

1. 서 론
2. 연구방법
2.1 가뭄의 정의
2.2 대상유역
2.3 수문학적 동질성 검정
2.4 Copula 함수
2.5 가뭄 지역빈도해석
3. 결과 및 고찰
3.1 수문학적 동질성 검정 결과
3.2 주변확률분포형 선정 결과
3.3 결합확률분포 선정
3.4 수문학적 이변량 가뭄 지역빈도해석 결과
4. 결 론
1. 서 론
가뭄은 온도, 습도, 일조량, 운량, 토양수분 등 기상ㆍ수문학적 인자, 사회 ‧ 경제적인 인자가 복합적으로 작용하여 발생하며 가뭄으로 인한 피해의 영향은 장기적, 전국적으로 나타난다. 이에 대한 파급효과 또한 사회, 경제, 환경 등 복합적인 양상으로 발생하여 정량적인 파악에 어려움이 있다. 위와 같은 이유로, 가뭄은 관심 분야, 지역, 시기, 인자 등의 기준에 의해 상이하게 정의된다.
Wilhite and Glantz (1985)는 기후와 지역 특성을 기반으로 가뭄을 기상학적, 농업적, 수문학적, 사회경제적 가뭄으로 구분하였다. 세계기상기구(World Meteorological Organization, WMO)에서는 강수량이 지속적이고 연속적으로 부족한 현상으로 가뭄을 정의하였으며, McGuire and Palmer (1957)는 강수량 기준값을 제시하여 평수기의 기준값 이하의 강수량을 기록하는 시기를 기상학적 가뭄으로 정의하였다. Palmer (1965)는 관측된 월 강수량, 기온, 토양유효용량 및 증발산량 사이의 관계를 가뭄 심도와 연계하는 파머가뭄지수(Palmer Drought Severity Index, PDSI)를 제시하여 수문학적 가뭄의 평가를 수행하였다.
Shafer and Dezman (1982)는 표면유출인자(강수량, 유출량, 저수량, 적설량) 자료를 이용하여 SWSI 지표를 제시하여 수문학적 가뭄에 대한 정량적인 평가를 수행하였으며, Byun (2009)은 가뭄과 물부족을 구분하여 자연적인 강수 부족량을 기반으로 기상학적 가뭄을 정의하였으며 농업적, 수문학적, 사회경제적 가뭄을 물의 남용 및 물수요의 증가로 구분하여, 새로운 가뭄 평가 기법을 제시하였다.
우리나라의 기상청(Korean Meteorological Administration, KMA)은 Wilhite and Glantz (1985)가 정의한 가뭄 이론을 기반으로 ‘어느 지역에서 일정 기간 이상 평균 이하의 강수로 인해 강수량이 부족이 장기화되는 현상’으로 기상학적 가뭄을 정의하였으며, 댐이나 저수지, 하천 등의 수량 부족 등 전반적인 수자원 공급의 부족을 수문학적 가뭄이라고 정의하여 우리나라의 지형조건과 물공급 특성에 맞게 SWSI를 보완한 수정지표수공급지수(Modified Surface Water Supply Index, MSWSI)를 활용하여 수문학적 가뭄의 정량적 평가를 수행하고 있다.
일반적으로 수문학적 가뭄은 기상학적 가뭄으로부터 전이되는 가뭄전이 현상에 의해 발생되며(Changnon, 1987; Eltahir and Yeh, 1999) 수개월에 걸쳐 진행되는 특성이 있다. 가뭄의 발생은 댐과 저수지의 유입량 및 저수량에 심각한 영향을 미치며 정상적인 기후로 회복된 뒤에도 장기간에 걸쳐 가뭄의 영향이 지속된다. 댐은 생공용수공급, 수력발전과 하천의 기능유지(수질, 수생태 관리 등)를 위한 하천유지유량 방류 등 하천관리에 있어 매우 중요한 역할을 하며, 강수량의 부족으로 인해 댐의 유입량 및 용수가 부족해질 경우 용수공급 및 하천 하류에서 수질 및 수생태 문제가 발생 될 수 있다(Kim et al., 2016).
2022년 우리나라 봄철의 강수량은 154.9 mm를 기록하여 평년(222.1~268.4 mm)에 크게 못 미치는 것으로 관측되었으며, 전국 다목적댐의 평균 저수율은 42.5%를 기록하여 전년 대비 약 12% 낮은 수치를 나타내었다. 기후변화로 인한 수문학적 가뭄의 모니터링과 대응을 위해서는 가뭄의 정량적인 평가를 위한 연구가 선행되어야 하며 국내외에서 신뢰도 높은 가뭄위험도 평가를 위한 연구가 다양하게 진행되었다. Ryu et al. (2002)는 TANK모형을 기반으로 SWSI 지수를 산정하여 PDSI 및 SPI와 비교하여 가뭄을 정량적으로 분석하였다. Zhang et al. (2013)은 중국의 동강 유역을 대상으로 Copula 함수를 이용한 이변량 가뭄지점빈도해석을 수행하였으며, Wong et al. (2013)은 유럽을 대상으로 기상학적 가뭄과 수문학적 가뭄의 특성인자 간(지속시간, 심도)의 의존성을 연구하였다. Lee et al. (2021)는 SPEI, SDI, WBDI 지수를 산정한 뒤, 이변량 지점빈도해석 방법을 사용하여 수문학적 가뭄평가를 실시하였다.
빈도해석을 통해 도출되는 재현기간은 수문학 분야에서 물수급체계 조사, 수공구조물의 설계기준 및 수자원 관리계획 수립 등 수자원 계획을 수립하기 위한 설계인자로 활용된다(Kwak et al., 2012). 일반적으로 활용되는 지점빈도해석(at site frequency analysis) 기법은 대상 자료의 관측기간이 충분히 확보되지 못하면 산정되는 확률수문량의 신뢰도가 떨어지는 문제점이 발생할 가능성이 높다(Kwon et al., 2013). 이에 대한 해결방안으로 지역빈도해석(regional frequency analysis) 방법이 제안되어 국내외로 다수의 연구가 진행되고 있으며(Hosking and Wallis, 2005) 관측 연수가 짧고 미계측 유역과 같이 결측 자료가 다수 존재하는 수문학 분야에서 활용성이 높게 평가되고 있다.지역빈도해석 방법은 대상 유역 내의 자료를 사용하는 방법으로 지역의 구분 및 대상자료의 동질성 검정 수행이 선행되어야 한다. 본 연구에서는 낙동강 유역 내의 다목적댐의 유입량 자료를 대상자료로 활용하여 지역의 구분을 고려하지 않았다. 지역빈도해석 방법에서 지역 동질성(regional homogeneity) 검정은 가뭄변량의 지역빈도함수를 결정짓는 지점들의 통계적 특성치들의 유사성을 검정하기 위한 방법이다. 본 연구에서는 이질성 척도(heterogeneity measure)를 활용하여 도출된 가뭄 사상의 지역적 동질성 검정을 수행하였다. 이질성 척도는 각 지점의 자료에 대하여 임의성을 가정할 수 있을 만큼 자료의 이산도를 모의 발생시킨 평균과 이산도의 차 및 표준편차의 비로 정의된다(Hosking, 1990). 위와 같이 국내외적으로 지역빈도해석 기법 기반의 수문학적 가뭄의 위험도 평가 연구가 활발하게 수행되고 있지만, 댐 및 저수지의 수문자료를 직접적으로 이용한 수문학적 가뭄 위험도 평가 연구는 상대적으로 미진하다. 따라서, 본 연구에서는 수문학적 가뭄의 위험도 평가를 위하여 이변량 가뭄지역빈도해석 기법을 기반으로 낙동강 유역 내 다목적댐의 유입량 자료를 이용하여 결합재현기간을 도출하고자 한다. 이에 앞서, 추출된 가뭄사상을 대상으로 수문학적 동질성 검정을 수행하여 낙동강 유역에서의 지역빈도해석의 적용가능성을 검토하였다. 이후 변량 간의 서로 다른 분포 특성을 고려할 수 있는 Copula 함수를 기반으로 가뭄 변량 간의 결합분포 관계를 구축하였다. 구축된 결합분포관계를 기반으로 이변량 지역빈도해석 기법을 적용하여 수문학적 가뭄사상의 결합재현을 도출하였다. 최종적으로 지점 및 지역빈도해석 방법에서 산정된 확률수문량의 비교를 수행하였으며, Fig. 1에 연구의 수행과정을 도시하였다.
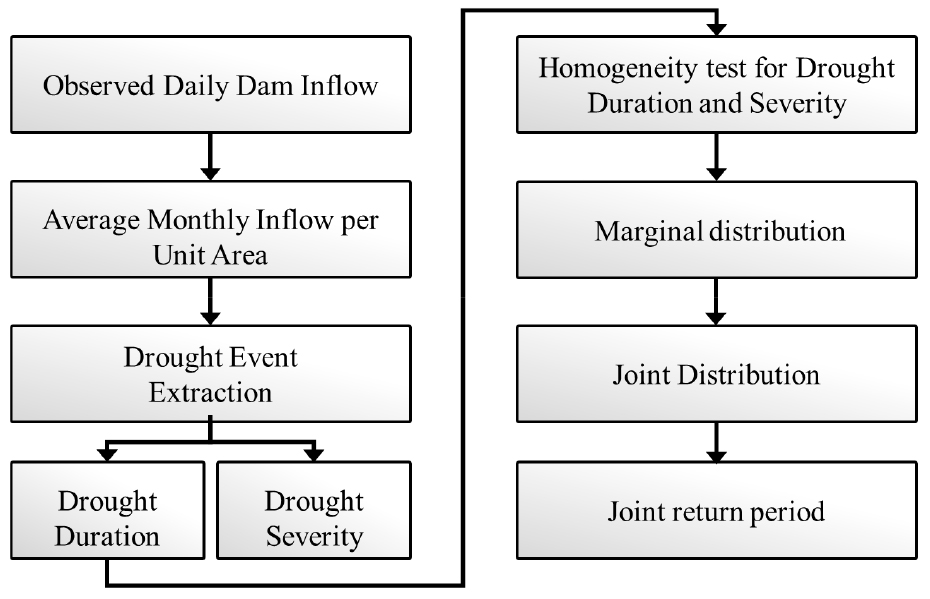
2. 연구방법
2.1 가뭄의 정의
가뭄이란 일정 기간 동안 평균보다 적은 강우로 인해 장기적으로 강우량 부족이 발생하는 현상으로, 가뭄을 다루는 목적에 따라 기상학적(meteorological), 농업적(agricultural), 수문학적(hydrological), 사회경제적(socioeconomic) 가뭄으로 정의될 수 있다. 본 연구에서는 수문학적 가뭄의 빈도해석을 수행하기 위해 월 평균 유입량 자료를 이용하였으며 Yevjevich (1967)에 의해 제안된 연속이론(run theory)으로 가뭄을 정의하여 가뭄의 지속기간과 심도를 산정하였다. 연속이론에서 제안된 가뭄 및 가뭄변량의 정의는 Fig. 2에 도시하였다.
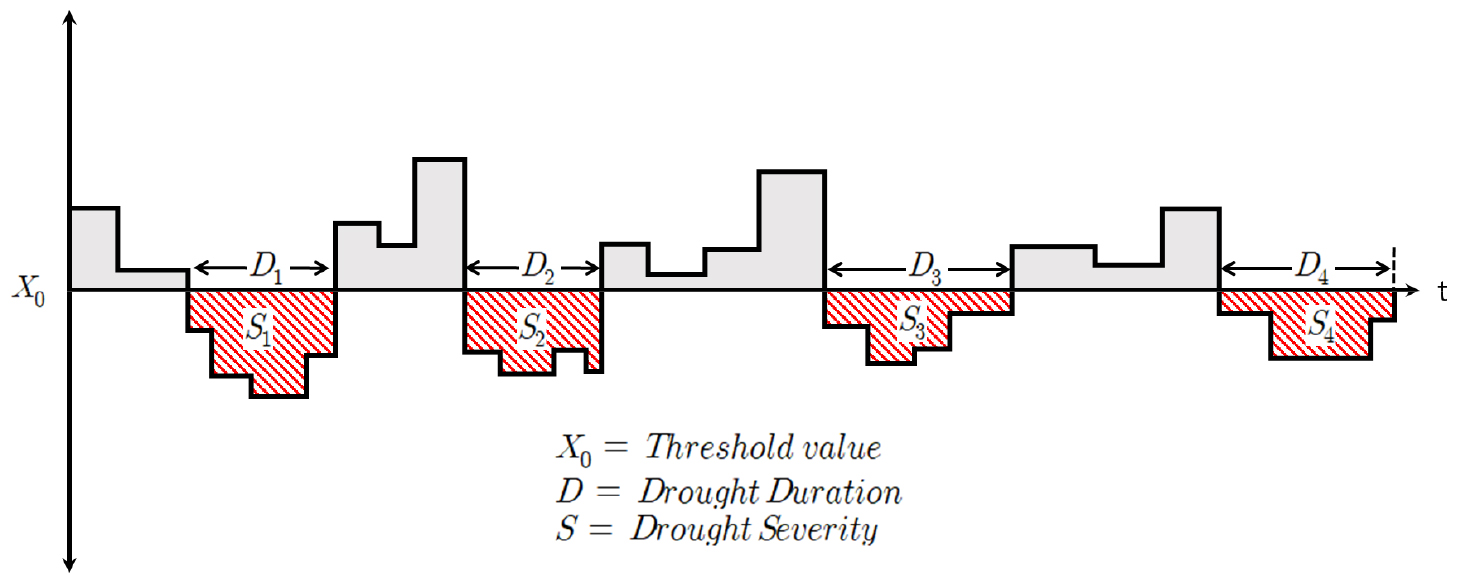
연속이론에서 사상(event)은 수문변수 Xt가 정의된 값(threshold value) X0이하로 떨어진 사건으로 정의된다. 본 연구에서는 가뭄의 특성인자를 추출하기 위해 연속이론을 활용하였으며, 낙동강 유역 다목적댐 10개소의 6개월 누적유입량 자료를 활용하여 정상년 유입량을 기준으로 Anomaly를 산정하였다. Anomaly 시계열이 0 이하로 떨어졌을 때, 가뭄의 시작부터 종료까지 기간을 가뭄 지속기간, 0 이하로 떨어진 양의 총합을 가뭄심도로 정의하여 Eq. (1)와 같이 가뭄의 절단수준을 결정한 뒤 최종적으로 가뭄을 구분하였다.
여기서 n,i는 Anomaly의 연도와 월을 나타내며, 은 6개월 누적 유입량을 의미한다. 은 자료기간에 대한 m월의 Anomaly 평균이며 Xt는 가뭄상태를 의미한다.
2.2 대상유역
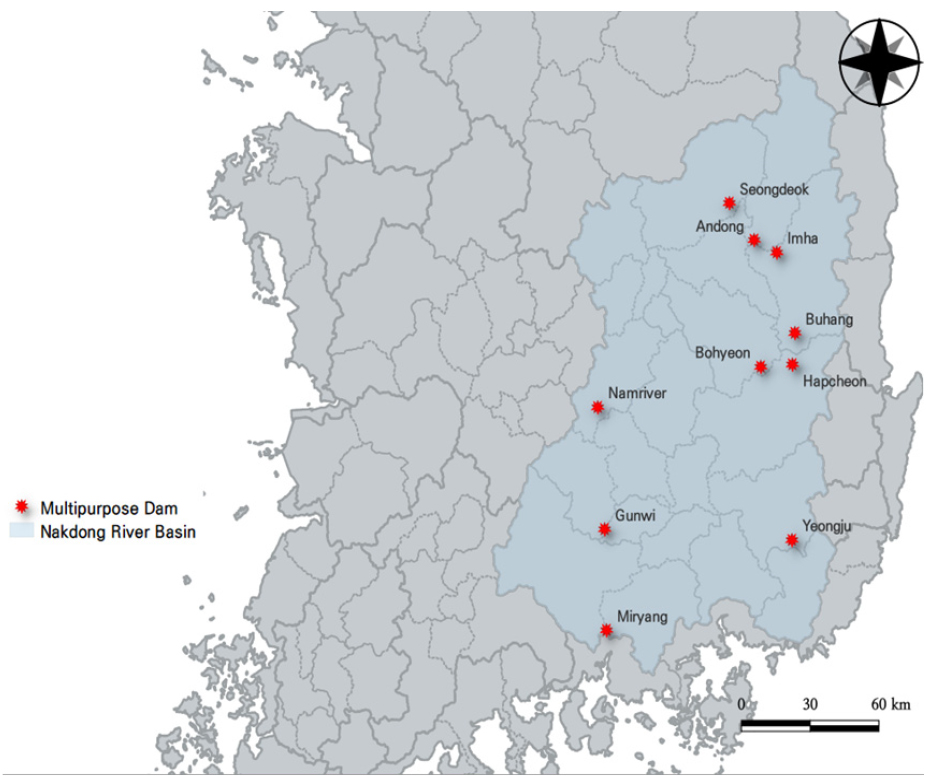
본 연구의 대상 지점은 K-water에서 관할하는 낙동강 유역 내 10개의 다목적댐으로 군위댐, 김천부항댐, 남강댐, 밀양댐, 보현산댐, 성덕댐, 안동댐, 영주댐, 임하댐, 합천댐의 관측 자료를 이용하여 연구를 수행하였다. 가뭄변량을 대상으로 낙동강 유역의 전반적인 특성을 확인하기 위해 일유입량 자료를 유역면적으로 나누어 단위 면적 당 유입량자료를 산정하여 6개월 누적 유입량으로 변환하였으며, 연속이론에 따라 가뭄빈도해석 시 필요한 변량을 추출하였다. 사용된 댐별 속성정보를 Table 1에 나타내었으며 Fig. 3는 본 연구에서 활용한 낙동강 유역 내 위치한 10개의 다목적댐의 위치를 도시하였다.
Table 1.
Characteristics of 10 multi-purpose Dams located in Nakdong-river watershed
2.3 수문학적 동질성 검정
지역빈도해석은 자료 수가 부족할 경우 도출되는 확률수문량의 신뢰성이 떨어지는 경향이 나타나는 지점빈도해석의 문제점을 해결하기 위한 대안으로서, 대상 지역의 자료를 기반으로 빈도해석을 수행하는 모형이며 다수의 연구에서 효율성을 확인할 수 있다. 그러나 지역빈도해석은 대상 유역의 지점 자료만을 사용하여 확률수문량을 산정하는 지점빈도해석과는 다르게 대상 유역의 자료를 모두 사용하여 빈도분석을 수행하므로 유역 내 지점들이 수문학적 동질지역(regional homogeneity)이라는 가정이 전제되어야 한다. 지역빈도함수를 결정짓는 지점의 특성치들의 유사성 확보를 위한 수문학적 동질유역 구분은 지역빈도해석 과정에서 중요한 절차이며, 본 연구에서는 낙동강 유역 내의 수문학적 가뭄사상을 대상으로 Hosking and Wallis (1997)가 제안한 이질성 척도(H)지표를 산정하여 수문학적 동질성을 평가하였다. 이질성 척도는 L-모멘트법을 사용하여 유역 내 자료들의 동질성을 평가하는 지표로서 유역 내 모든 지점들의 자료가 동일한 확률분포형을 따른다고 가정하여 관측자료와 모의 발생시킨 L-모멘트 비 간의 평균 및 표준편차의 비로 정의한다(Hosking, 1990). L-모멘트법은 확률가중모멘트법(probability weighted moment, PWM)의 선형조합으로 표현되며 모멘트에 가중치를 부여하여 산정된 매개변수의 편의가 최소화되며, 관측자료의 크기에 따라 편의가 다르게 나타나는 일반모멘트 방법에 비해 동질유역의 구분이 유리하다. L-모멘트의 추정량은 Eq. (2)과 같다.
Eq. (2)로 추정된 L-모멘트를 이용하여 L- 변동계수(L-coefficient of variation), L-왜곡도 계수(L-skewness), L-첨예도계수(L-kurtosis)를 정의하면 Eq. (3)과 같으며(Hosking and Wallis, 1986) 지역평균 L-모멘트비를 이용하여 산정된 가중분산V는 Eq. (4)과 같다.
여기서 는 의 범위를 가진다.
여기서 는 지점의 수, 는 지점의 자료 개수, 는 지점 각각의 L-변동계수, L-왜곡도계수, L-첨예도계수이며, 는 지역의 L-변동계수, L-왜곡도계수, L-첨예도계수이다. 이질성 척도는 모멘트 값을 가지는 Kappa 분포를 적합시킨 후, 각 지점의 자료 개수와 동일한 수의 자료를 모의발생 시키는 과정을 통해 Eqs. (4) and(5)에 대입하여 산정된다. 본 연구에서는 충분한 임의성을 가질 수 있도록 500회 이상의 모의 발생을 수행하였다. 지역의 L-모멘트비는 지점의 자료 개수에 따라 가중치를 부여하며 다음 식과 같다.
이질성 척도는 사용된 L-모멘트비에 따라 H1(L-변동계수), H2(L-왜곡도 계수), H3(L-첨예도계수)의 세 가지 형태로 나타낼 수 있으며, H<1이면 동질성 지역, 1≤H<2이면 이질성 지역일 가능성이 있으며, H>2이면 확실한 이질성 지역으로 분류 가능하다.
2.4 Copula 함수
가뭄 사상은 서로 상관성을 가지는 변량의 복합적인 작용을 기반으로 발생하며 빈도해석 수행 시, 신뢰성 있는 재현기간 평가를 위해서는 이러한 다변량의 특성을 동시에 고려하여야 한다.
Sklar (1959)에 의해 제시된 Copula 함수는 각 변량의 분포 특성이 다르게 나타나는 경우 주변확률분포 선정이 자유롭고 결합확률분포의 추정이 용이하며 자료의 극치값의 분포 관계를 파악하기 적절하다고 알려져 있다. 최근 수문학 분야에서는 Copula 함수를 사용한 다변량 분석을 수행하는 연구가 다수 진행되었으며(Kim et al., 2019) 수문학 분야에서 사용하는 자료의 경우 꼬리(tail)부분이 두꺼운 극치값이 나타나며 형태가 다소 비대칭적인 비정규성 분포의 경향이 강하게 나타난다. 가뭄과 같은 다양한 변량이 복합적으로 발생하는 현상에 대해 빈도해석을 수행할 경우 극치사상(extreme events)의 빈도를 추정하는 것은 중요하며 동시에 확률변수 간의 종속성 구조를 고려할 수 있어야 한다.
Copula 함수를 사용하여 다변량 가뭄빈도해석을 수행할 경우, 각 변량 간의 특성과 극치값을 반영하는데 있어 적절하다고 판단된다. Sklar의 정리를 통해서 확률변수 에 대해 결합누가분포함수의 주변 누가분포함수와 가 존재하며 서로 연속일 때, 이를 연결시킬 수 있는 Copula 함수 가 존재함을 알 수 있다. Copula 함수는 매개변수적 Copula, 비매개변수적 Copula 함수로 구분이 가능하다. 매개변수적 Copula는 Student’s t copula, Gaussian과 Archimedean copula인 Gumbel, Frank, Clayton copula 등이 있으며, 비매개변수적 Copula는 Kernel, Empirical copula가 있다. 본 연구에서는 매개변수적 Copula 함수인 Archimedean Copula를 활용하였다. Archimedean Copula는 매개변수 추정이 다소 간단하며 다양한 확률분포형에 적용이 가능한 장점이 있으며 함수식은 Table 2와 같다.
Table 2.
The Archimedean Copula function used in this study
| Type of Copula | Joint Probability Distribution Function () | Parameter () |
| Clayton | ||
| Frank | ||
| Gumbel |
가뭄의 지속기간 및 심도는 가뭄 발생 시 나타나는 특성으로 서로 상관성이 높은 것으로 알려지고 있으며 확률분포를 통해 변량의 특성을 정의할 수 있다. Shiau and Shen (2001)은 두 변량간의 결합확률밀도함수를 활용하여 가뭄의 평균 발생 간격을 산정하였다. 이는 Shiau (2006)에 의해 정의된 이변량 가뭄빈도해석 식의 입력 값으로 활용이 가능하며 사용된 함수식의 형태는 Eq. (7)과 같다.
특정 지속기간과 심도를 갖는 사상이 발생하는 경우, TDS는 가뭄의 지속기간 및 심도가 모두 초과할 확률일 때의 결합재현기간이며 는 가뭄의 지속기간과 심도 중 한 변량이 초과할 확률의 재현기간을 의미하며 은 가뭄의 평균 발생 간격, 와 는 가뭄의 지속기간과 심도의 누가분포함수이다.
2.5 가뭄 지역빈도해석
수문학 분야에서 관측자료를 활용한 지점빈도해석 수행 시, 관측기간이 짧은 경우 산정되는 확률수문량의 신뢰도가 떨어지는 문제점이 발생될 수 있으며, 지점 내의 충분한 자료의 확보가 필요하다. 이에 대한 대안으로 지역빈도해석 방법을 사용한 연구가 국내외로 다수 진행되었으며, 효율성이 확인되었다. 지역빈도해석은 지점 내의 자료가 부족한 경우나 미계측 지점의 확률수문량을 산정하기 위해 제안된 방법으로서 우리나라의 유입량 자료와 같이 자료연수가 다소 부족한 경우 지역빈도해석이 사용되면 효율적으로 확률수문량의 산정이 가능하다. 본 연구의 목적은 우리나라 유입량 자료를 이용한 지역빈도해석을 수행하여 가뭄의 특성인자별 적절한 확률분포형을 선정하고 신뢰성 있는 가뭄의 재현기간을 산정하는 것이다. 대상유역의 자료를 사용하기 위하여 수문학적 동질성 검정을 선행하였으며 Copula 함수를 이용하여 지역빈도해석을 수행하였다.
지역빈도해석은 지점빈도해석과 대상자료의 샘플링 과정은 다르지만 통계적 추론 과정은 동일하다. 연속이론으로 정의된 가뭄사상의 발생확률은 확률밀도함수로 정의하며 이를 위해 각 변량의 주변확률분포, 결합확률분포 및 매개변수의 추정 후 검증을 통해 최적의 모형을 선택하였다. 본 연구에서는 이변량 가뭄지역빈도해석을 수행하기 위해 지역 가뭄변량의 표준화 과정을 선행하였으며 각 댐별 가뭄변량의 평균값을 사용하여 표준화를 수행하였다. Eq. (8)은 표준화 과정을 나타낸다.
여기서 는 번째 댐의 번째 가뭄변량이며 는 번째 댐의 가뭄변량의 개수, N은 댐의 개수, 및 는 번째 댐의 가뭄변량의 평균, 는 번째 댐의 번째 표준화를 통해 산출된 가뭄변량의 표준화된 자료를 나타낸다.
3. 결과 및 고찰
3.1 수문학적 동질성 검정 결과
본 연구에서는 낙동강 유역 내 다목적댐들의 유입량 자료를 6개월 누적유입량으로 변환 후 Eq. (1)를 이용하여 가뭄사상의 지속기간과 심도를 추출하였다. 댐 관측자료들의 동질성 여부를 판단하기 위해 댐별 가뭄특성인자들을 대상으로 표본 L-모멘트비를 산정하였으며 그 결과를 Tables 3 and 4에 요약하였다. 산정된 L-모멘트비를 이용하여 Kappa분포에 적합시켜 매개변수 추정을 수행하였다. 추정된 매개변수를 기준으로 Monte Carlo모의를 수행하여 이질성 척도 H1, H2, H3를 산정하였으며 그 결과는 Table 5와 같다. L-첨예도 계수를 고려한 H3, L-왜곡도 계수를 고려한 H2에 비해 표본자료의 특성을 잘 반영한다고 알려진 L-변동계수를 고려한 H1을 기준으로 지역의 이질성 정도를 판단하였다. 가뭄변량을 대상으로 산정된 H1은 음수의 값을 가짐으로써 낙동강 유역 내의 10개 다목적댐의 유입량 자료는 Hosking and Wallis (1997)가 제안한 동질성 기준에 부합하는 것으로 나타났으며 동질성 검정 결과를 기반으로 가뭄 지역빈도해석을 수행하였다. 이 밖에도 불일치 척도(discordancy measure, Di)를 기준으로 평가하였으며, 제시된 10개 지점은 동질성을 갖는 것으로 평가되었다.
Table 3.
L-moment ratio of the drought duration obtained from multi-purpose Dam data
Table 4.
L-moment ratio of the drought severity obtained from multi-purpose Dam data
Table 5.
Heterogeneity measure for drougtht factor variables
| Heterogeneity measure | Duration | Severity |
| H1 | -0.45 | -1.81 |
| H2 | -1.70 | -1.99 |
| H3 | -2.137 | -2.56 |
3.2 주변확률분포형 선정 결과
본 연구에서는 도출된 가뭄변량에 대하여 Weibull, Loglogistic, Normal, Generalized Extreme Value (GEV), Generalized Pareto (GPA), Exponential, Logistic 등의 확률분포형을 적용하여 매개변수를 추정한 뒤, 적합도 검정을 수행하였다. 대표적인 적합도 검정 방법에는 Maximum Likelihood Estimation (MLE), Akaike Information Criterion (AIC), Akaike Information Criterion correction (AICc), Bayesian Information Criterion (BIC) 등이 있다. MLE방법은 음의 우도함수(L) 값을 사용하며, 적합한 모형은 가장 큰 우도함수 값을 가지므로 MLE값이 가장 최소가 되는 값을 가진 모형이 자료의 분포와 가장 적합한 모형으로 선택된다. MLE방법은 후보모형의 자유도가 모분포보다 높을 경우 매개변수의 개수가 많은 후보모형이 모분포로 선택되는 경우가 많다. 자료의 개수가 적을 경우 그러한 경향이 강해지며 본 연구에서는 적용하지 않았다. AIC방법은 우도함수의 값과 모형의 복잡한 정도에 따라 패널티가 반영되며 가장 최소의 정보 손실(inforamtion loss)를 갖는 모형이 가장 적합한 모형으로 선택되며 식은 다음과 같다.
여기서 는 후보 모형의 매개변수의 개수이다. AIC방법은 MLE방법에 기반하여 적합도 검증을 수행하지만, 모형의 복잡성을 반영하여 패널티를 부여하므로 MLE방법의 단점을 보완하여 모형 선택에 신뢰성을 제공한다. AICc방법은 AIC방법의 보정된 적합도 검정 방법으로 자료의 개수를 반영하여 적합도 검증을 수행하며 MLE, AIC방법과 마찬가지로 최소의 통계량 값을 가진 모형이 최적의 모형으로 선택된다. BIC방법은 우도함수와 사전분포를 이용하여 도출된 사후분포를 기반으로 계산된 통계량이다. 앞의 방법들과 유사하지만 AIC방법에 비해 매개변수의 개수에 더 민감하게 반응하며 식은 다음과 같다.
여기서 은 자료의 개수이다. 본 연구에서는 AIC, AICc, BIC 방법을 사용하였으며 연구에서 사용된 대상자료가 적합도 평가 기준에 따라 선택되는 최적 주변확률분포형이 다르지 않기 때문에 기준이 되는 검정 방법을 따로 정하지 않았으며, 세 가지 방법을 모두 고려하여 가장 적합한 모형을 선정했다. 가뭄변량의 확률분포형에 따른 적합도 검정값을 각각 Tables 6 and 7에 제시하였다.
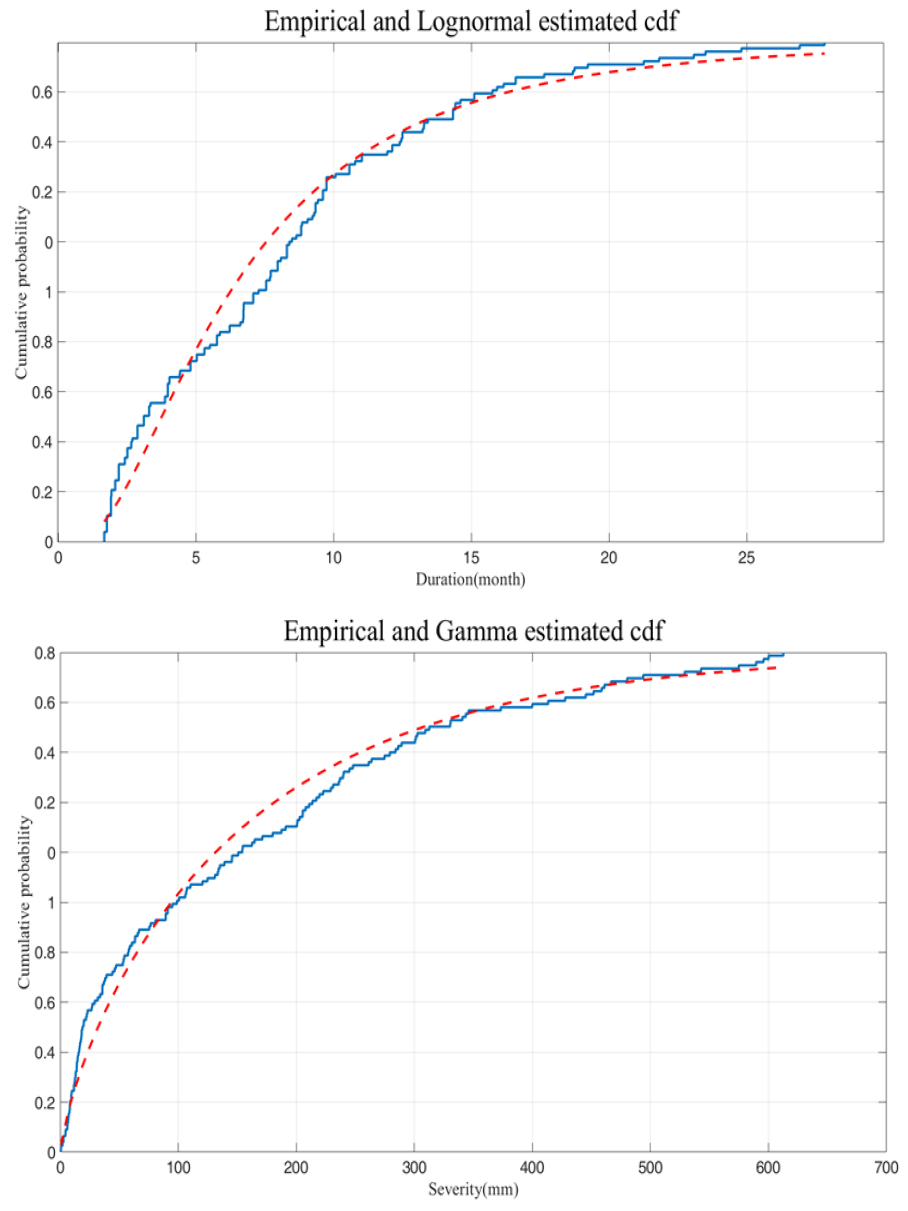
가뭄 지속기간의 경우 Log-normal 분포가 최적의 주변확률분포형으로 산정되었으며, 가뭄 심도는 Gamma 분포가 가장 적합한 것으로 나타났다. Fig. 4는 가뭄의 변량을 이용하여 이론적인 확률분포로부터 추정된 누적확률밀도함수(cumulative distribution function, CDF)와 경험적인 누적확률밀도함수를 도시한 결과로서 가뭄의 지속기간과 심도 모두 확률분포형을 잘 따르는 것을 그림을 통해 확인할 수 있다.
Table 6.
Goodness of fit test result for different marginal distributions (Drought duration)
Table 7.
Goodness of fit test result for different marginal distributions (Drought severity)
3.3 결합확률분포 선정
본 연구에서는 매개변수적 Copula 함수인 Archimedean Copula (Clayton, Frank, Gumbel)에 속하는 세 개의 Copula 함수를 이용하여 지역 매개변수를 추정하였으며, 추정된 모형을 대상으로 적합도 검정을 수행하여 최적의 결합확률분포를 제시하였다. Copula 함수는 다변량 자료의 변량 간의 종속적 구조를 분석하고 모형화하는데 유용한 함수이다. Copula 함수의 모수를 추정하는 방법은 변수들의 결합분포의 가정 정도에 따라 모수적(parametric) 추정방법, 비모수적(nonparametric) 추정방법으로 분류할 수 있다. 모수적 추정 방법에는 최대우도함수를 이용하는 MLE 방법, 각 변량의 주변확률분포의 모수와 Copula 함수의 모수를 단계적으로 추정하는 IFM (inference functions for margins) 방법, 주변확률분포의 순위를 기반으로 재구성된 자료를 이용하여 최우도법으로 코플라 함수의 모수를 추정하는 유사우도방법(maximum pseudo likelihood) 등이 존재하며 IFM방법은 2단계 추정방법으로 분류되기도 한다. 비모수적 추정방법에는 각 변량의 주변확률분포를 경험적 분포함수로 추정한 후 Copula 함수의 모수를 추정하는 CML(canonical maximum likelihood)방법이 있다.
본 연구에서는 비모수적 척도인 스피어만 상관계수(Spearman’s rank correlation coefficient, )를 사용하여 Copula 함수의 모수를 추정하였으며 이와 같은 방법을 사용했을 경우, 확률변수 간의 종속성 구조를 유실하지 않으며 확률변수 사이의 관계식을 효율적으로 구성할 수 있는 장점이 있다. 추정된 댐별 매개변수()와 지역 매개변수()를 Table 8에 도시하였다.
세 가지 적합도 평가 기준을 토대로 추정된 매개변수에 대한 각 Copula 모형의 적합도 평가 결과를 Tables 9~11에 도시하였다. Gumbel Copula 모형의 지역 매개변수()의 검정값은 -271.742~-274.745으로 -260.178~-263.182인 Frank 모형 및 -144.928~-147.932으로 나타난 Clayton 모형보다 적합한 것으로 평가됐다. 댐별 Copula 매개변수와의 비교를 위해 각 댐별 적합도 검정을 수행하여 지점 매개변수의 합()을 구하였으며 Clayton Copula 모형을 제외한 Gumbel, Frank Copula 모형의 지역 매개변수 적합도 검정값이 댐별 매개변수 검정값보다 작은 것을 확인할 수 있었다. 적합도 값이 작을수록 모형의 안정성과 정확도가 높은 것을 의미하기 때문에 지역빈도해석이 지점빈도해석보다 성능이 좋은 것을 확인할 수 있었으며 결과적으로는 Gumbel Copula 모형을 최적의 Copula 모형으로 선택하여 이변량 가뭄지역빈도해석을 수행하였다.
Table 8.
Estimated copula parameters for region and each dam ()
Table 9.
Goodness of fit test result of region and each dam for the Gumbel Copula model ()
Table 10.
Goodness of fit test result of region and each dam for the Frank Copula model ()
Table 11.
Goodness of fit test result of region and each dam for the Clayton Copula model ()
3.4 수문학적 이변량 가뭄 지역빈도해석 결과
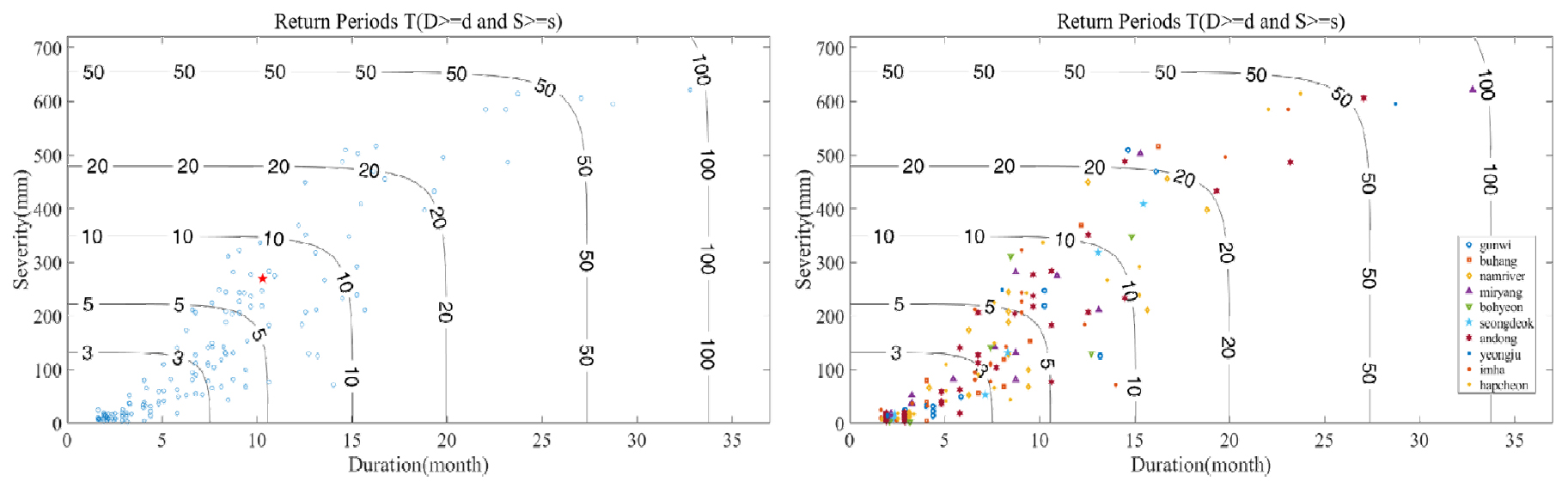
본 연구에서는 연속이론을 사용하여 가뭄의 특성인자로 지속기간 및 심도를 산정하였다. 산정된 특성인자를 대상으로 동질성 검정을 수행하여 지점별 특성치들의 유사성을 확인하였으며 이를 토대로 가뭄의 지속시간과 심도의 주변확률분포를 결정하였다. 본 연구에서는 수문학적 빈도해석에서 사용하는 확률분포형을 대상으로 적합도 검정을 수행하였으며 각각 Log-normal 분포와 Gamma분포가 최적의 주변확률분포형으로 선정되었다. 결합확률분포 모형은 Gumbel Copula 모형을 최적의 모형으로 선택하였으며 선정된 주변확률분포와 Gumbel Copula 모형을 이용하여 낙동강 유역 다목적댐의 이변량 가뭄 지역빈도해석을 수행하였다. 분석 결과, 낙동강 유역의 평균 수문학적 가뭄 발생 간격()은 약 14~15개월로 나타났다. 2022년에 발생한 가뭄사상은 지속기간 10.3개월, 심도 269.1 mm 및 결합재현기간은 약 8년으로 추정되었으며 Fig. 5에 도시하였다.
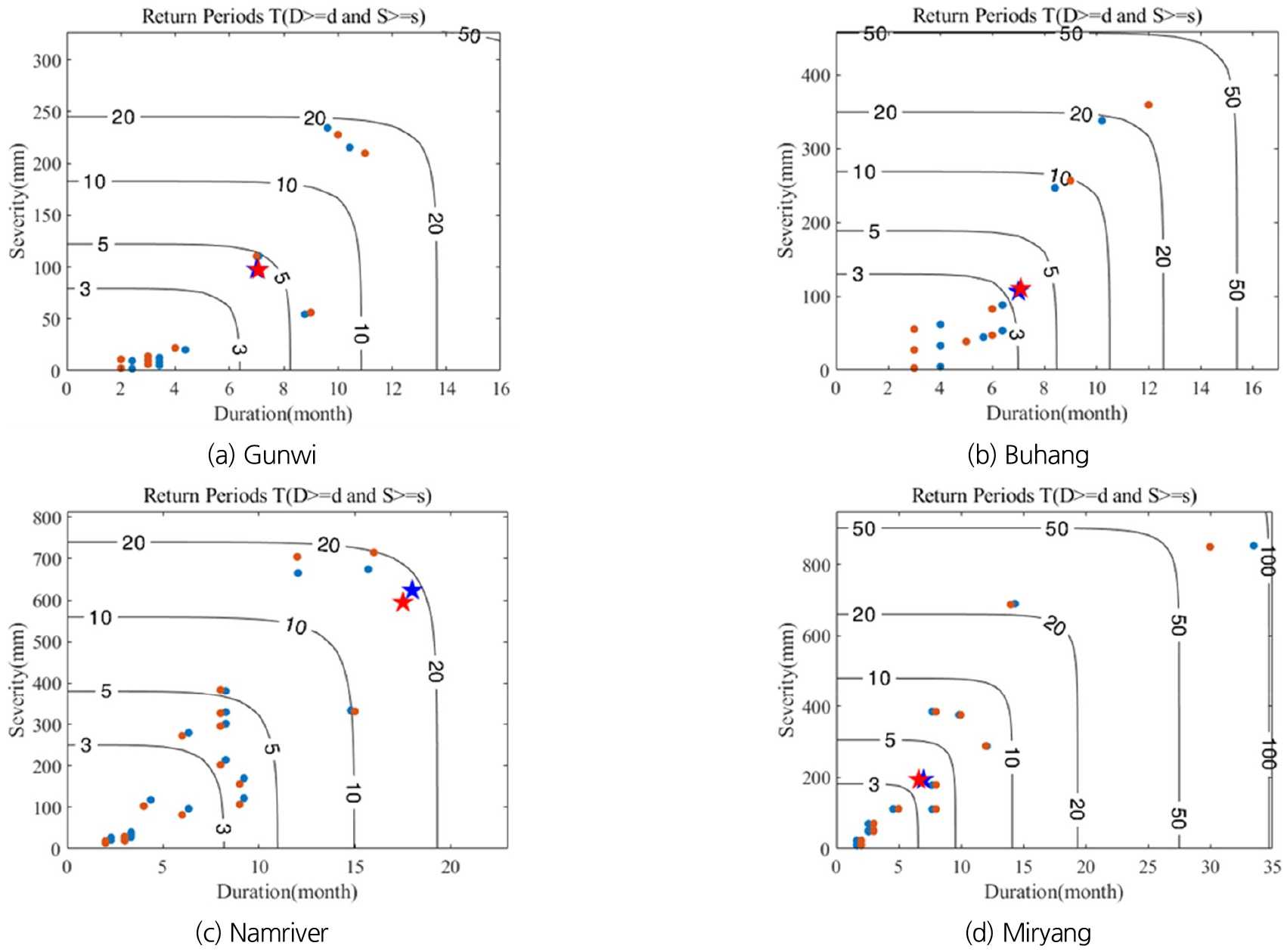
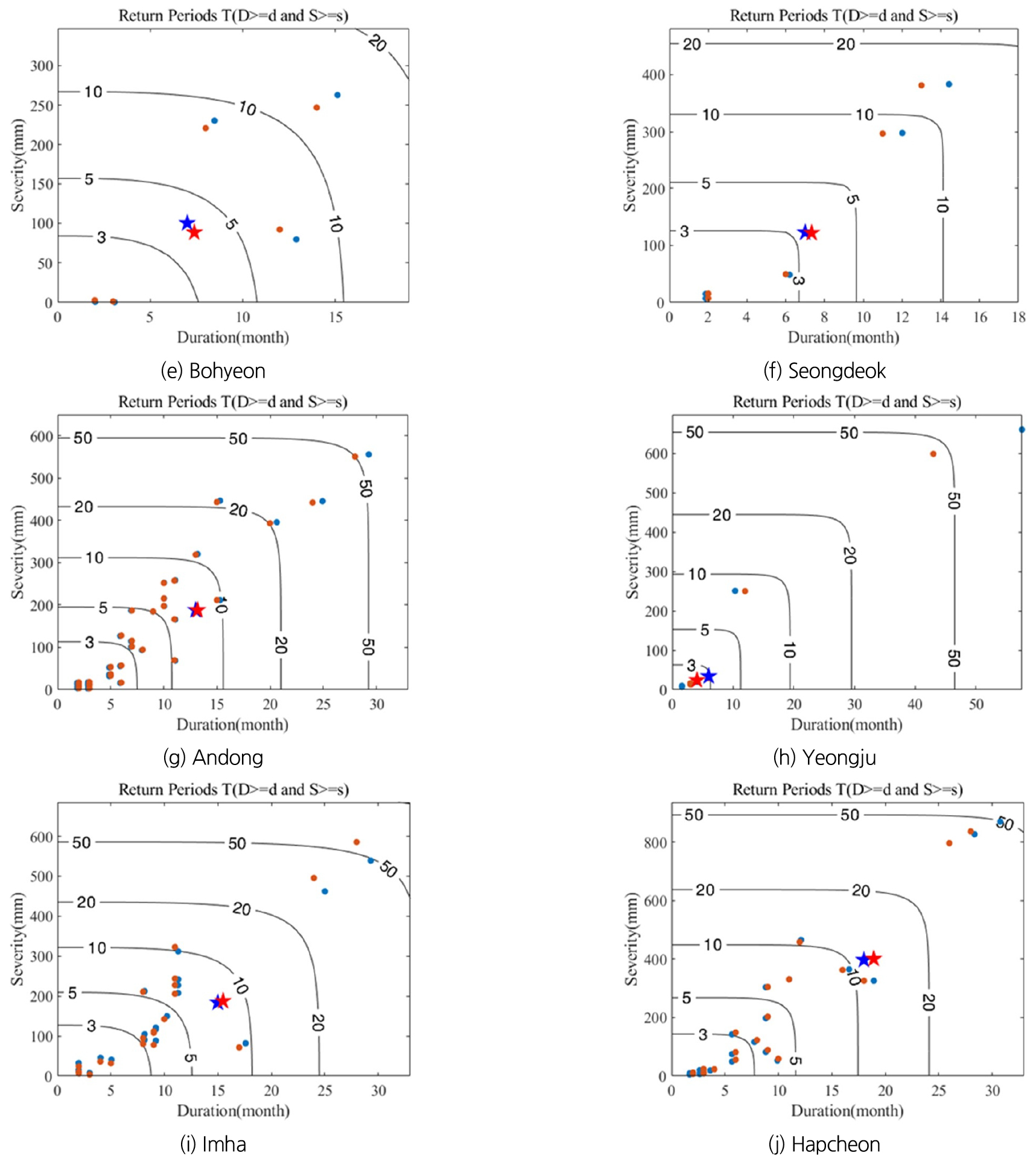
2022년에 남부지역에서 발생한 가뭄사상에 대한 지역빈도해석 결과를 지점빈도해석 결과와 비교하여 Fig. 6에 도시하였다. 도출된 가뭄사상의 결합재현기간을 각각 댐별로 도시하여 2022년 가뭄사상을 평가하였으며 해당 댐의 지역빈도해석 결과를 “파란 원” 및 2022년 가뭄사상을 “빨간 별”, 지점빈도해석 결과를 “빨간 원” 및 2022년 가뭄사상을 “파란 별”로 나타내었다. 군위댐, 김천부항댐, 밀양댐, 보현산댐, 성덕댐, 영주댐의 경우 지점 및 지역 빈도해석의 결과가 모두 5년 이하의 빈도로 나타났으며, 안동댐, 임하댐에서는 10년 이하의 재현기간을 가지는 것으로 나타났다. 합천댐의 경우 약 12.5년의 빈도로 도출되었으며, 남강댐의 경우 재현기간이 약 20년으로 낙동강 유역의 다목적댐 중 가장 큰 가뭄사상으로 평가되었다.
4. 결 론
본 연구에서는 이변량 가뭄 지역빈도해석 기법을 이용하여 2022년에 발생한 남부지역의 수문학적 가뭄사상을 평가하였다. 분석자료로는 낙동강 유역 내 10개 다목적댐의 유입량 자료를 이용하였으며 기존의 이변량 가뭄 지점빈도해석 모형에서 이변량 가뭄 지역빈도해석 모형으로 개념의 확장을 통해 2022년 낙동강 유역에서 발생한 수문학적 가뭄에 대해 평가하였다. 본 연구를 수행한 결과, 다음과 같은 결론을 도출할 수 있었다.
본 연구에서는 이변량 가뭄 지역빈도해석 기법을 이용하여 2022년에 발생한 남부지역의 수문학적 가뭄사상을 평가하였다. 기존의 이변량 가뭄 지점빈도해석 모형에서 이변량 가뭄 지역빈도해석 모형으로 개념의 확장을 통해 대상유역과 가뭄사상의 수문학적 특성을 고려함과 동시에, 산정되는 확률수문량의 신뢰도를 향상하기 위한 목적으로 본 연구를 수행하였다.
수문학적 가뭄사상의 추출을 위하여 낙동강 유역에 위치한 다목적댐 10개소의 유입량 자료를 활용하였으며 댐의 유역면적을 고려하여 각 댐별 유역면적으로 나누어 면적 당 월 유입량 자료를 구축하였다. 수문학적 가뭄 위험도 평가를 수행하기 위해 6개월 누적 Anomaly를 도출했으며, 연속이론을 기반으로 가뭄의 특성인자의 추출을 수행하였다. 지역빈도해석 기법을 적용하기 위해서는 지역의 동질성 검정이 선행되어야 하며 본 연구에서는 이질성 척도를 이용하여 가뭄의 특성인자의 수문학적 동질성 여부를 판단하였다. 낙동강 유역 내 수문학적 가뭄사상의 이질성 척도 값은 음수로 산정되어 동질성 기준에 부합하는 것으로 나타났으며, 음수 값이 도출되었을 경우 유역의 세분화 과정에 대한 고려가 필요하지만 본 연구는 남부지역 가뭄 위험도 평가에 목적이 있으므로 해당 과정을 거치지 않았다.
이변량가뭄빈도해석 시 지역빈도해석을 통한 모형 구축은 기존 지점빈도해석에 비해 통계적으로 우수한 적합능력을 나타내었다. 즉, AIC 및 BIC값을 기준으로 지역빈도해석 방법이 지점빈도해석 방법에 비해 작은 값으로 추정되는 등 전반적으로 모형 적합성 측면에서 우수성이 있는 것으로 평가되었다. 가뭄사상의 특성인자를 대상으로 수문학적 빈도해석에서 사용하는 확률분포형을 적용한 결과, 가뭄의 지속기간은 Log-normal 분포, 심도는 Gamma 분포가 최적의 주변확률분포형으로 선정되었으며 결합확률분포의 경우, Gumbel Copula가 최적의 모형으로 추정되었다. 이를 이용하여 이변량 가뭄지역빈도해석을 수행하여 낙동강 유역의 수문학적 가뭄사상의 결합재현기간을 도출하였다.
재현기간 도출 결과, 2022년에 발생한 낙동강 유역의 수문학적 가뭄 사상은 관측된 과거 가뭄 사상들을 포함하여 중간 규모에 해당하는 가뭄사상으로 평가될 수 있으며, 가장 큰 가뭄 사상은 2007년 밀양댐에서 발생한 가뭄사상으로, 약 100년의 재현기간을 가지는 것으로 평가되었다. 2022년에 발생한 가뭄사상에 대해 각 댐을 대상으로 재현기간을 산정하였다. 군위댐, 부항댐, 밀양댐, 보현산댐, 성덕댐, 영주댐에서는 5년 이하의 재현기간을 가지는 가뭄사상으로 평가되었으며 안동댐, 임하댐, 합천댐에서는 약 10년의 재현기간을 갖는 것으로 평가되었다. 남강댐에서는 재현기간이 약 20년으로 평가되었다. 본 연구에서는 국내외의 정량적 가뭄 평가 기법이 적용 가능한 확률수문량을 도출함으로써 추후 연구를 위한 기반을 마련하였으며 유역의 수문학적 특성과 가뭄사상의 지속기간 및 심도를 동시에 고려함으로써 보다 현실적이고 정확한 위험도 평가가 가능할 것으로 기대된다.
