

1. 서 론
2. 방법론
2.1 RCM 일강우자료의 오차보정(Bias correction)
2.2 오차보정된 RCM일강우자료의 시간상세화
2.3 대표 지속시간별 연최대강우 선택
3. 연구대상 지점
4. 결 과
4.1 오차보정(Bias correction)
4.2 시간상세화(Temporal downscaling)
4.3 지속시간별 연최대강우 대표시나리오 (Representative scenarios of AMP)
4.4 지속시간별 미래 연최대강수량 결과
5. 결 론
1. 서 론
기후변화가 홍수의 가장 큰 원인이 되는 극치강우에 매우 큰 영향을 미치고 있다는 것이 연구를 통해 증명되어지고 있다(van Pelt et al., 2012; Déqué, 2007). 전지구모델(Global Circulation Model, GCM)을 통하여 생산된 시나리오는 기후변화가 주는 다양한 분야의 영향을 분석하는 도구가 되고 있다(Cohen et al., 2000; Chen et al., 2006; Fowler et al., 2007). 그러나 GCM이나 동역학적 상세화를 통한 지역상세화 모델(Regional Climate Model, RCM) 자료들을 우리나라 대부분의 중소규모, 도시유역에 적용하기에는 단점들이 존재하는데, 이는 GCM 또는 RCM 결과들이 실제 관측결과와 상이하게 다른 오차를 가지고 있는 것(Hansen et al., 2006; Sharma et al., 2007; Hagemann et al., 2011)과 대부분 일강수량만을 제공하여 몇 시간 내에 유출이 일어나는 우리나라 대부분의 유역에 자료의 시간적 해상도가 너무 낮다는 것이다(Krajewski et al., 1991; Lee and Jeong, 2014). 이를 위해 상세화를 다양한 통계학적 상세화 방법이 개발되어져왔다.
가장 널리 쓰이는 통계적 상세화 기법인 기후발생기(weather generator)는 일 단위의 자료를 만들어 낼 수 있기 때문에 일 단위 수문기상변수의 시계열 모의를 위해 많이 사용되어왔다(Boe et al., 2007; Lee et al., 2012). 또한, 시계열 강수자료의 통계적 시간 상세화를 위하여 point-process 모델에 기반을 둔 방법 등의 여러 접근방법이 제안되었다(Koutsoyiannis and Onof, 2001; Marani and Zanetti, 2007).
Kumara (2012)는 GCM자료를 지점의 수문기상 관측치와 연계하여 특정지점의 월 단위 기상변수들을 변수간의 일관된 상관관계를 유지하면서 일 단위로 상세화 하였다. Wang and Liu (2006)는 임의분포방법을 통해 상세화 하였으나 강우강도가 상대적으로 클 경우 이 방법은 강우량을 과대평가하는 경향이 있음을 보고한 바 있다. Chen et al. (2012)은 일일 강수량을 4개의 기간으로 분할하고 비례적으로 분포하는 방법을 제시한 바 있다. 그러나 이러한 기존의 상세화 모델들은 평균, 표준편차, 왜곡도 및 Lag-1 상관관계 등 주요 시간 주기의 통계치의 구체적인 세부사항을 고려하지 않았다.
Lee and Jeong (2014)은 시간단위의 통계학적 특성과 하루 동안의 시간별 통계적 패턴을 재현해 내는 비모수적 상세화 기법 모델을 개발하였다. 이후 Lee and Park (2017)에서는 지속시간에 대한 관측치 극치강수량의 통계학적 특성을 잘 모의할 수 있는 시간상세화기법을 개발하였다.
따라서 본 연구에서는 기존의 시간적 상세화의 문제점을 개선한 Lee and Park (2017)을 기준으로 기후변화 시나리오의 오차보정, 시간적 상세화, 그리고 대표 자료 선택을 통해 우리나라 전역에 대하여 각 지점의 특성에 따라 시간적으로 상세화 하여 미래 시나리오에 대한 기준이 되는 하나의 지속시간별 연최대강우자료를 제공하는 것을 목표로 하고 있다.
2. 방법론
기본적으로 본 연구에서는 GCM자료가 아닌 RCM강우자료를 사용하였으며 구체적인 자료에 대한 설명은 다음 장에 기술하였다. 취득된 RCM 일 강우자료로부터 지속시간별 연최대강우자료를 생산하기 위해서는 여러 절차를 거치게 되는데 본 연구에서 사용된 절차가 Fig. 1에 나타나있으며 이는 다음의 순서로 요약된다.
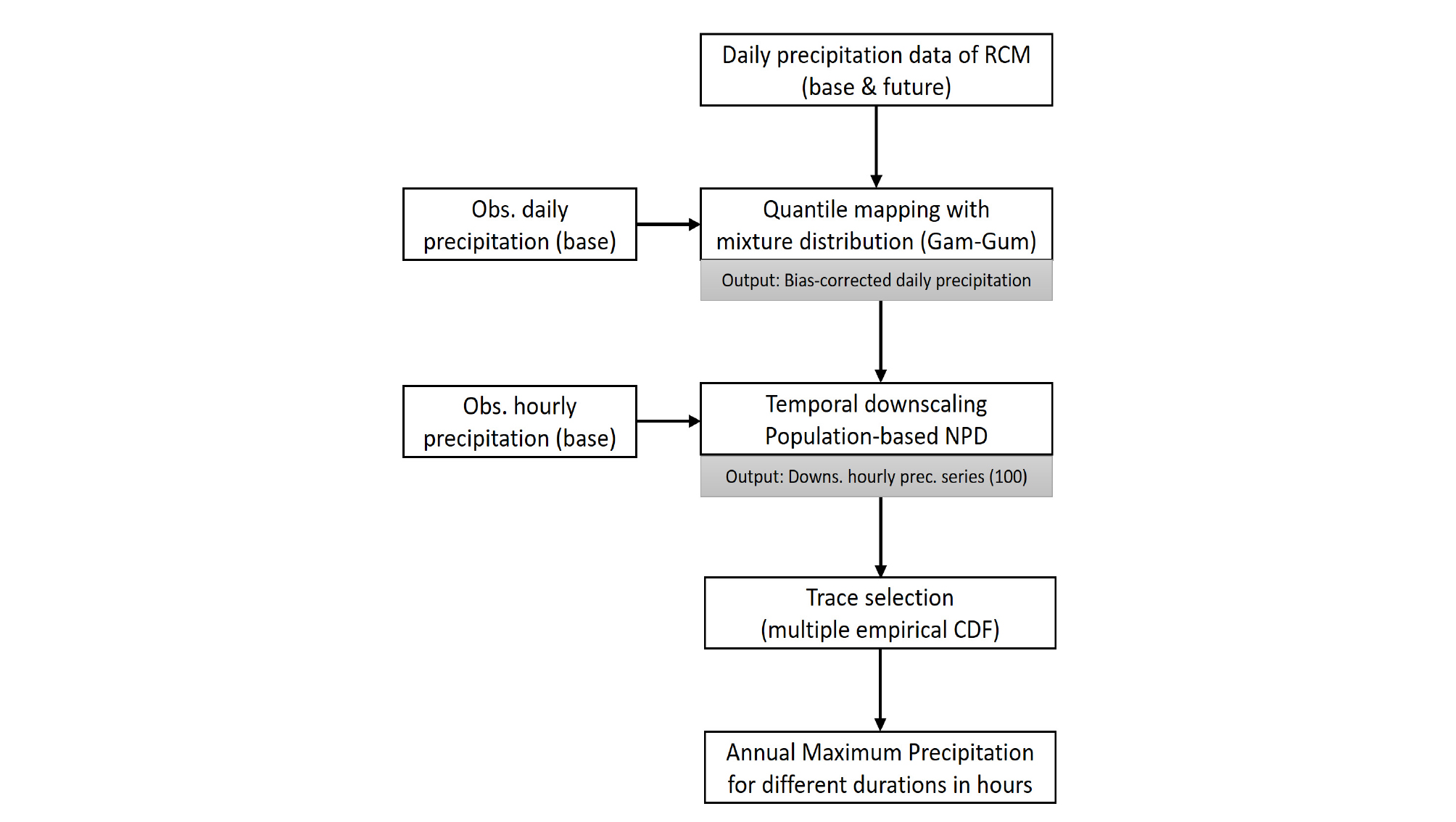
(1) RCM 및 관측 일강우자료의 취득
(2) 관측 일강우자료를 바탕으로 기준기간 및 미래기간 RCM 일강우자료에 대한 오차보정(Bias-correction)
(3) 시간상세화 모형을 통한 Bias-corrected된 일강우자료의 시강우시나리오 생성
(4) 생성된 여러 미래 시강우자료들에서 지속시간별 연최대강우량 계산 및 대표 지속시간별 연최대 강우자료 선택
2.1 RCM 일강우자료의 오차보정(Bias correction)
기후모델에서 모의된 강수량 값은 관측치와는 상당한 차이를 보이고 있는데 이를 보정없이 쓸 경우 지역적인 영향을 고려하지 못해 상당히 큰 차이를 보이게 된다. 이를 해결하기 위해 델타기법(Lettenmaier et al., 1999), 다중선형회귀(Alexandrov and Hoogenboom, 2000; Kilsby et al., 1998), Quantile mapping (Panofsky and Brier, 1968; Themeßl et al., 2011)등 여러 보정방법들이 사용되어져 왔다. 현재에는 Quantile Mapping (QM)방법을 가장 많이 사용하고 있다(Shin et al., 2018). 만일 기후모델 일강우자료(x)를 QM으로 보정하는 값(y)으로 보정하게 되면:
| $$y=F_{obs}^{-1}\left(F_{RCM}\left(x\right)\right)$$ | (1) |
여기서, F는 특정 누적분포함수(Cumulative Distribution Function)를 의미하며 FRCM과 Fobs는 각각 RCM과 관측치에 적용한 누적분포함수를 의미한다. 일반적으로 Gamma, Exponential분포형들을 주로 사용하였는데 연구를 통해 우리나라에는 혼합분포형이 적절함을 밝혀냈다(Shin et al., 2018). 특히 일반적인 강우에 사용되는 Gamma분포형과 우리나라 극치강우 분석에 사용되는 Gumbel분포형을 적절하게 혼합한 혼합분포형이 실제 관측자료의 통계형태를 잘 반영하는 것으로 확인되었다. 이 혼합분포형의 확률밀도함수(f)는 다음과 같다.
여기서, 𝛼, 𝛽는 각각 Gamma분포(fGam)의 규모 및 형상 매개변수이며 𝛼U, 𝛽U는 각각 Gumbel(또는 Extreme Value 1, EV1; fGum) 분포의 규모 및 위치 매개변수이다.
2.2 오차보정된 RCM일강우자료의 시간상세화
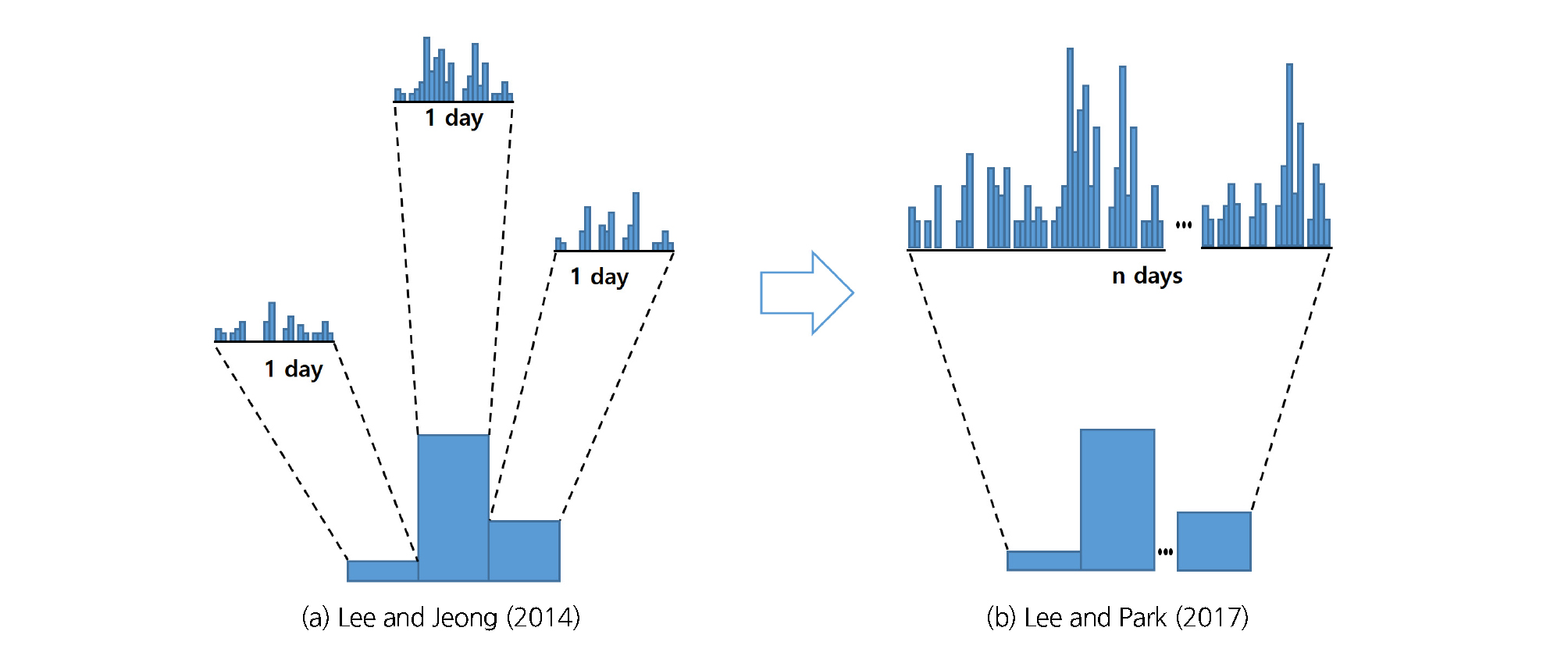
RCM 일강우자료로부터 특정지점의 관측자료를 바탕으로 오차를 보정하고 보정된 일강우자료를 가지고 시간자료로 상세화하게된다. 상세화 기법은 Lee and Jeong (2014)이 개발한 비매개변수시간상세화 기법을 바탕으로 하였다. Lee and Jeong (2014)은 유전자알고리즘과 K-최근법(K-Nearest Neighbor)을 바탕으로 비매개변수를 이용한 추계학적 시간상세화 기법을 개발하였다. 이 방법은 단일강우를 상세화함으로써 연결성이 결여되어 지속시간별 연최대강우량이 과소산정되는 단점을 보여주었다. 이는 수공구조물 설계시 과소설계되는 결과를 낳게된다. 이를 보완하기 위해 Lee and Park (2017)은 상세화에 앞서 다양한 긴지속 일강우(2일~15일)를 먼저 발생가능한 모든 형태의 강우(Population)로 생성해 놓고 이 강우에서 Lee and Jeong (2014)의 상세화를 적용하였다. 상세화 과정은 다음과 같이 요약된다.
일 단위 변수를 yi, 시간 단위 변수는 Xi=[Xi, 1, Xi, 2, …, Xi, 24]=[Xi, h]h∈1, 24일 때 i=1, …, n이고 이때 n은 자료의 길이이고 h는 시간을 의미한다. 그리고 Yt는 상세화 대상의 강수량의 값이고, t=1, …, T 여기서 T는 대상 일 강수량의 길이이다. 일 단위 시계열 Yt를 시간 단위 시계열 Xt=[Xt, 1, Xt, 2, …, Xt, 24]로 상세화 하는 것이 목적이다. k를 안다고 했을 때 상세화 기법을 적용하는 순서는 다음과 같다.
Step 1. 대상 일 강우량 Yt와 모집단에서의 일 강우량의 거리를 계산한다. 이때,
| $$D_i=\left(Y_t-y_i\right)^2,\;i=1,\;\cdots,\;n$$ | (3) |
Step 2. Step 1으로부터 나온 값을 오름차순으로 정리 한 다음 k번째까지 최소거리를 가지는 시간 인덱스를 저장한다.
Step 3. k시간 인덱스들 중 하나에 임의로 가중확률을 준다.
| $$W_m=\frac{1/m}{{\displaystyle\sum_{j=1}^k}1/j},\;m=1,\;\cdots,\;k$$ | (4) |
Step 4. Step 3의 가중확률을 가지고 시간인덱스 k개 중에서 하나를 선택하고, 해당시간의 일 자료에 대응하는 시간 단위 자료를 다음과 같이 할당한다.() 여기서 선택된 시간 인덱스가 p임을 가정한다.
Step 5. 유전 알고리즘 혼합과정은 다음과 같다.
(Step 5-1) 재생 : Step 1-4단계를 사용하여 하나의 부가적인 시간 인덱스를 추가로 선택하고 p*로 이 인덱스를 나타낸다.
(Step 5-2) 교차 : xp, h의 각 요소를 xp*, h로 확률 Pc에 따라 교체한다. 즉,
| $$X_{t,\;h}^\ast=\left\{\begin{array}{l}x_{p\ast,\;h}\;if\;\in<P_c\\x_{p,\;h}\;otherwise\end{array}\right.$$ |
여기서, 𝜖은 0과 1사이에 균일하게 분포된 난수이다.
(Step 5-3) 변이 : 모든 관측치의 동일 시간 값 중 하나를 택하여 (i=1)확률 Pm에 따라 교체 한다.
| $$X_{t,\;h}^\ast=\left\{\begin{array}{l}x_{\xi,\;h}\;if\;\in<P_m\\x_{p,\;h}\;otherwise\end{array}\right.$$ |
Step 6. 합산식 조건을 만족하기 위해 다음과 같이 상세화 된 값을 조정한다.
| $$X_{t,\;h}=\frac{X_{t,\;h}^\ast}{{\displaystyle\sum_{j=1}^{24}}X^{\ast t,\;j}}$$ | (5) |
Step 7. 필요한 자료가 만들어 질 때 까지 과정(Step 1-6)를 반복한다.
이에 대한 개념적인 설명이 Fig. 2에 보여 진다. 시간상세화에 대한 구체적인 설명은 참고문헌(Lee and Jeong, 2014; Lee and Park, 2017)을 보면 보다 자세한 내용을 알 수 있다. 최종적으로 하나의 기준기간(base: 1979~2005) 및 미래기간(future: 2006~2100) 일강우자료에 대해 100회의 시뮬레이션을 실시하여 100개의 시간자료가 생성된다.
2.3 대표 지속시간별 연최대강우 선택
앞 2.2절에서 언급하였다시피 100개의 시간상세화된 자료를 바탕으로 지속시간별 연최대강우자료를 생성하게된다. 미래의 지속시간별 연최대강우자료를 생성하는데 가장 좋은 방법은 100개의 모든 시나리오를 분석하고 앙상블 형태로 결과를 제공하는 것이 타당하나, 현업에서 사용시 분석이나 적용에서 다양한 문제점을 야기할 수 있다. 따라서, 연구를 통하여 여러 개의 시나리오 중 가장 적절한 단일 시나리오를 선택하는 방법을 개발하여 적용하였다. 개발된 방법은 Trace Selection Method (TSM)이며 3가지의 방법이 제안되었다(Lee et al., 2018). TSM은 적절한 목적함수(obj)를 바탕으로 여러 개의 시간상세화 시리즈 중에서 하나의 시리즈를 선택하는 것이다. 이중에서 가장 간단한 방법은 전체 시나리오들의 평균과 표준편차를 이용하는 것이며 이를 식으로 표현하면 다음과 같다.
| $$obj=min\left\{\left(\mu_i^{AMP}-\overline{\mu^{AMP}}\right)^2+\left(\sigma_i^{AMP}-\overline{\sigma^{AMP}}\right)^2\right\}$$ | (6) |
여기서, 는 각 시리즈의 연최대치(Annual Maximum Precipitation; AMP) 평균 및 분산, 와 는 모든 시나리오 연최대치의 평균 및 분산을 의미한다. 더 나아가 밀도추정치와 경험적누적분포함수를 통해서도 산정하였다. 밀도추정치를 통한 선택방법을 식으로 나타내면 다음과 같다.
| $$obj=min\left\{\sum_{m=1}^M\left[\theta\left(f_m\right)-{\widehat f}_g\left(x_m\right)\right]^2\right\}$$ | (7) |
여기서 은 xm에 대한 g번째 시나리오 자료에 대한 추정밀도함수이며 은 전체 값의 중앙값을 의미한다. 여기서, 추정밀도함수는 표준정규분포를 핵 함수로 하는 핵밀도함수를 사용하였다.
마지막으로 경험적누적 분포함수를 사용하였고 이를 식으로 나타내면
| $$obj=min\left\{\sum_{t=1}^T\left[\theta\left(x_{(t)}\right)-x_{(t)}^g\right]^2\right\}$$ | (8) |
여기서는 g번째 시나리오의 오르막 차순으로 정렬된 t 번째 값을 의미하며 는 정렬된 자료의 전체 시리즈 중의 t번째 값에 대한 중앙치로 설정된다.
이 세가지의 목적함수를 통하여 각각 시나리오를 추출하고 이를 반복하여 추출된 시나리오의 통계학적 특성이 가장 적합한 방법(예, Root Mean Square Error; RMSE)을 선택하였다.
3. 연구대상 지점
연구에서 대상 관측자료는 비교적 신뢰성이 확보되어 있는 기상청(KMA)에서 제공하고 있는 강우자료를 이용하였으며 기상청 강우관측소 중 30년 이상의 관측자료를 보유하고 있는 60개 지점을 선정하였으며 Fig. 3에서 해당 지점들을 보여준다. 선정된 강우관측소의 과거자료를 기반으로 제시한 상세화 작업을 수행하였다.
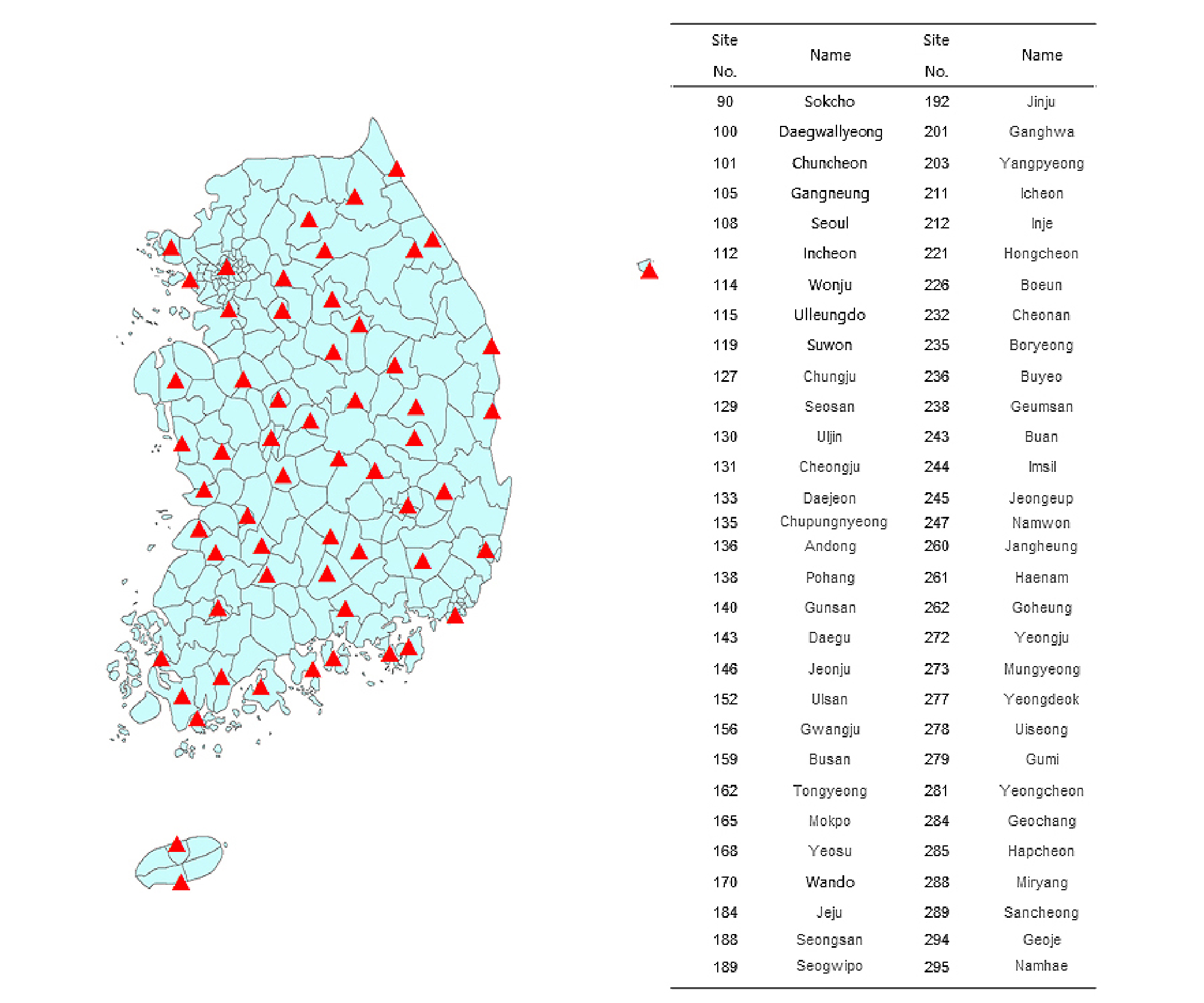
사용된 시나리오자료는 기상청에서 제공하는 RCM (Regional Climate Model)의 RCP (Represenative Concentration Pathway)를 사용하였다. 여러 시나리오를 적용하였으나 본 연구에서는 RCP8.5 시나리오를 기준으로 설명하였다. 이 자료는 영국의 Met Office Hadley Center에서 제공된 HadGEM2-AO자료를 기반으로 우리나라 기상청의 National Institute of Meteorological Research (NIMR)에서 지역기후모델인 Had GEM3-RA를 통해 역학적상세화를 시킨 자료이다(Park et al., 2013; Hwang et al., 2018). 이 자료는 다음의 링크에 잘 설명되어져 있다(http://cordex-ea.climate.go.kr/cordex/about Page.do). 기준기간은 1979~2005으로 되어 있으며 미래기간은 2006~2100까지 제공되고 있다.
4. 결 과
4.1 오차보정(Bias correction)
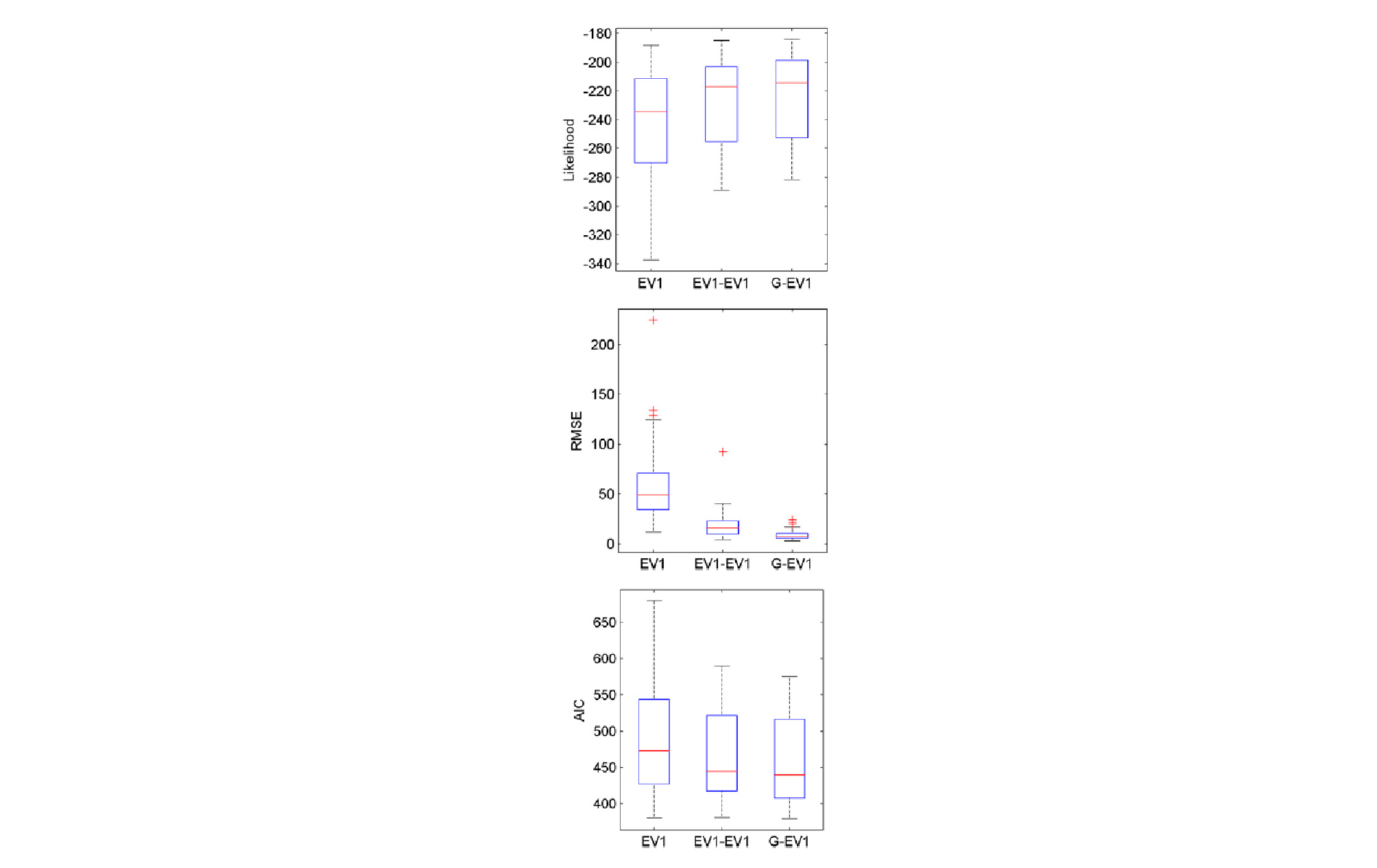
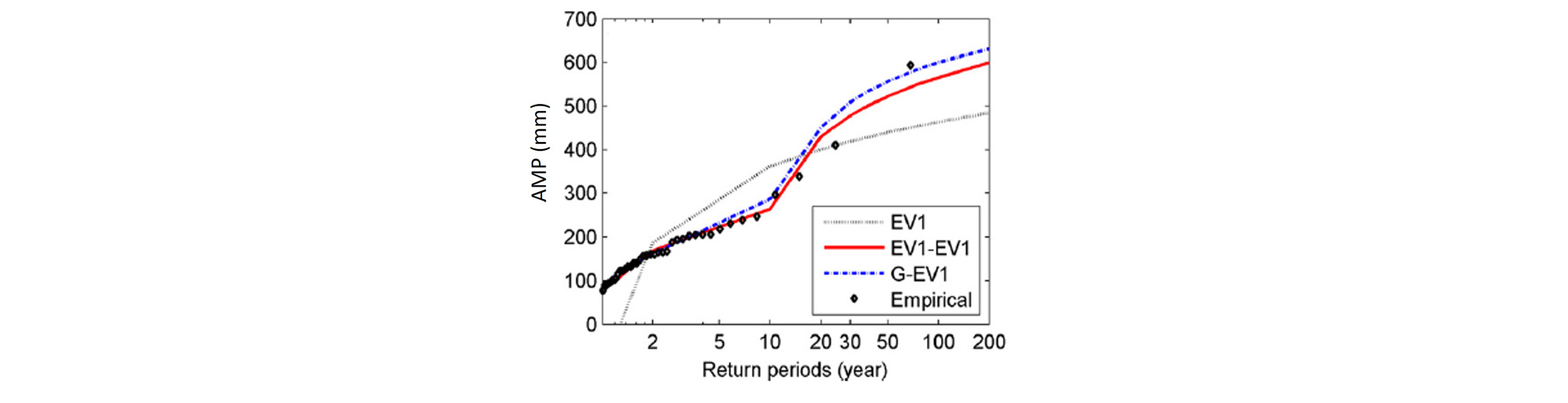
전 60개 지점에 대한 일강우량자료에 대해서 여러 단일분포형 및 혼합분포형을 조합해서 적용한 결과 Gamma-Gumbel분포형이 가장 적합한 것으로 나타났다. Fig. 4에서는 전체지점에 대해서 결과를 다양한 분석결과 나타낸 것이다. Gumbel (EV1)분포, Gumbel-Gumbel (EV1-EV1)혼합분포, Gamma-EV1 (G-EV1)분포에 대한 결과를 보여주고 있다. 우도(Likelihood)의 경우 값이 클수록, RMSE (Root mean square error)와 AIC (Akiake Information Criterion) 경우 값이 작을수록 좋은 모형임을 보여준다.
| $$RMSE=\sqrt{\frac1N\sum_{d=1}^N\left({\widehat y}_d-y_d\right)^2}$$ | (9) |
| $$AIC=2k-2\ln(L)$$ | (10) |
여기서 는 Eq. (1)을 통해 계산된 값이고 는 관측값을 의미한다. 또한 k는 분포형모델에서의 매개변수의 개수 L은 우도(Likelihood)값이다.
Fig. 4에서는 G-EV1의 값이 모든 성능척도에서 가장 적절한 모형임을 보여주고 있다. 이는 G-EV1분포형이 일반적인 강우분포를 담당하고 극치분포에 대해서는 EV1을 통해서 적정하게 모형이 적용되는 결과로 판단되어진다. 특히 Fig. 5에서와 같이 극치부분에서 다른 분포형들이 잘 따라가지 못하는 부분을 G-EV1분포형에서는 적절하게 적합화 시킴을 알 수 있다.
4.2 시간상세화(Temporal downscaling)
본 연구에서 적용된 시간상세화 모형의 경우 논문을 통하여 Lee and Park (2017)이 개발한 모형에 대해서 다양한 검증을 수행하였다. 검증을 통하여 기존의 모형이(Lee and Jeong, 2014) 가지고 있던 단점을 잘 보완하였음을 보여 주었다. Fig. 6의 박스플롯은 목포지점의 일강우 자료를 시간상세화를 통해 100개의 시간자료를 획득하고 그중에서 지속시간별 연최대강우자료의 평균값을 100개의 시나리오에 대해서 계산해서 박스플롯으로 보여주는 것이다. 관측자료의 값은 x로 연결된 선으로 표현하고 있고 이 x마커가 박스에 가까울수록 모형이 관측치의 통계치를 잘 반영하고 있다고 할 수 있다.
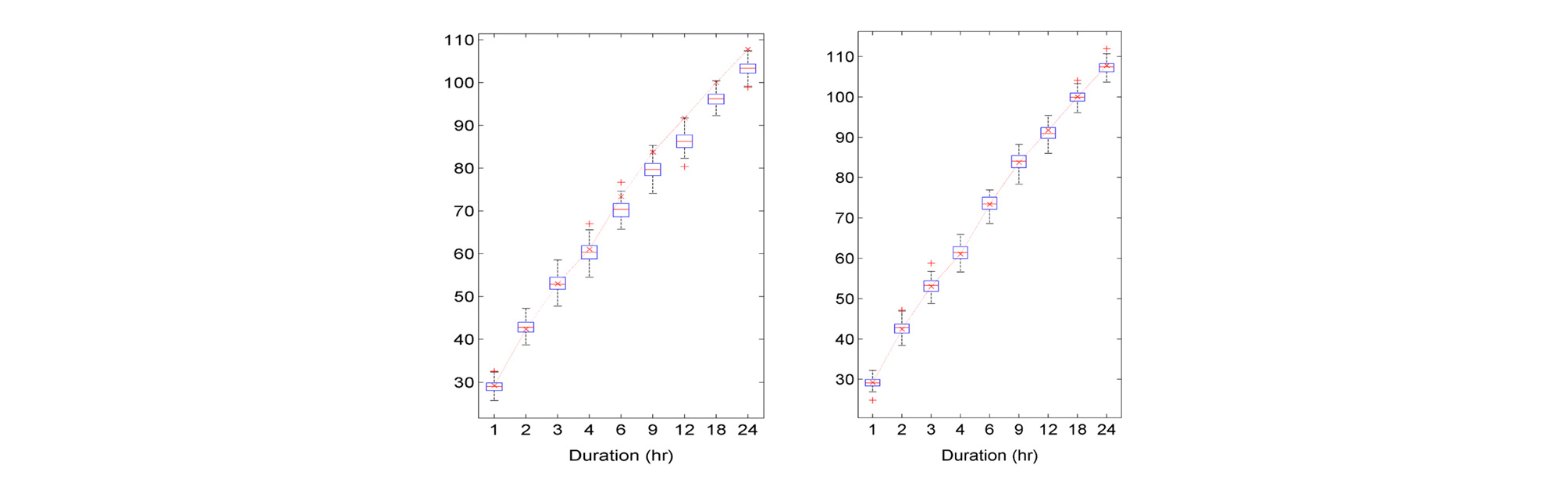
기존의 왼쪽 박스플롯에서 보는바와 같이 Lee and Jeong (2014) 모형은 일단위를 기준으로 시간자료로 상세화를 시키기 때문에 강우가 하루이상 지속되는 경우 일강우량의 연속성이 상세화된 시간단위 강우에서 사라지게 된다. 이는 지속시간별 연최대강우량을 과소추정하게되며 이는 지속시간이 길어질수록 이런 현상이 두드러지게 나타나게 된다. Fig. 6에서도 지속시간이 짧았을 경우 과소추정 현상이 나타나지 않으나 지속시간이 6시간 이후부터 상당히 크게 과소추정현상이 나타난다.
하지만 이러한 단점을 최근에 Lee and Park (2017)이 다양한 지속강우를 먼저 생성한 후 이를 기존의 비매개변수 시간상세화 방법을 적용함으로써 극복해내었다. 이런 특징은 Fig. 6의 오른쪽 그림에 잘 나타나 있는데 모든 지속시간에 대해서 관측 자료로부터 계산된 통계치(x마커)가 박스의 중앙에 위치함고 있는 것을 알 수 있다.
이렇게 관측기간 동안 검증된 모형을 미래기간에 대해서 적용하여 시간상세화를 실시하였다. Fig. 7에는 제시된 상세화 모델을 통한 목포지역의 RCP8.5 일강우 시나리오를 시간단위로 상세화하여 각 지속시간별 연최대강우량을 시계열로 도시한 것이다. 점선이 전체 100개 시리즈의 중앙값들을 표현한 것이다. 상세화된 연최대강우량이 관측치의 변동성을 잘 반영하고 있는 것으로 보여진다. 지속시간이 길어질수록 상세화된 100개 시리즈들간의 차이가 크지 않는 것은 미래일강우 자료를 기반으로 상세화 하였기 때문에 일강우가 항상 같은 조건을 만족시켜야 하므로 발생하는 현상이다.
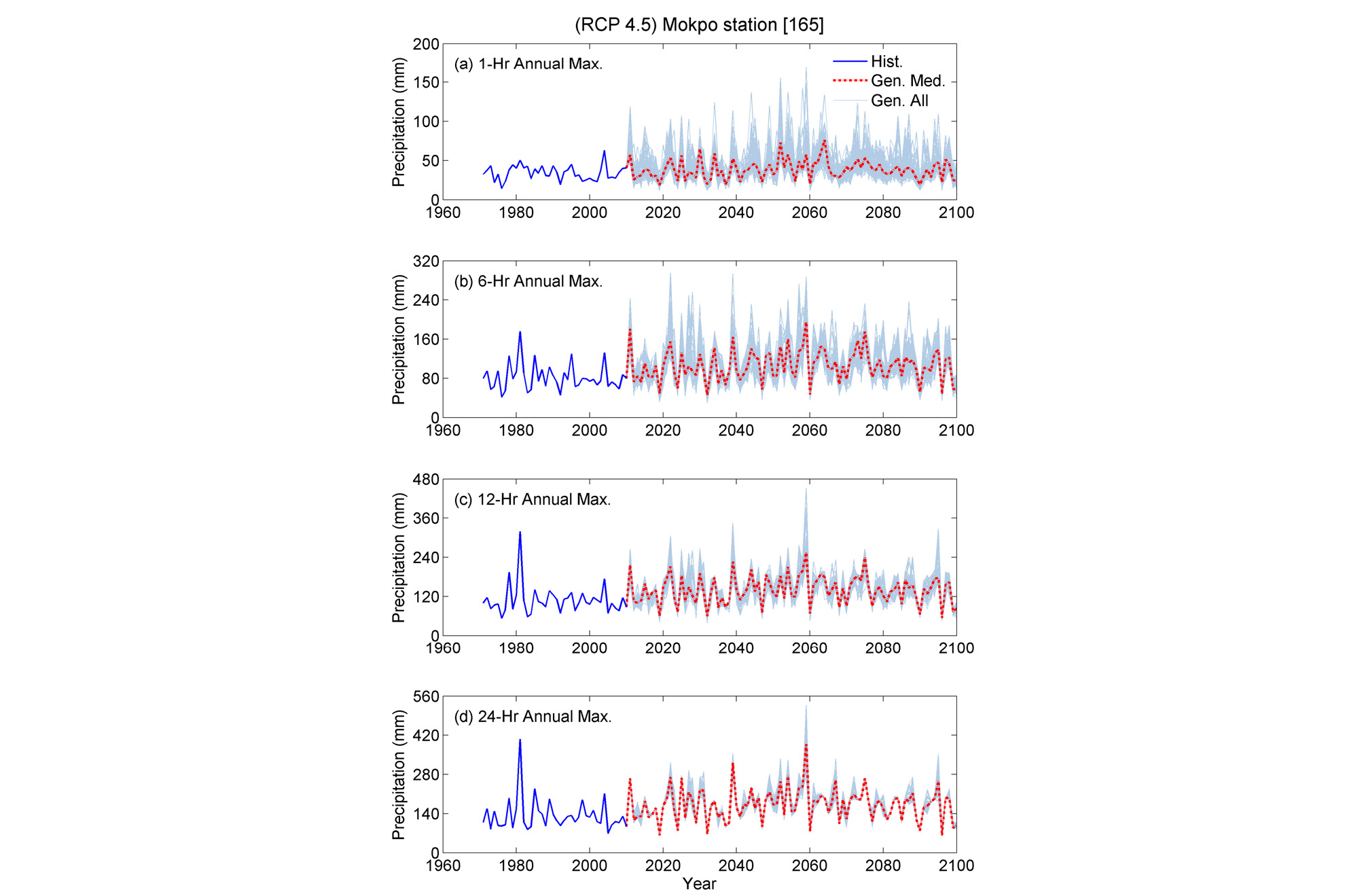
Fig. 7.
Time series of annual maximum precipitation for different durations at Mokpo station. note that the base period is between 1979~2005 and future period for the rcp8.5 scenario is 2006~2100. solid line indicates the observed data and the gray lines are 100 downscaled series and their median with red dotted line
4.3 지속시간별 연최대강우 대표시나리오 (Representative scenarios of AMP)
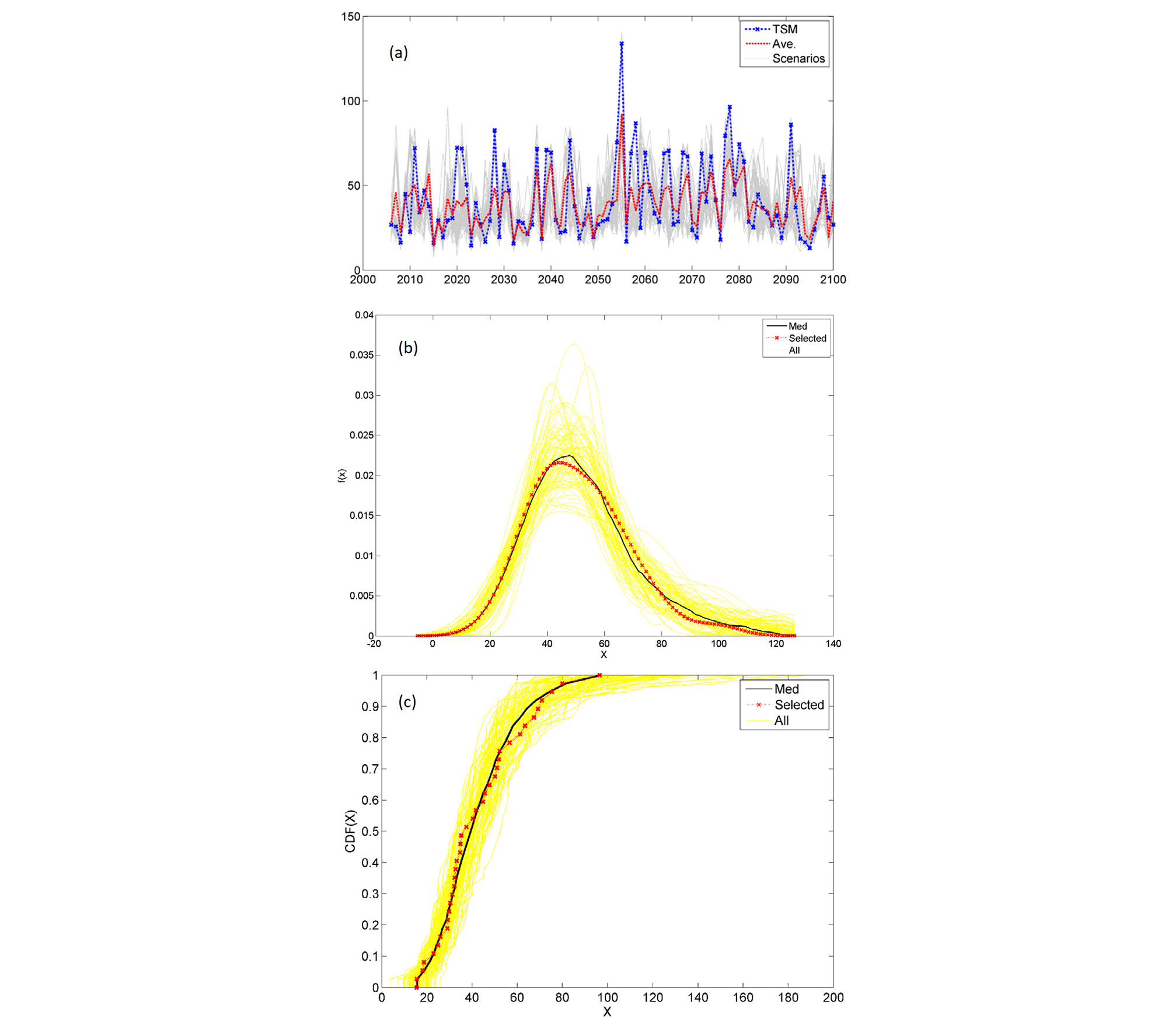
위의 시간상세화 모형으로부터 여러 개의 시간자료로 상세화된 시리즈가 발생하는데 이중에서 대표되는 시나리오를 선택하는 3가지 방법을 연구하였고 Eqs. (6)~(8)과 같다. 이에 대한 예시가 Fig. 8에 잘 나타나 있다. 이 기법은 여러 시리즈를 생성시 이를 대표해주는 하나의 시리즈를 찾는 것이므로 통계학적인 시리즈의 전체 분포형을 바탕으로 이를 전체적으로 가장 잘 반영하는 시리즈를 선택하는 방향으로 모델을 고안하였다. Fig. 8에서 보는바와 같이 먼저 (a) 전체 시리즈의 평균과 표준편차의 기본 통계치를 가장 잘 반영하는 형태를 선택하는 방법(Eq. (6)), (b) 전체 시리즈들에 대해서 밀도함수들을 구하고 이들의 평균치를 반영해주는 방법(Eq. (7)), 그리고 (c) 경험적누적분포함수를 바탕으로 이의 중앙치를 가장 잘 반영하는 시리즈를 선택(Eq. (8))하는 방식으로 결정하게 된다. 분석결과, Lee et al. (2018)는 경험적누적분포함수를 이용한 방식이 가장 적절히 전체적인 대변을 잘해주는 것으로 나타났다.
4.4 지속시간별 미래 연최대강수량 결과
최종 선택된 자료의 지속시간별 연최대강수량의 평균치를 모든 고려된 지점에 대해서 Fig. 9에서 박스플롯으로 보여주고 있다. 기준기간은 앞서 설명하였다시피 1979~2005년까지로 하였고 미래기간에 대해 세등분하여 비교하였다.
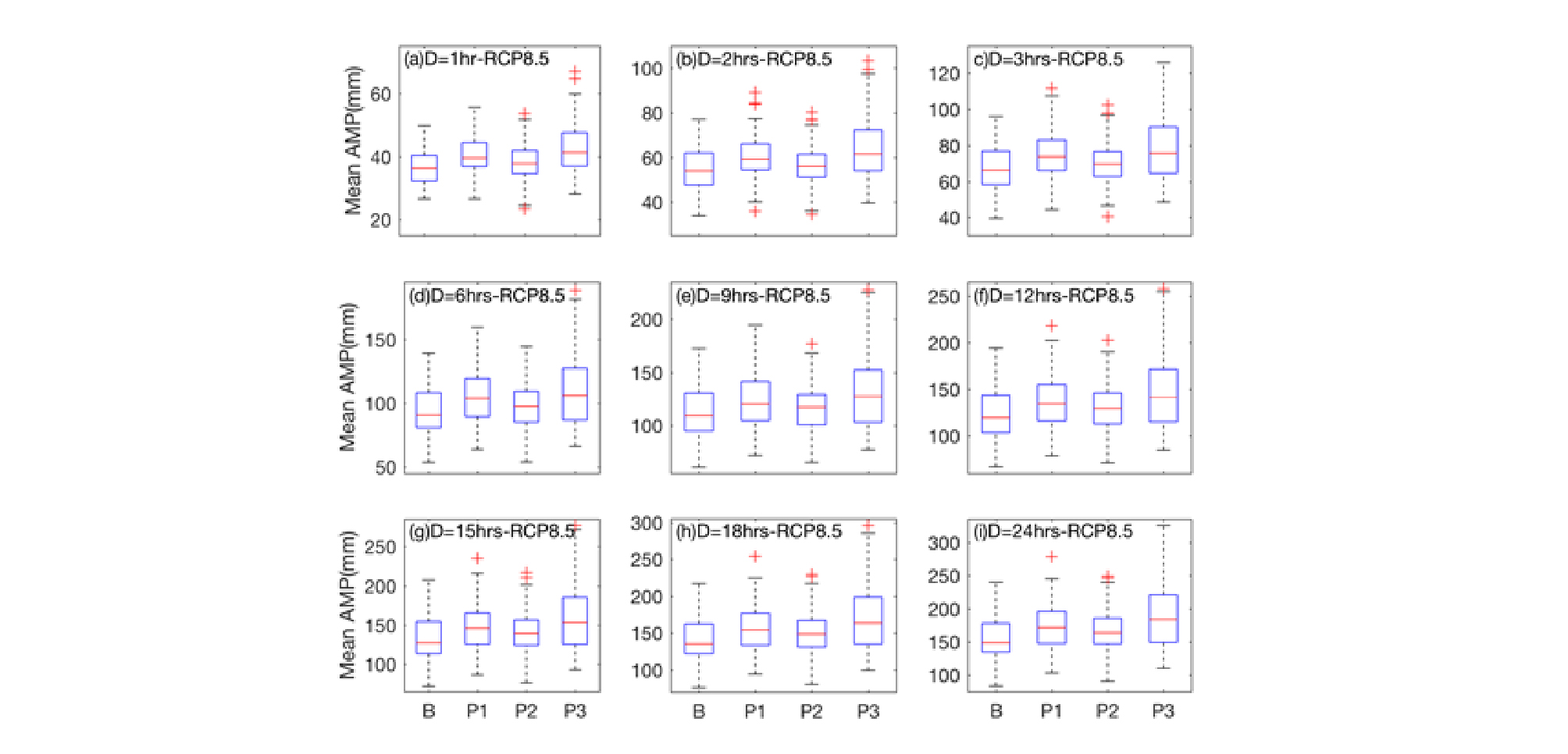
전체적으로 RCP8.5의 경우 기준기간 보다 모든 기간에서 평균치가 증가하는 것으로 보인다. 전체적인 경향성은 P1기간에서 증가하다 P2에서 감소한후 P3에서 가장 크게 증가하는 것으로 보여진다. 이는 원자료인 RCM자료의 특성을 그대로 잘 따라가는 것으로 나타난다.
5. 결 론
한국 내 대부분의 중소규모 하천이나 도시유역에서는 강우 발생 후 수시간 내로 유출이 발생하게 된다. 하지만, 일반적으로 제공되는 GCM 또는 RCM 일강우가 제공되어 기후변화의 수문학적 영향을 연구하기에는 한계점이 있다. 이를 해결하기 위하여 여러 단계를 거쳐 새로운 미래 시간단위 강우를 생성하는 연구를 수행하였고 지속시간별 극치강우를 효과적으로 모의하며 최종적으로 가장 적절한 대표강우시나리오를 생성할 수 있는 모형을 개발하였다. 본 연구는 극치강우에서 기후변화 영향을 고려하기 위해 미래강우시나리오 상세화하고 가장 적절한 대표 지속시간별 연최대강우량를 산정하기 위해 개발된 다양한 방법과 과정을 소개하였다.
진행된 연구에서 한국 극치강수량을 잘 반영해주는 혼합분포형을 사용하여 Bias-correction을 실시하였고, 기존의 일단위 상세화를 강우사상별로 상세화하는 방법을 적용하여 다양한 시리즈의 시강우 자료를 생성하였다. 다양한 시리즈 중 전체를 대표하는 하나의 대표 지속시간별 연최대강우량을 생산하였다.
본 연구 결과를 통해 미래 기후변화로 인한 극치강우의 영향에 효과적으로 대응할 수 있는 수리구조물의 설계가 가능할 것으로 판단된다.
