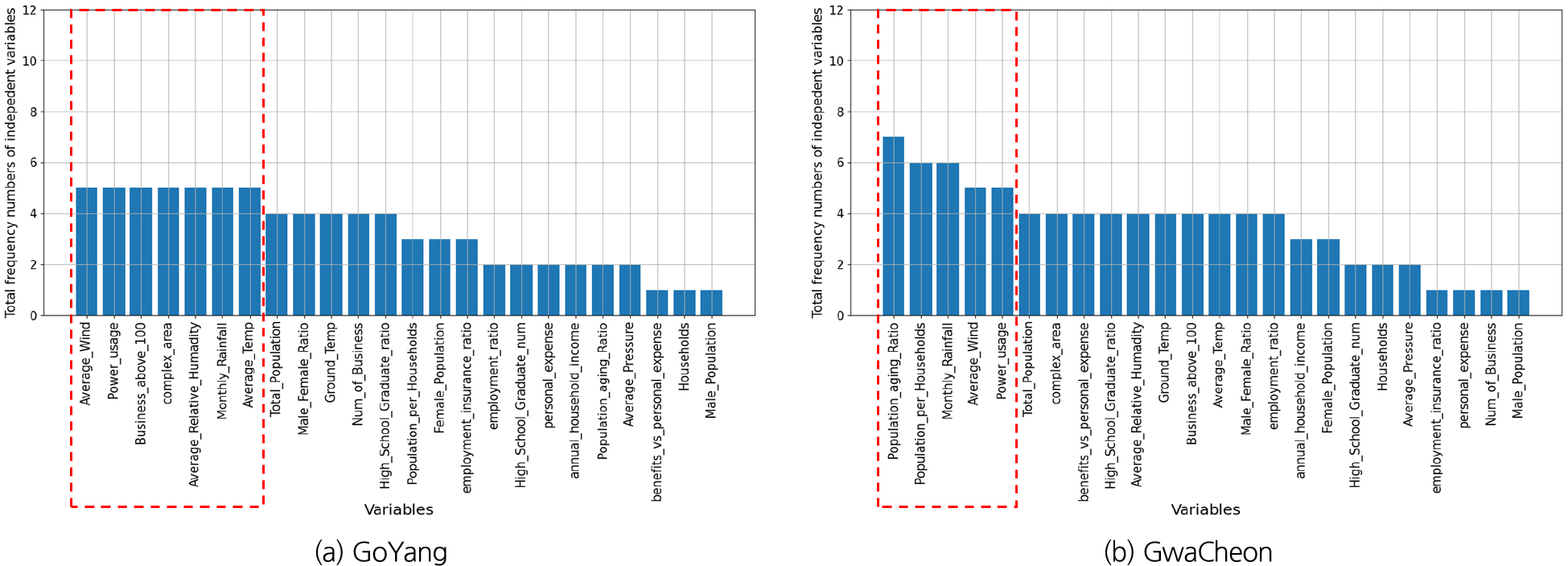
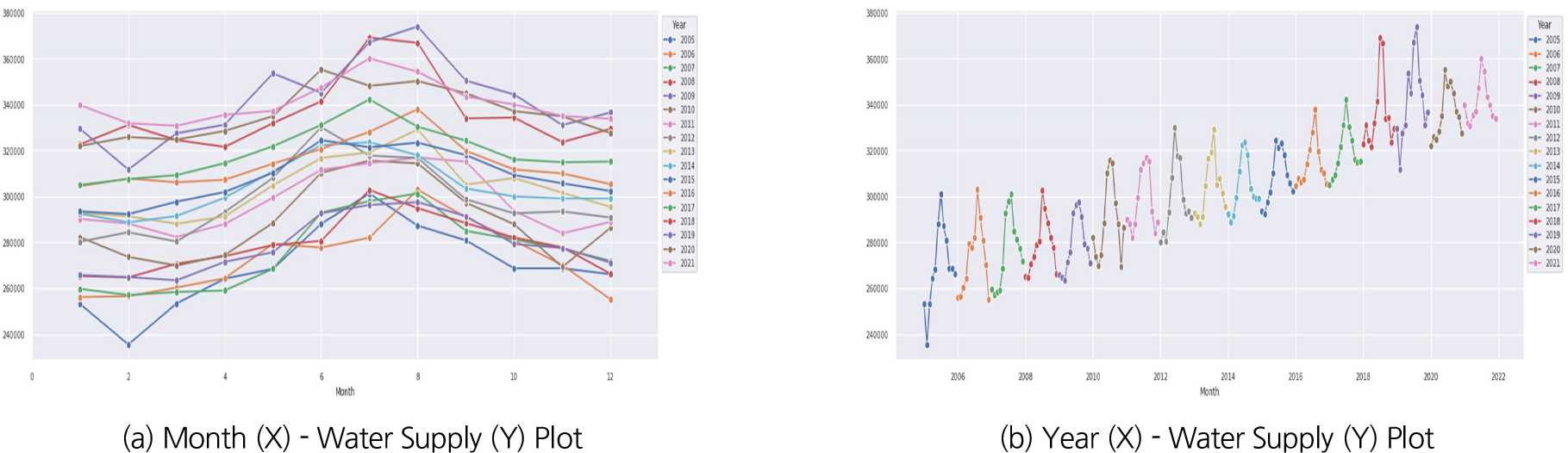
Table 6.
Selected five or more independent variables in 10 cities
3.2 성능 평가 및 적정 모델의 선정
3가지 CASES에 대해서 성능을 평가하기 위해서 먼저 조사된 데이터 중 데이터 기간이 가장 짧은 학력수준(고등학교 졸업자 비율) 데이터의 기간(2010-01~2021-12, 12years)을 고려하여 Table 7과 같이 2010.1월~2018.12월까지 9년간을 학습기간(Training Periods), 2019.1월~2021.12월까지 3년간을 테스트기간(Testing Periods)으로 설정하여 적정 용수수요 예측모델 선정방법을 평가하였다.
Table 7.
Setting of training and testing periods
| Training Periods | Testing Periods | |||
| 2010.1~2018.12(9years, 108 data) | 2019.1~2021.12(3years, 36 data) | |||
결과 분석시 다음과 같이 두가지 관점에서 적정 모델 선정방법을 분석하였다. 첫 번째는 3가지 CASES의 R2, RMSE (Root Mean Squere Error), RMSEPE (Root Mean Square Error Percentage Error)의 성능평가 결과에 따라 시나리오별 적용된 영향변수의 종속변수에 대한 영향력을 판단하고, 이에 따른 적절한 미래 용수수요 추정방법을 선정하였다. 두 번째로는 3가지 CASES에 대해서 적절하게 모델을 선정할 수 있는 성능이 나오지 않는 경우, Appendix 1을 통해서 데이터의 품질을 확인하고 이에 대해 적정 모델의 선정 가능성 여부를 판단하여 최종결과(Table 8)를 제시하였다.
Table 8.
Performace reults of 3 cases in 10 cities
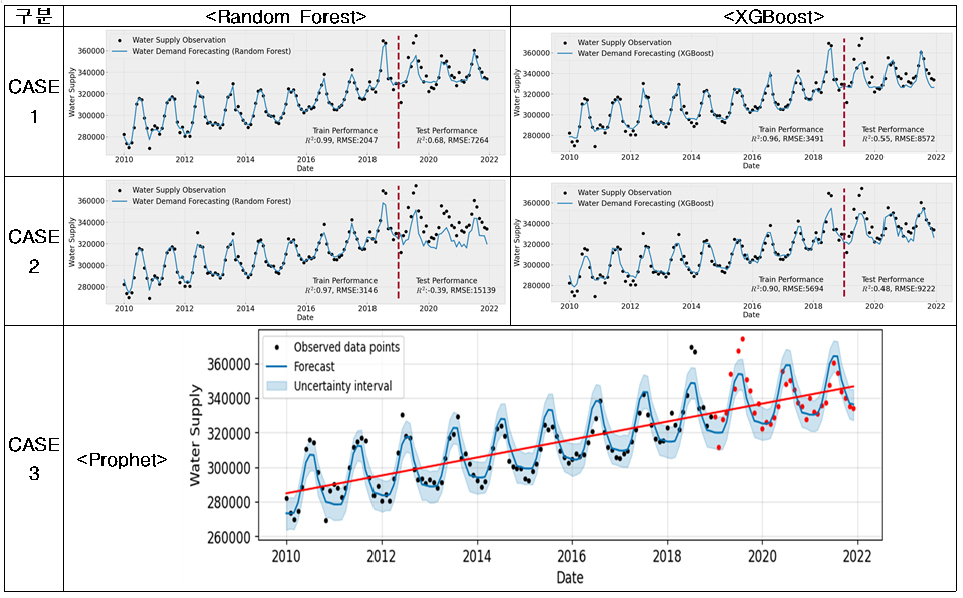
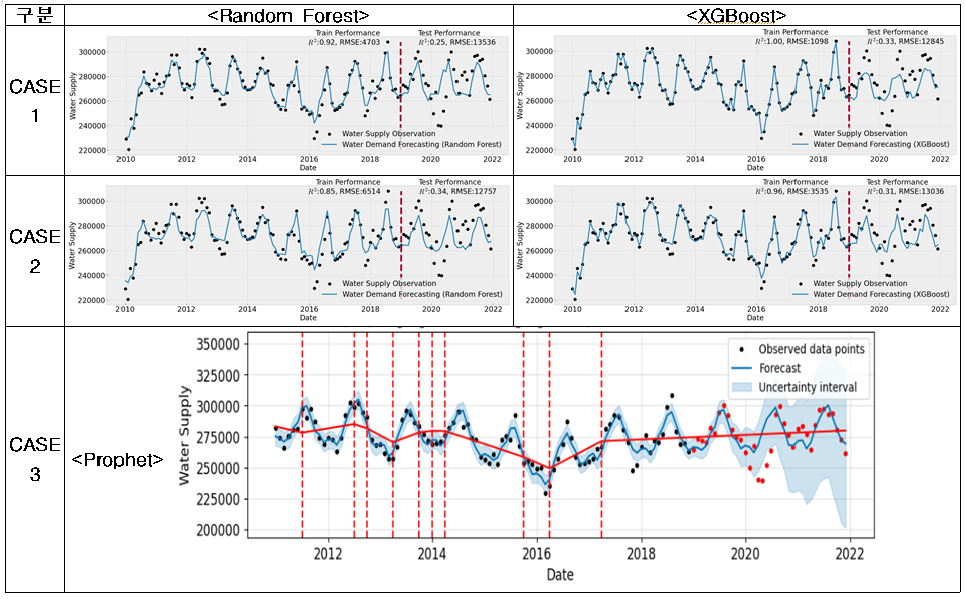
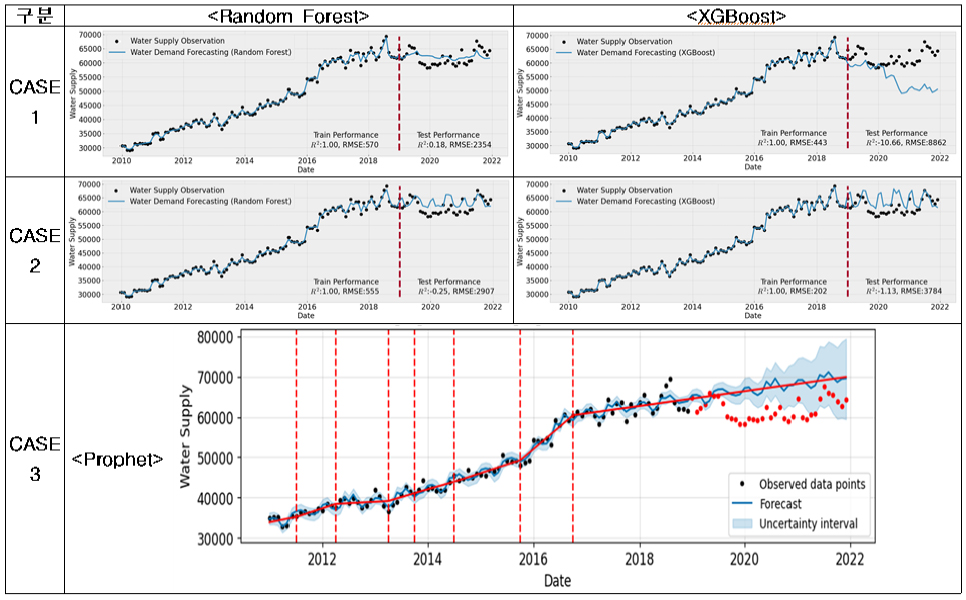
먼저 (1) 고양시의 경우, 용수공급 데이터가 타 9개 시·군에 비하여 월별 계절성과 년별 트랜드를 잘 나타내고 있고, 데이터의 품질이 양호함을 확인할 수 있다(Appendix 1). 미래 용수수요 추정방법의 평가결과(Fig. 3)는 전체 영향변수를 활용한 CASE-1과 단변량분석으로 Prophet을 활용한 CASE-3의 경우, 학습(R2=0.86~0.99, RMSE=2,047~6,365, RMSEPE= 0.67~1.95)과 테스트(R2=0.55~0.68, RMSE=7,264~8,572, RMSEPE= 2.10~2.46)로 양호한 결과를 얻을 수 있었다. 하지만 변수선정방법을 적용한 CASE-2의 경우 ① 평균풍속, ② 전력사용량, ③ 100인이상 사업장수, ④ 산업단지면적, ⑤ 평균상대습도, ⑥ 월강수량, ⑦ 평균 온도 7개의 영향변수를 적용시 학습(R2=0.90~0.97, RMSE=3,146~5,694, RMSEPE= 0.99~1.82)에서는 좋은 성능을 보였으나 테스트(R2=-0.39~ 0.48, RMSE=9,222~15,139, RMSEPE=2.64~4.39)에서 R2의 변동성이 크고, RMSE와 RMSEPE도 큰 오차를 보였다(Table 8). 결론적으로 고양시는 테스트 시작기간인 2019년에 실제 용수공급데이터가 갑작스럽게 높게 나타나면서 2018년까지의 데이터로 학습된 모델에서 예측한 용수수요와 큰 오차가 발생한 것으로 판단되며, R2결과로는 CASE-1, 2, 3 모두 모델로써 적합한 것으로 판단되었다.
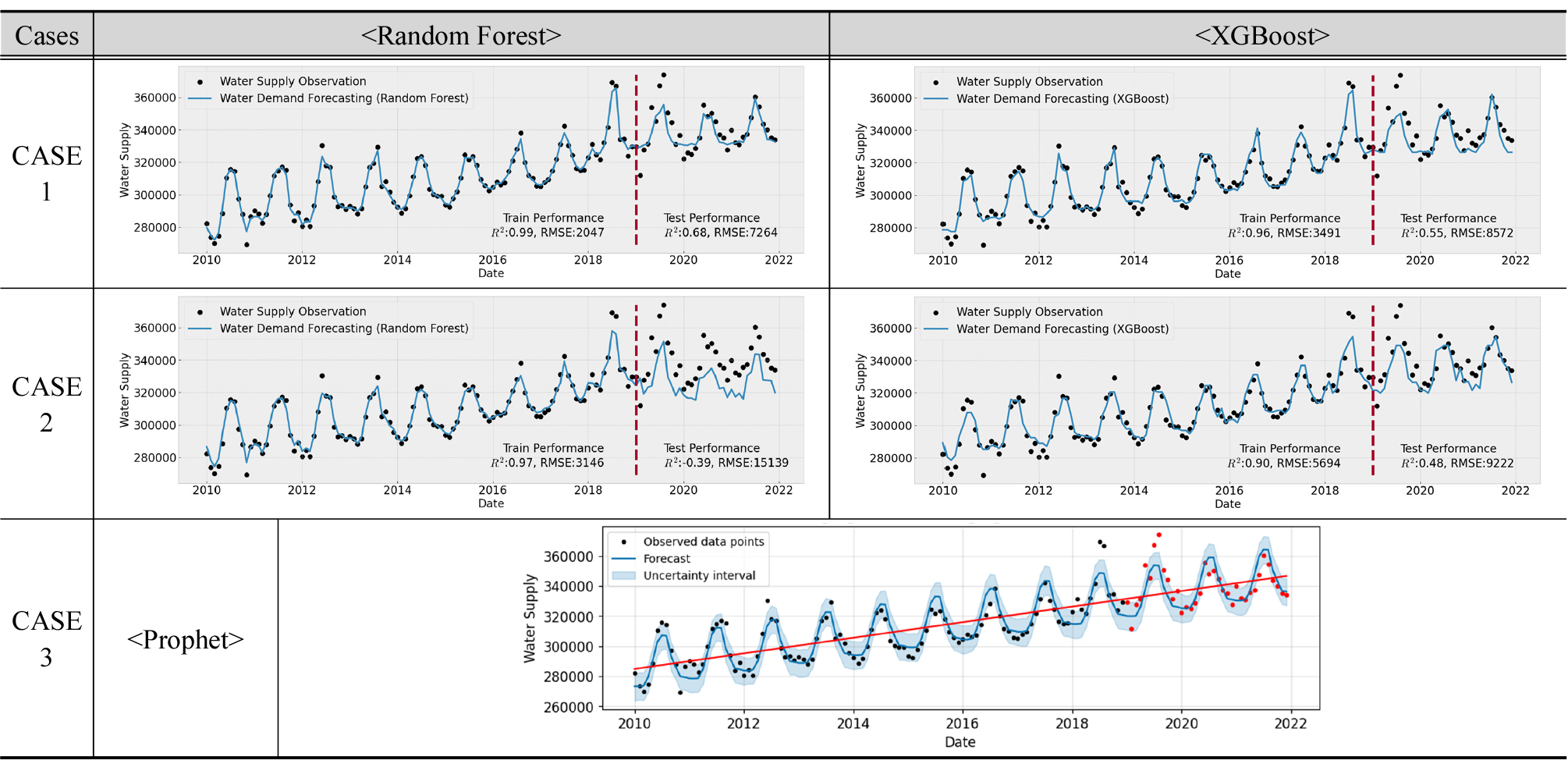
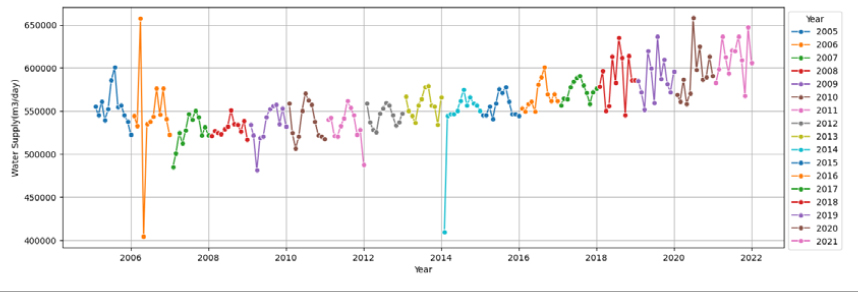
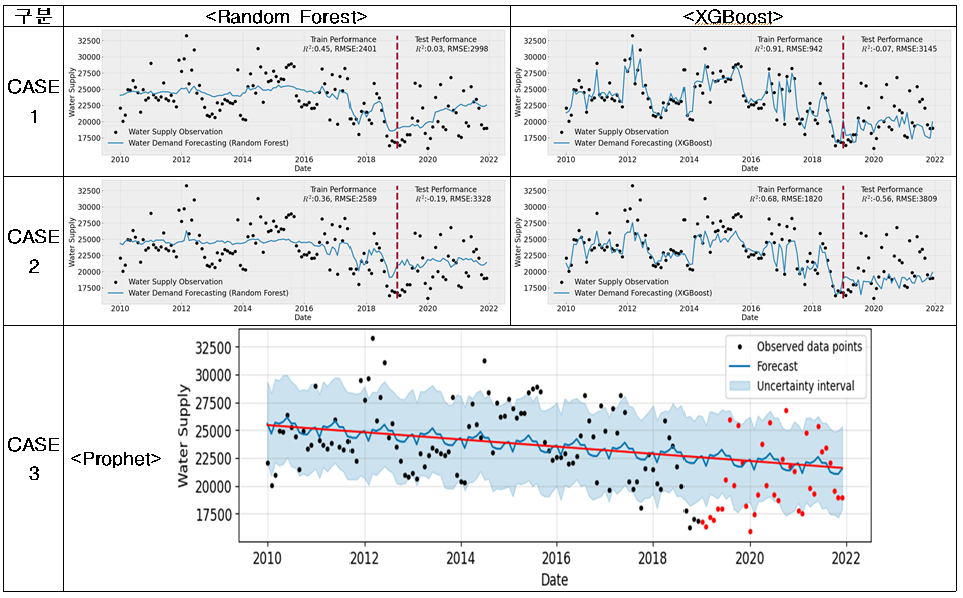
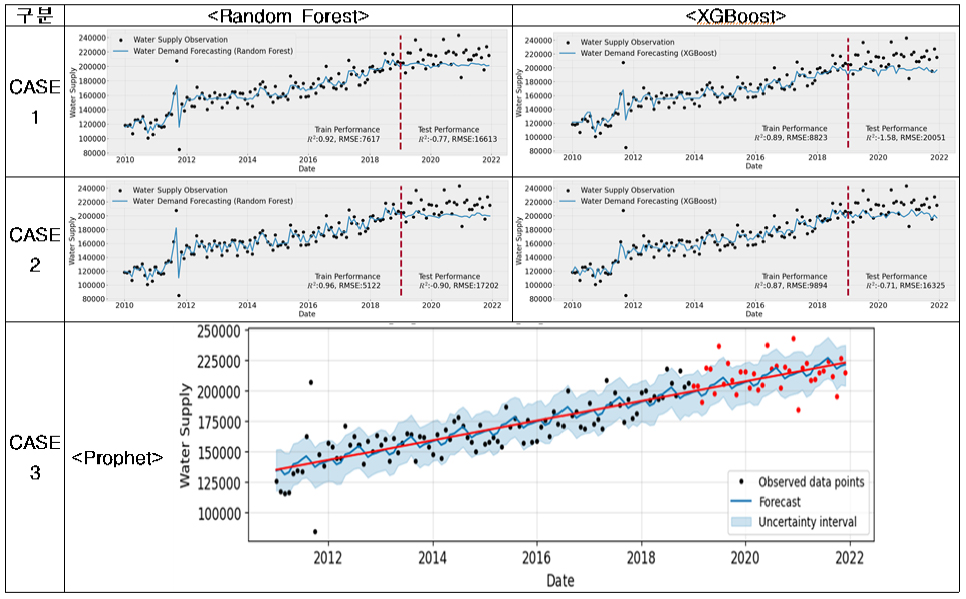
(2) 과천시의 경우, 용수공급 데이터가 월별 계절정의 파악과 년별 트랜드의 파악이 모두 어려웠다(Appendix 1). 이러한 경우, 대부분의 데이터는 어떠한 원인으로 이렇게 변동되었는지 파악하기가 힘들고 데이터의 수가 많지 않아 임의로 전처리를 하는 것 또한 어려우므로 데이터 자체를 참값으로 생각하고 용수수요 추정을 위한 적정한 모델을 찾을 수 있는지를 검토하였다. 미래 용수수요 추정방법의 평가결과(Fig. 3)는 학습에서 XGBoost의 경우, 모델의 학습(CASE-1: R2= 0.97, CASE-2: 0.90)이 가능하였으나 테스트(CASE-1: R2= -0.17, CASE-2: -0.02)에서 성능이 많이 떨어짐을 확인할 수 있었다. RMSEPE도 다른 시도에 비해서 크게 나타났다. 이는 머신러닝 방법이 학습시에는 데이터의 계절성과 트랜드가 없어도 모델의 학습이 가능하지만 모델이 일반화가 되지 않으므로 테스트시에 성능이 급격하게 떨어짐을 알 수 있었고, 이는 데이터의 한계로 적합한 모델을 찾을 수 없음을 알 수 있었다.
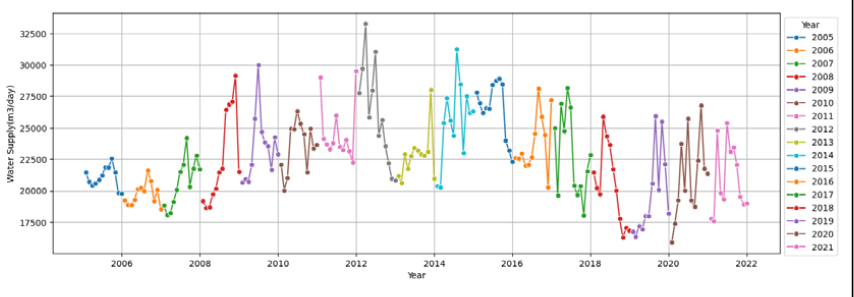
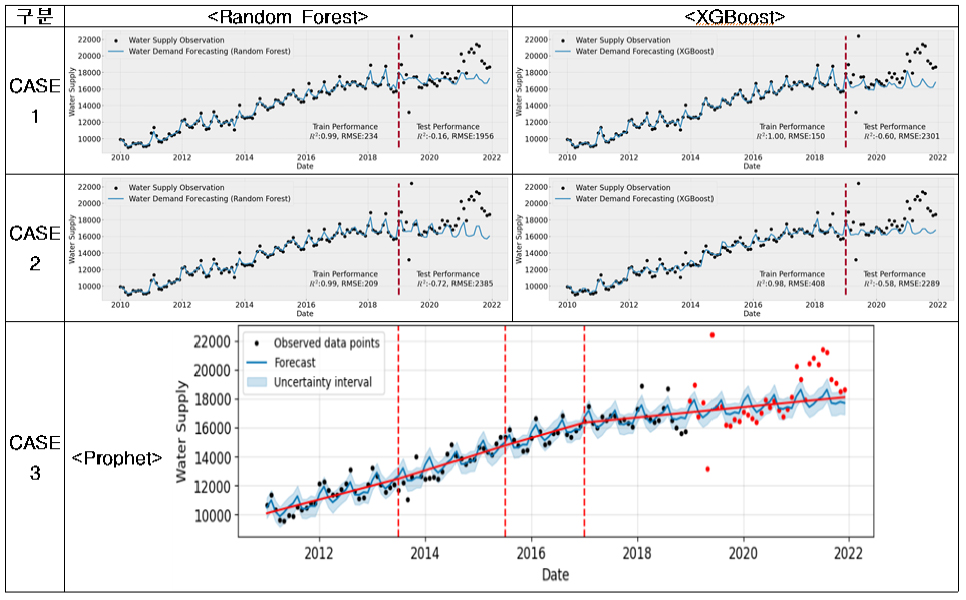
(3) 광양시의 경우, 용수공급 데이터가 계절성은 잘 나타내고 있으나 년별 트랜드를 매우 불규칙하게 나타내고 있다(Appendix 1). 특히, 테스트 기간인 2020년 1월 데이터가 2019년 12월 데이터와 큰 격차가 있고 여름까지 다른 년도에 비하여 공급량이 매우 작고 계절성도 매우 약하여 성능에 많은 영향을 준 것으로 판단이 된다. 따라서, 학습시 R2와 RMSEPE는 고양시와 비슷한 수준(R2=0.85~1.00, RMSEPE=0.42~ 2.46)으로 나타나고 RMSE (=1,098~6,514)는 다소 크게 나타났으나, 테스트시는 고양시에 비해서 모든 성능이 떨어짐(R2=0.25~0.34, RMSE=12,757~13,536, RMSEPE=4.70~ 5.19)을 확인할 수 있었다. 광양시는 테스트 기간의 데이터가 불안정하여 향후 데이터를 좀 더 확보한다면 현재 적용한 모델이 적합한지 여부를 좀 더 정확하게 판단할 수 있을 것으로 생각된다.
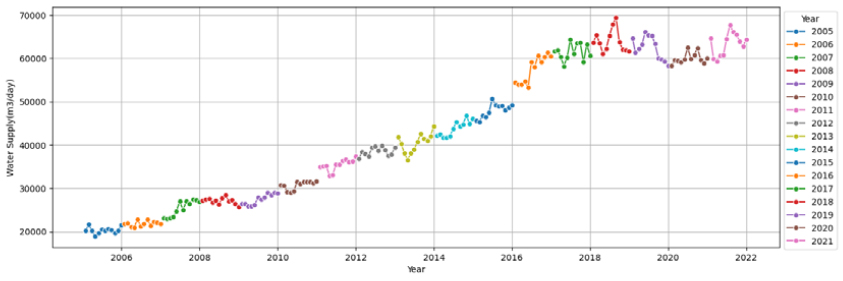
(4) 광주시의 경우, 용수공급 데이터가 계절성은 없으나 년별 트랜드는 잘 나타내고 있다(Appendix1). 하지만 2012년과 2021년에 데이터의 변동폭이 매우 크게 나타나 모델의 학습에 많은 영향을 미쳐 학습시에 RMSE와 RMSEPE가 매우 크게 나타나고(RMSE=5,122~13,105, RMSEPE=3.95~9.38), 테스트시에도 성능이 매우 크게 떨어짐(R2=-1.58~-0.09, RMSE =13,041~20,051, RMSEPE=6.08~8.94)을 알 수 있었다. 광주시는 현재 데이터의 특성상 월별 용수수요를 예측하기는 힘들 것으로 판단되고 월별 용수공급 데이터를 합하여 년도별 용수수요 예측모델을 만든다면 의미있는 결과가 나올 수 있을 것으로 판단되었다.
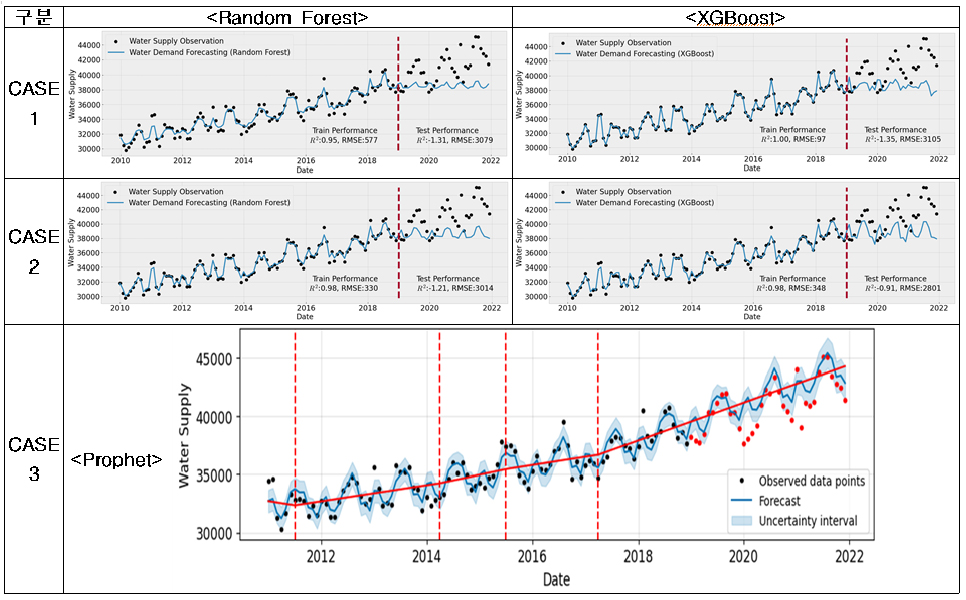
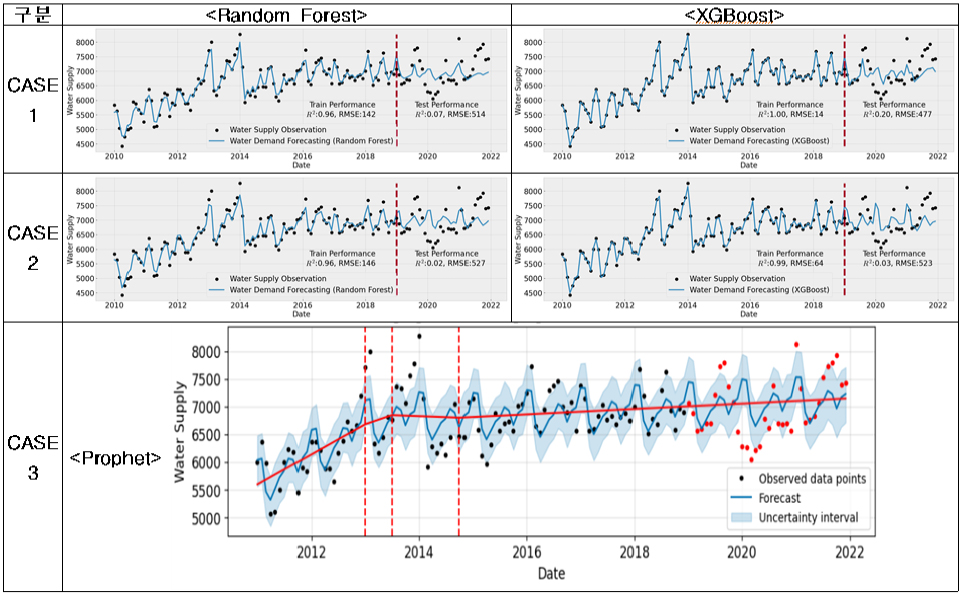
(5) 논산시의 경우, 용수공급 데이터가 계절성은 나타내고 있으나 년별 트랜드가 2008년까지 급격히 감소하다가 2009년부터 급격히 증가하는 추세를 보이고 있어 증가추세를 보이는 데이터의 학습기간이 짧은 단점이 있었다. 이러한 부분이 영향변수를 이용하여 학습하는 Random Forest와 XGBoost에 영향을 주어 학습은 양호(R2=0.95~1.00, RMSE=97~577, RMSEPE=0.28~1.68)하게 잘 되었으나 테스트 성능을 많이 떨어뜨린 원인(R2=-1.35~-0.91, RMSE=2,801~3,105, RMSEPE =6.60~7.27)이 되었을 것으로 판단된다. 하지만 영향변수를 사용하지 않는 Prophet의 경우, 2009년이후 지속적으로 증가하고 월별 유사한 용수공급분포로 인해 다른 미래용수 추정방법에 비해서 테스트시(R2=0.49, RMSE=1,450, RMSEPE= 3.70) 성능이 양호하게 나온 것으로 판단된다.
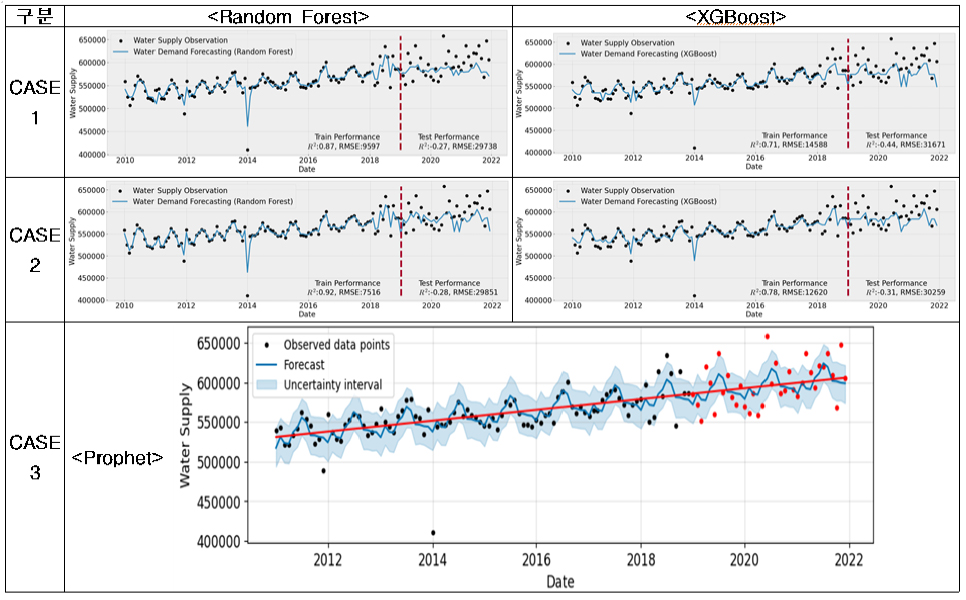
(6) 대전시의 경우, 용수공급 데이터가 2006년과 2014년에 이상치가 있으며, 2017년까지는 계절적 특성을 가지고 서서히 증가하고 있으나 2018년이후로 계절적 특성 없이 매우 불규칙적으로 증가하는 경향을 보이고 있다. 따라서 과천시, 광주시, 논산시와 유사하게 모델의 학습(R2=0.54~0.92, RMSE =7516~18,267, RMSEPE=1.59~3.91)은 가능하지만 모델의 일반화가 되지 않아 테스트시(R2=-0.44~0.23, RMSE= 23,127~31,671, RMSEPE=3.81~5.13) 성능이 크게 저하됨을 확인할 수 있었다.
(7) 음성군, (8) 장수군, (10) 횡성군의 경우, 용수공급 데이터가 계절적 특성이 없으며, 음성군의 경우 2017년까지 트랜드를 가지고 증가하였으나, 2018년부터 불규칙한 트랜드를 보이고 있고, 장수군의 경우 트랜드가 거의 나타나지 않고, 횡성군의 경우 테스트 기간의 데이터의 불규칙성이 심하게 나타나고 있다. 또한 각 년도별 데이터의 단절이나 단차가 크게 나타나 데이터의 품질도 낮은 것으로 판단된다. 따라서, 음성군, 장수군과 횡성군은 적정 모델의 선정이 어려운 것으로 판단되었다.
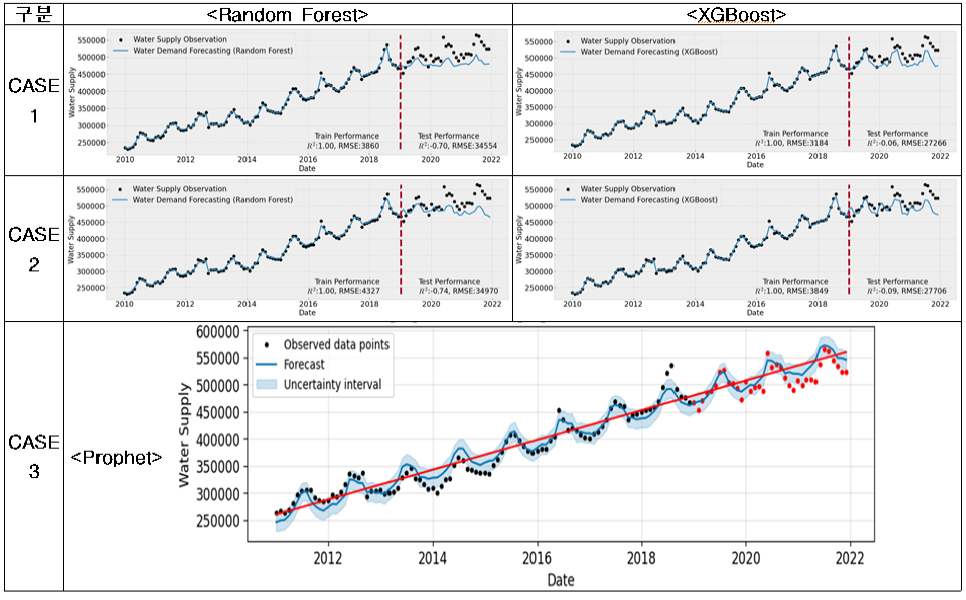
(9) 화성시의 경우, 용수공급 데이터가 약하게 계절적 특성을 보이고 있으며, 명확한 트랜드를 보이며 증가하고 있어 데이터의 품질이 타 시군에 비해서 양호하다고 할 수 있다. 하지만 CASE-1과 2의 용수수요추정모델이 테스트기간 용수수요를 다소 과소추정하여 테스트시 성능이 크게 저하되었다. 하지만 영향변수를 사용하지 않는 Prophet의 경우, 지속적으로 증가하고 월별 유사한 용수공급분포로 인해 다른 미래용수 추정방법에 비해서 테스트시 RMSE (=15,885)와 RMSEPE (=3.13)는 크게 나왔지만 R2(=0.64)는 양호하게 나온 것으로 판단된다.
시군별로 용수수요 추정모델의 선정결과를 요약하면, 고양시와 광양시는 타시군에 비해서 데이터의 품질이 양호하여 CASE-1, 2, 3 모두 이용가능한 수준의 성능을 보였다. 하지만 여전히 에러를 나타내는 RMSE와 RMSEPE는 크게 나타남을 확인할 수 있었다. 그 외 논산시와 화성시는 영향변수를 사용하지 않고 단변량예측으로 Prophet을 활용한 CASE-3가 성능이 양호하게 나타났다. 고양시를 제외한 대부분의 시군 데이터에서는 정도의 차이는 있지만 ① 계절성, ② 트랜드가 부재하고, ③ 월별 데이터간 연속성이 없이 갑작스럽게 변화하고 ④ 특히 테스트 기간동안 월별 변동성이 없어지거나 갑작스럽게 변동성이 커지는 데이터로 인하여 용수수요 추정에 적합한 모델을 찾기가 어려웠다고 판단된다. 따라서, 향후 월별 변동성을 고려한 용수수요 추정모델의 개발을 위해서는 데이터의 품질관리에 대한 노력이 필요할 것으로 판단된다.
4. 결 론
본 연구에서는 기존의 연단위 용수수요추정방법이 고려하지 못하는 월별 용수공급 변동성으로 인한 향후 물부족에 미치는 영향을 분석하기 위하여 월단위 용수수요예측을 위한 적합한 용수수요 추정방법을 연구하였다. 먼저 기존의 용수수요추정 연구의 조사를 통한 다양한 영향변수를 조사하여 22개의 수집가능한 영향변수를 수집하였고, 22개의 영향변수는 용수수요 추정모델의 개발시 과적합의 우려가 있을 수 있으므로 변수선정방법 적용하여 영향력이 큰 영향변수를 선정하여 모델의 입력자료로 활용함으로써 용수수요 예측시 변동성을 최소화하여 모델의 신뢰도를 향상시키고자 하였다. 하지만 첫 번째로 대부분 시군 데이터의 계절성과 트랜드 부재, 월별 데이터간 연속성이 없이 갑작스럽게 변화하거나 테스트 기간동안 월별 변동성이 없어지거나 갑작스럽게 변동성이 커지는 등의 다양한 품질문제로 인하여 적합한 모델의 학습과 테스트를 수행하기 어려운 한계가 있었다. 뿐만 아니라, 기존의 연구와 같이 가정단위나 소규모 아파트 단지 등의 특정지역에 대한 연구가 아닌 시군단위의 넓은 공간적 범위와 월단위 용수공급자료, 그리고 개발도상국과 같이 급속히 인구가 증가하고 발전하는 도시가 아닌 어느 정도 개발이 완료된 도시의 특성으로 인하여 통계적으로 유의미하였으나, 미래 용수수요 변화에 영향력이 큰 변수를 찾기 힘들다는 한계가 존재함을 확인할 수 있었다.
본 연구를 통해서 향후 용수수요 추정모델의 정확도를 개선하기 위해서는 먼저 1) 시군별 용수공급량에 대한 데이터 풀질관리가 필요하다. 기관별 데이터를 수집하여 시군별 용수공급량에 대한 통계발간시 추세와 계절적 특성을 고려하여 데이터의 품질을 확인하고, 다양한 이벤트(K-water-지자체간 계약변경, 다양한 지자체 행사 등)에 대한 이력을 관리함으로서 향후 신뢰성있는 용수수요 추정이 가능하도록 해야 할 것이다. 또한, 현재는 생활용수와 공업용수가 구분되지 않아 공급특성이 다른 두 용수가 함께 분석됨에 따라 신뢰도있는 용수수요 추정모델의 개발에 한계가 있었다고 판단된다. 앞으로 생활용수와 공업용수를 구분하여 데이터 관리가 가능하다면 좀 더 신뢰도 있는 분석이 가능할 것으로 판단된다. 2) 다음으로는 좀 더 신뢰도 있고, 인과관계의 추론(Runge et al., 2019)이 가능한 변수선정방법의 적용이 필요하다. 이를 통해서 단순히 상관관계가 높은 영향변수를 선정하는 것이 아니고 인과관계가 있는 영향변수를 선정함으로써 좀 더 신뢰도 높은 영향변수의 선정이 가능할 것으로 생각된다. 마지막으로 3) 금번 연구는 영향변수의 영향력이 크지 않아 오히려 단변량 방법을 통한 용수수요 추정방법이 더 적합한 것으로 판단되었다. 하지만 이러한 단변량 방법들은 일정한 트랜드를 가지고 지속적으로 증가 또는 감소함에 따라서 단기간의 용수수요추정에는 효과적일 수 있으나 국가 물관리기본계획과 같이 장기 용수수요 추정에는 많은 오차를 발생시킬 수 있다. 따라서, 장기 용수수요 추정에서는 반드시 시군별로 영향력 있는 영향변수를 찾아서 활용하는 것이 필요하다고 하겠다. 최근 인공지능기술의 발달로 LSTM (Long Short-Term Memory), Transformer, GCRNN (Graph Convolutional Recurrent Neural Networks)과 같은 장래용수수요 추정에 적용되고 있다(VanBerlo et al., 2021; Xenochristou et al., 2020; Zanfei et al., 2022). 하지만 시군단위 용수공급량의 신뢰도와 자료기간의 한계로 여전히 신뢰도 높은 용수수요 추정모델의 개발은 쉽지 않을 것으로 판단된다. 하지만 앞으로 적은 데이터를 활용한 시계열 예측방법(Cruz-Nájera et al., 2022)과 앞에서 언급한 인과-추론을 활용한 영향력있는 영향변수의 탐색 등의 연구를 지속한다면 향후 장래 용수수요 예측에 대한 신뢰도가 더욱더 향상될 것으로 기대된다. 뿐만 아니라, 금번 연구의 분석기간은 코로나 기간(‘19.1~’21.12월)을 포함하고 있으며, 이 기간은 테스트 기간에 데이터의 변동성이 컸던 시군과 같이 타 기간의 용수수요 패턴과 상이한 특성을 보여 장래 신뢰성 있는 용수수요 추정의 성능저하에 영향을 미칠 수 있을 것으로 판단된다. 따라서, 향후 코로나 시기의 용수수요특성을 별도로 고려한다면 좀 더 신뢰할 수 있는 용수수요예측이 가능할 것으로 생각된다.