

1. 서 론
2. 해수담수화 공정 및 선행연구 고찰
2.1 해수담수화 공정 소개
2.2 머신러닝 소개
3. 모델 구축
3.1 대상지역의 선정
3.2 기초자료 조사 및 EDA
3.3 예측 모델 구축
3.4 해수담수화 시설 전력비 비교
4. 결 론
1. 서 론
우리나라는 세계보건기구(World Health Organization, WHO)에 보고된 물 부족 국가 중 하나로, 최근에는 이상 기후로 인하여 가뭄이 자주 발생하며, 그 규모 및 피해도 증가하고 있다. 여름철에 태풍 및 강우가 집중적으로 발생하는 우리나라 기후 특성상, 대부분의 수자원이 하천을 통해 바다로 방류되므로 여름철을 제외한 기간은 물이 부족한 실정이며, 환경오염으로 인한 사용할 수 있는 수자원 또한 점차 감소하고 있어, 물 부족으로 새로운 대체 수자원 개발이 논의되고 있다. 다양한 대체 수자원 중 해수담수시설이 해결 방안의 하나로 검토되고 있으며, 우리나라는 삼면이 바다와 접해 있어, 지리학적으로도 해수담수화 추진이 용이하다(Kim and Oh, 2008; K-water, 2019; Lee and Park, 2020).
최근 반도체 및 중화학산업 기술의 발전으로 인한 산업용수 수요는 급격히 증가하고 있으며(K-water, 2019; Kwon et al., 2020), 산업용수가 확보되지 않으면 산업단지 개발이 될 수 없기에 수자원 확보가 최우선적으로 고려되기 때문에, 안정적이고 양질의 수자원을 지속적으로 공급할 수 있는 해수담수화 공법은 물 공급의 좋은 해법이 될 수 있다.
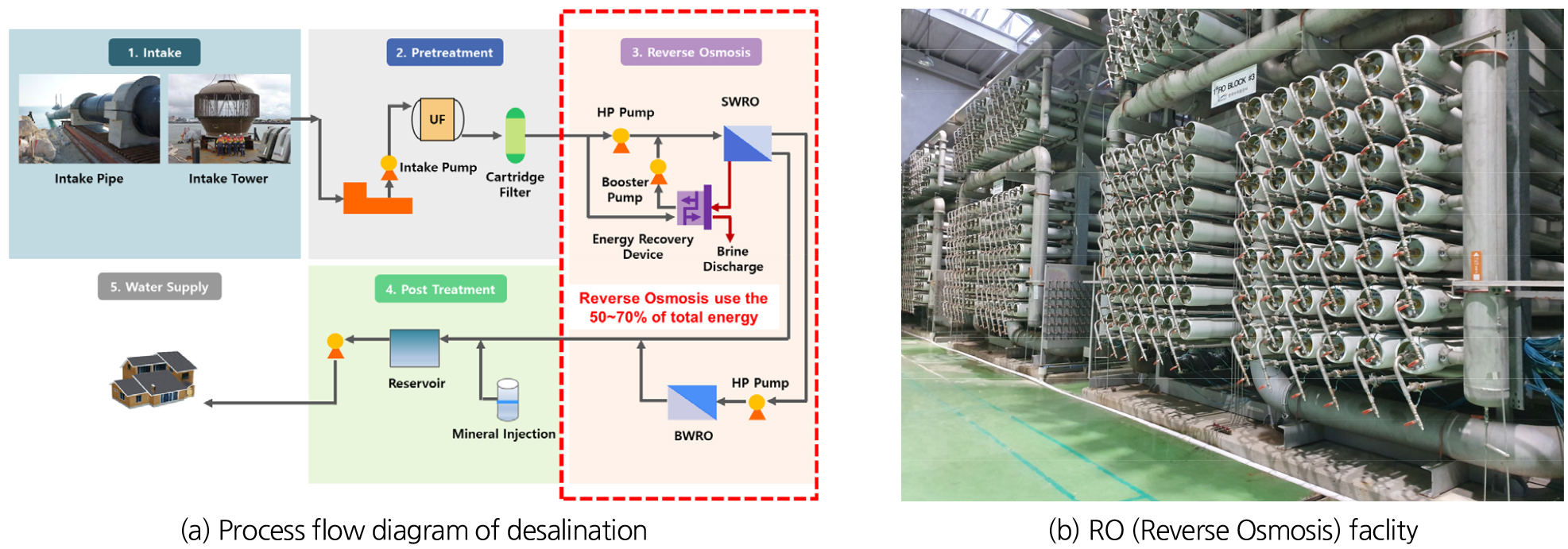
해수담수화 공법은 증발(Thermal Process) 및 막(Membrane Process)으로 구분되며, 기존 해수담수화 연구는 전처리 공법, 해수담수화 공정별 전력비 소모율, 역삼투압 공정 전력비 및 운영 전력비 효율 최적화 등에 대해서 주로 이루어졌다. 전력비(Specific Energy Consumption, SEC)는 가정 또는 산업단지에 물 공급을 위한 생산수의 체적 당 필요한 전력(kWh/m3)을 말한다. 최근 해수담수화 시설 경향은 경제적인 역삼투(Reverse Osmosis, RO) 공법으로 주로 적용되며(Greenlee, 2009), Desalination Market 2016(GWI, 2015)에 의하면 향후 발주되는 프로젝트의 약 90%가 역삼투 공법으로 진행될 것으로 예측하였고, 증발법에서 막공법으로 공정이 변화하면서, 해수담수화에 사용되는 전력은 22 kWh/m3에서 3 kWh/m3까지 낮아져, 약 90% 정도의 절감효과가 있다고 평가했다(Bernat et al., 2010; Badruzzaman et al., 2019). Kurihara and Takeuchi (2013)은 해수담수화 시설의 에너지를 절감하기 위해 저압막 개발, 에너지 회수장치(Energy Recovery Device, ERD) 및 역삼투 공정 시스템의 필요성을 검토하였으며, Fritzmann et al. (2007)은 해수담수화 공법별 에너지 비율을 조사하고, 많은 유량을 통과시킬 수 있는 막 및 에너지 회수장치의 개발로 전력비가 낮아졌다고 분석하였다. Voutchkov (2018)는 해수담수에 소요되는 에너지는 취수공정 5%, 전처리공정 10%, 역삼투공정 70%, 기타 25%로 평가하였으며, 전체 전력비 중 역삼투 공정 전력비 비중이 가장 높은 것으로 연구하였다. 일반적인 해수담수화 소요 전력은 기수 0.3-2.6 kWh/m3, 해수 2.5-4.0 kWh/m3로 나타나고 있으며, 전력비 예측에 주요인자인 해수 수질은 태평양, 대서양 및 지중해는 TDS 35-38 psu, 수온 9-35℃, 중동지역은 TDS 40-45 psu, 수온 16-35℃로 적용되며, 막 제조사의 프로그램을 통해 전력소모량(kWh/m3)을 평가한다(Voutchkov, 2010). 최근에는 인버터펌프 운전으로 에너지를 절감하고 해수담수시설의 운영 최적화를 통한 운영비 절감에 대한 연구가 진행되고 있다(Woo and Kim, 2017; Suh et al., 2015).
기자재 개발 및 다양한 해수담수 관련 공법의 개선으로 해수담수화에 사용되는 전력비는 점차 감소되고 있으며, 운영비를 낮추기 위해 다양한 기술을 도입하고 있다. 그러나 이러한 시설 운영에 필요한 해수담수화 전력비는 낮아지더라도 그 한계가 있으며, 최근에는 기상이변으로 인한 해양 수질 조건이 많이 변화하고 있어, 이를 고려한 최적화된 시설물 계획이 필요하다. 특히, 인프라 시설은 그 특성상 한번 시공이 완료되면 최소 20~30년간 지속적인 운영이 되며, 시설 확장 또는 주요 공정 변경이 쉽지 않으므로, 계획 초기단계부터 자세한 검토가 필요하다. 또한 전력비에 가장 큰 영향을 주는 역삼투공정(약 50~70%)의 운영 전력비 예측은 매우 중요하다. 본 연구는 머신러닝 기법을 활용하여 해양관측소에서 측정된 해수 수질 자료를 활용하여 장래 해수수온 및 염분도를 예측하였고, 모델 구축시 시행-오차법(Trial & Error)을 통해 최적의 신경망 네트워크 구조를 적용하여, 해수의 변동된 값을 결정한 후 관측된 측정 값과 검증을 실시하였다. 머신러닝 알고리즘을 활용한 해수 수질 예측모델 관련 선행연구들은 주로 해양 수질 변화에 대해 조사하고, 해양 수질 변화에 따른 해수담수화 시설의 영향을 검토한 사례가 없으므로, 본 연구에서는 장래 해수 수질 변화에 따른 해수담수 전력비를 산정하고, 이를 고려한 해수담수화 시설의 적정 설계 방법을 제안하고자 한다.
2. 해수담수화 공정 및 선행연구 고찰
2.1 해수담수화 공정 소개
해수담수화 시설은 Fig. 1과 같이, 취수, 전처리, 역삼투, 후처리 및 용수공급 공정으로 이루어진다. 취수공정은 취수시설을 통하여 해수를 취수하여, 펌프 및 배관으로 전처리설비까지 공급하는 시설이다. 전처리 공정은 역삼투압막의 막힘을 방지하기 위하여, 해수 부유물 및 입자성 물질을 제거하고 역삼투압막으로 처리하기 좋도록 전처리하는 시설이다. 역삼투 공정은 펌프, 역삼투막, 에너지회수로 이루어지며, 역삼투막으로 생산수 및 농축수로 분리되어진다. 생산수는 pH와 경도가 낮아, 이를 보완하기 위해 미네랄을 주입하여 소비자에 공급되며, 농축수는 해양으로 방류된다. 이 중 역삼투압 공정은 전체 시설의 약 50~70% 전력을 소비하기 때문에, 역삼투압 공정의 전력비를 예측하는 것은 매우 중요하다. Voutchkov (2010)은 역삼투 공정에서 중요한 인자는 수온 및 염분도로 보았으며, 이는 경험적으로 수온 1℃ 증가할 때 유량은 3%가 증가되고, 영향은 막의 투과유량은 압력과 수온에 비례하며, 염분 제거는 수온에 반비례하는 것으로 연구되었다. 기초 입력자료는 국립해양조사원(Korea Hydrographic and Oceanographic Agency, KHOA)의 2003년부터 2014년까지 측정된 자료를 활용하였다. 전력비는 물리화학식에 근거한 삼투압 계산식을 이용하여 산정하였고, 장래 수온 및 염분도는 다양한 머신러닝 알고리즘을 적용하여 최적값을 예측할 수 있는 모형을 구축하였다.
2.2 머신러닝 소개
2.2.1 머신러닝의 기본개념
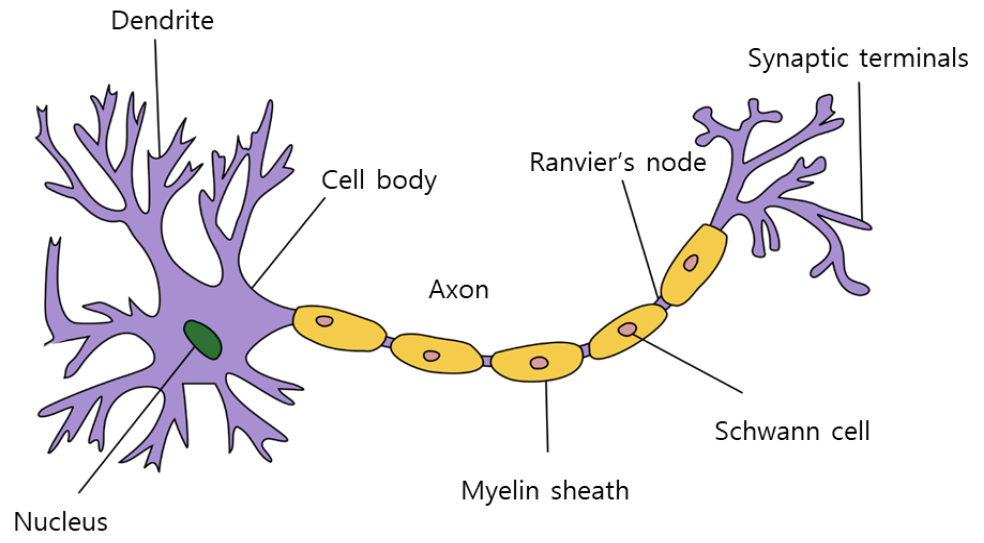
머신러닝은 신경망 알고리즘의 한 분야로, 최근에는 딥러닝이라는 용어로 많이 사용되고 있다. 신경망이라는 이름에서와 같이 뇌의 신경세포 구조를 모방한 알고리즘이며, 이를 바탕으로 Rosenblatt et al. (1957)이 1957년 제안된 퍼셉트론(Perceptron) 이론은 딥러닝 및 머신러닝 알고리즘의 기초가 되었다. 하나의 퍼셉트론은 하나의 신경세포, 즉 뉴런(Neuron)을 의미하며 Fig. 2와 같이 나타낼 수 있다. 퍼셉트론 알고리즘은 뉴런 한 개에 X1, X2의 정보가 들어오게 되면 각각의 가중치 W1, W2를 곱한 후 전체를 더한 값이 출력되며, 결과 값은 X1·W1+X2·W2가 된다. 그 결과 값은 다음 차례의 뉴런으로 전달되는 과정을 반복하게 되며 처리하는 정보는 단순하지만, 많은 수의 뉴런이 얽혀서 복잡한 정보를 가공할 수 있게 된다.
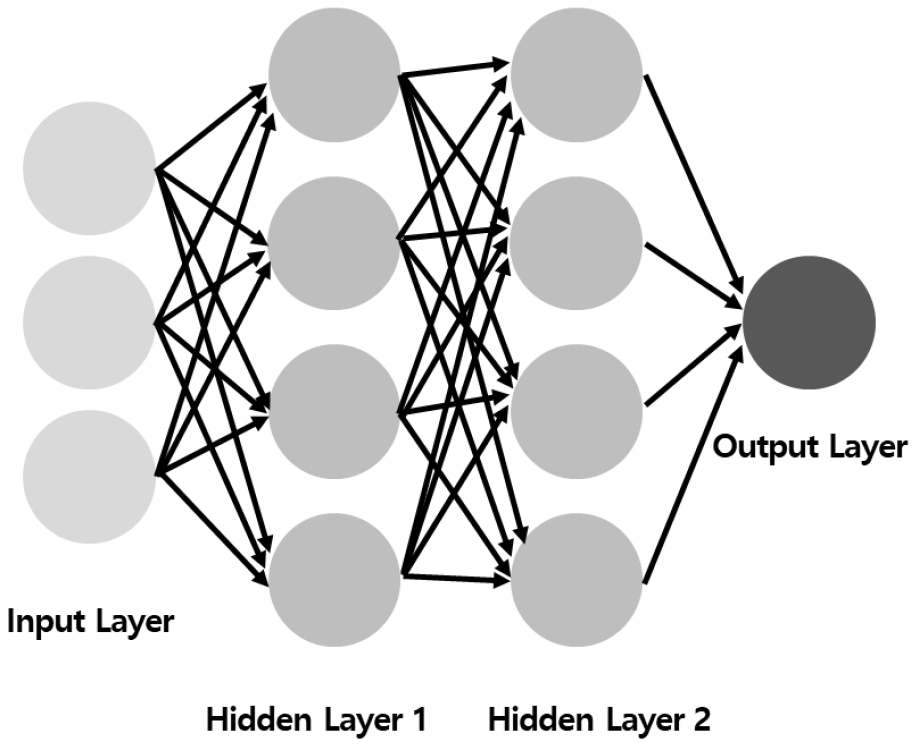
신경망은 Fig. 3과 같이, 입력 계층(Input Layer), 은닉 계층(Hidden Layer) 및 출력 계층(Output Layer)으로 나뉘며, 일반적으로 은닉 계층이 한 개일 때 얕은 신경망(Shallow Neural Network), 두 개 이상은 깊은 신경망(Deep Neural Network)이라고 부른다.
2.2.2 머신러닝 처리과정
앞에서 언급된 머신러닝 알고리즘을 간단하게 설명하면, 뉴런에 정보가 입력된 후, 가중치에 의해 결과가 조절되어 출력되며, 간소화된 모식도는 Fig. 4와 같다. 뉴런은 노드(Node)로 표기하며, 입력된 값에 가중치 및 활성 함수를 고려한 출력값을 다음 노드로 전달한다. 가중치 및 바이어스는 입력값을 조정하며, 가중치는 Eq. (1)의 기울기, 바이어스는 상수 역할을 하게 되며, 활성 함수는 다음 단계로 전달되는 과정을 결정한다. 즉, 노드는 신경세포인 뉴런에서 자극이 역치를 넘을 때 반응하는 기작을 모방하였다(Tariq, 2016).
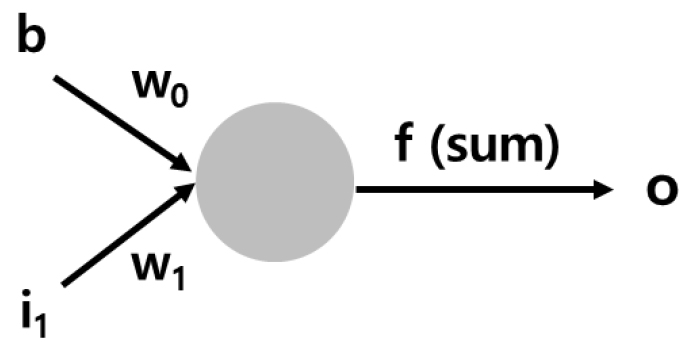
o : 출력값(Output)
f : 활성함수(Activation function)
b : 바이어스(Bias)
w : 가중치(Weight)
I : 입력(Input)
학습과정에서 각각의 가중치는 관측치와 예측치의 오차를 최소화하도록 가중치를 최적화한다(Cho et al., 2011; Oh, 2008). 학습할 때에는 오차 계산 후 전 단계보다 오차가 큰 경우 학습을 종료하며, 이 과정을 여러 번 반복해 최적화된 가중치를 선정한다(Oh, 2008; Mitchell, 1997). 학습 전에 신경망의 네트워크 구조를 먼저 검토해야 하며, 같은 자료를 적용해도 구조를 어떻게 설정하느냐에 따라 모델의 성능이 달라진다. 이를 조정(Regularization)이라 부르며, 아직은 정형화된 방법이 없기에 시행-오차법(Trial & Error)을 사용한다. 입력자료 종류, 은닉층 개수, 은닉층의 노드 개수 및 활성함수 종류를 정해야 하며, 복잡한 구조와 고급 알고리즘이 항상 좋은 결과가 나타나지 않는다(Oh, 2008). 즉 네트워크를 결정하는 변수가 많으면 학습은 잘 되지만, 일반화 성능이 낮아져 결과 예측력이 떨어지며, 변수가 적으면 적절한 학습의 진행이 어려울 수 있다(Duda et al., 2001).
2.2.3 RNN (Recurrent Neural Network)
RNN은 순환신경망이라고 하며, 연속된 관측치가 서로 연관성이 있을 때 사용하는 알고리즘이다. 문장 구조 및 시계열 분석에서 많이 사용되며, 특정 시점의 상태를 저장 후, 각 시점의 입/출력에 의해 변화가 발생한다. RNN 기본구조는 Fig. 5와 같고, 이는 Eq. (2)와 같이 나타낼 수 있다.
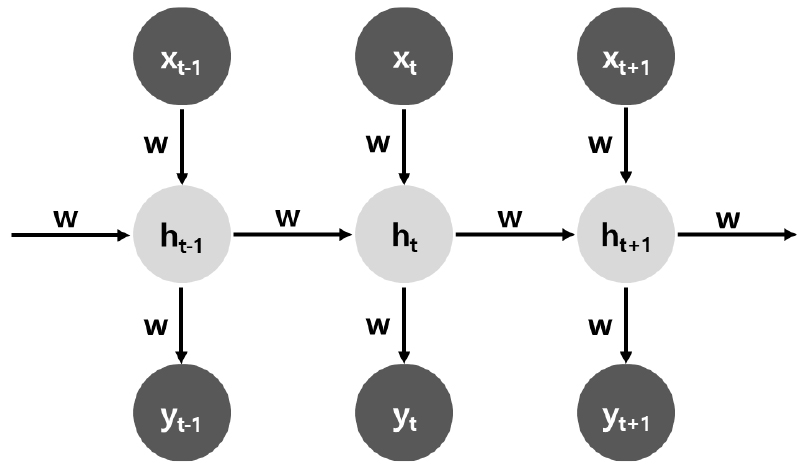
특정 시점의 상태(ht)가 존재하면, 현재 상태(ht)는 직전의 상태(ht-1)과 현재 입력 데이터(xt)에 영향을 받고, 현재 상태(ht)에 따라 출력(yt)가 결정된다. 즉, RNN 알고리즘은 상태를 가정하고, 이에 대한 순차적인 의존성을 나타내며, 다른 머신러닝 알고리즘과 가장 큰 차이점이다. RNN은 긴 시간의 자료를 기억하기 어려우며, 오래 학습할 경우에는 학습 시간이 길어지는 단점이 있다. 이는 기울기 소실(Gradient Vanishing) 문제로서 RNN이 tanh 함수로 학습하기 때문에 단기간 학습시에는 문제가 없지만, 장기간 학습시에는 기울기가 0에 가까워져 학습 시간이 느려지고, 효율적으로 학습하지 못하여 학습이 마무리되지 않고 수렴하는 문제가 생긴다.
2.2.4 RNN-LSTM (Recurrent Neural Network–Long Short Term Memory)
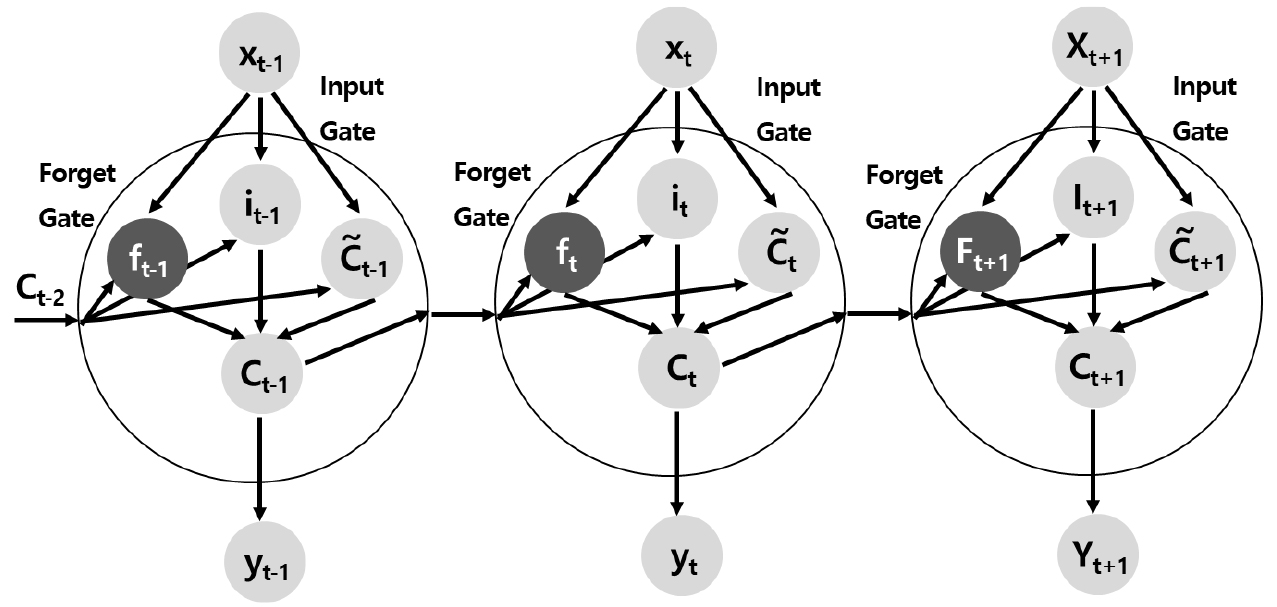
LSTM (Long Short Term Memory)은 RNN의 단점을 해결하기 위해 등장한 알고리즘이며, RNN이 계층이 깊어질 경우, 과거 자료를 학습하지 못하고 최근 자료만 기억하여 학습이 잘 안되는 기울기 소실 문제를 해결하였다. RNN 알고리즘과 가장 큰 차이점은 전 단계의 정보를 계속 전달할지 판단하는 구조가 있는 점이다.
LSTM 알고리즘은 Fig. 6과 같이 나타낼 수 있으며, RNN의 기본 구조(Fig. 6)와 달리 복잡한 구조이며, 입력과 현재 상태를 활용해 내부 정보를 업데이트할지 결정한다. 새로운 자료가 유용할 경우는 업데이트가 적용되고, 별로 유용하지 않으면 지난 단계의 정보를 많이 활용하여 업데이트를 최소화한다. 가장 왼쪽 구조는 망각 게이트로 지금까지 기억한 상태 및 현재 입력값에 계수를 곱해 상태를 전달할지 결정하고, 다음은 입력 게이트로 상태 및 현재 입력값으로 얼마나 전달하지 정하여, 다음 상태를 RNN과 유사하게 추정하게 된다. 이렇게 망각 게이트, 입력 게이트 및 RNN 전과정을 통하여 계산이 되면, 어떤 값을 얼마나 업데이트 할지 정하게 되고 출력은 현재 상태(Ct)와 입력을 적용해서 결정한다.
2.2.5 머신러닝기반 예측모델 알고리즘 및 관련 선행연구
현재 다양한 분야에서 머신러닝과 관련된 연구가 진행되고 있으며, 특히 수질 예측과 관련되어 많은 검토가 되고 있다. Park et al. (2020)은 LSTM 알고리즘을 적용한 하천 고탁도 예측(> 30 NTU)을 통한 상수도 공급 최적화를 연구하였다. Jun et al. (2020)은 낙동강 하류의 유량 및 수질(Chlorophyl-a, BOD, COD, SS) 예측을 하고 신경망 모델이 BRNN 및 SVM 보다 높은 정확도를 가지는 것으로 검토하였으며, 이와 유사한 연구로 낙동강 하류지역 Chlorophyl-a의 수질 예측을 부스팅(Boosting), 디시전트리(Decision Tree), 랜덤포레스트(Random Forest) 등의 알고리즘을 적용하여 비교하였다(Lee and Kim, 2021).
기존 해양 수질 모델링의 경우, 복잡한 인자를 바탕으로 개발되어 정확도가 낮고 구축 비용 및 기간이 많이 소요되었지만, 머신러닝 기반 모델은 수온 및 수질에 대한 물리적인 이해가 필요하지 않기 때문에 최근 많이 활용되고 있다. 해수 수온 및 수질을 추정하기 위해 머신러닝 기반의 모델이 다양하게 연구되고 있고, Jeon et al. (2020)는 머신러닝을 적용한 수질평가지수 예측연구를 수행하였으며, 랜덤포레스트 및 서포트벡터머신(Support Vector Machine) 알고리즘이 다른 머신러닝 알고리즘보다 우수한 성능을 나타내는 것으로 연구하였다. 기존 SVM과 전통적인 회귀 알고리즘은 장기 시계열 패턴을 예측하는데 상대적으로 낮은 성능을 보였다. 반면, 시계열 자료를 모의하는데 특화된 LSTM을 사용한 선행연구들에서 기존의 통계적 방법과 비교해서 상대적으로 우수한 성능을 보였다(Zhang et al., 2017). 또한 합성곱신경망(Convolutional Neural Network)을 LSTM과 단순 결합한 모델인 Fully Connected LSTM (FC-LSTM)이 해수면 온도 예측연구에서 SVM보다 상대적으로 우수한 해수면온도 예측 성능을 보여주었다(Yang et al., 2017). Kim et al. (2014)은 랜덤포레스트, 큐비스트 회귀(Cubist Regression), 서포트벡터 회귀(Support Vector Regression)을 적용하여 위성 데이터 자료로 서해안의수질 농도를 추정하였다.
최근 연구는 위성영상 자료인 SST (Sea Surface Temperature) 데이터를 이용한 고수온 탐지 예측을 LSTM 알고리즘을 적용하여 분석하였으며(Choi et al., 2020; Jung et al., 2020), 기상청 자료를 활용하여 해양수질 및 수온을 서포트벡터머신(Support Vector Machine), 랜덤포레스트(Random Forest) 및 LSTM 알고리즘을 적용하여 예측하는 연구를 수행하였다(Jeong and Park, 2020). 다만 이들 연구는 기간이 30분에서 5일 이내로 비교적 단기간 예측 또는 고수온 탐지만 판별한 점은 연구의 한계로 나타났다.
3. 모델 구축
3.1 대상지역의 선정
대상지역(Fig. 7)인 대산항은 서해 태안반도에 위치하며, 주변에는 예산군, 당진시, 태안군 및 홍성군이 인접하고 있다. 석유화학 및 자동차산업이 주요 산업으로, 1991년 무역항으로 지정되어 LG화학, 한화토탈, 현대오일뱅크, 현대OCI 등의 산업체가 있어 산업용수의 공급이 많이 요구되는 지역이다. 따라서 본 연구의 연구대상 지역으로 적합성을 갖추고 있다.
3.2 기초자료 조사 및 EDA
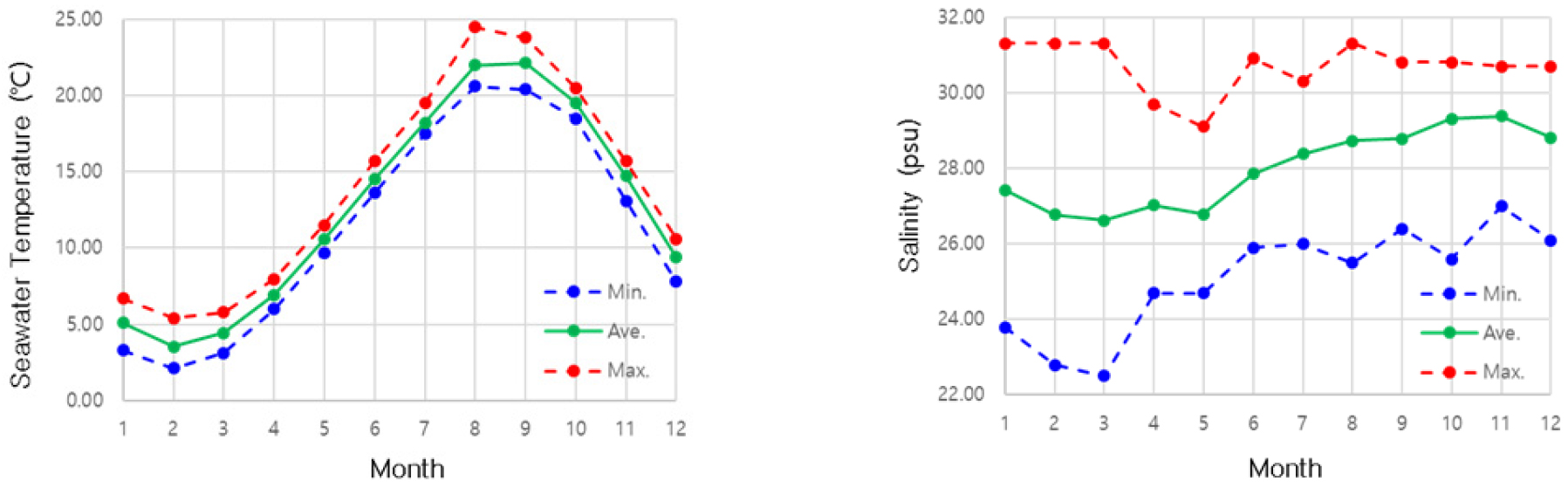
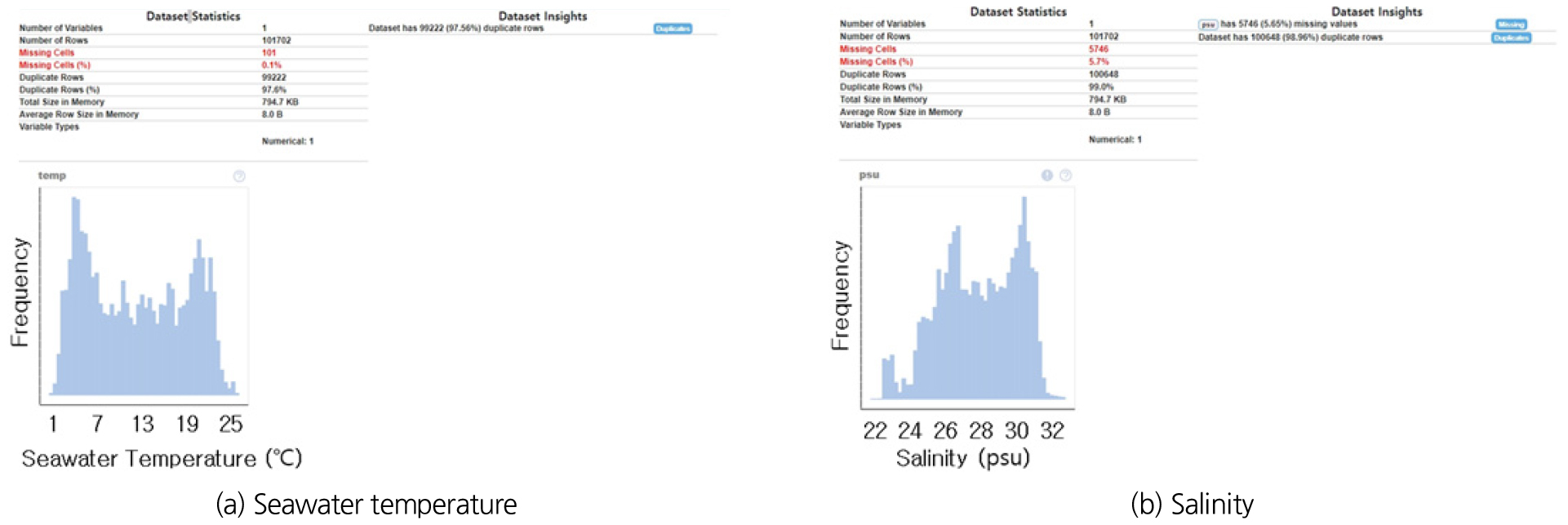
국립해양조사원(Korea Hydrographic and Oceanographic Agency, KHOA) 대산지역의 수온 및 염분도 월별 측정자료는 Fig. 8과 같다. 하절기 태풍 및 동절기 가뭄으로 해수 수온 및 염분도는 계절적인 특징을 가진다. 여름철은 수온이 높고 염분이 낮으며, 겨울철은 수온이 낮고 염분이 높게 나타나며, 수온은 2월에 2.5℃로 가장 낮고, 8월에 24.5℃로 가장 높았다. 염분은 3월에 22.50 psu로 가장 낮고, 1월에 31.30 psu로 가장 높았다. 국가 해양환경 정보통합시스템(MEIS, Marine Environment Information System) 해수 수온은 1.1~25.5℃, 평균 13.1℃로 나타났고, 염분은 평균 31.16 psu로 28.32~32.95 psu의 값을 나타났다. 국립해양조사원(KHOA) 자료는 국가해양환경정보통합시스템(MEIS) 자료와 비교하면 수온은 약 4%, 염분은 약 10% 낮았으며, 측정 장소가 항구 주변에 설치되어 지표수 유입에 대한 영향이 나타나는 것으로 검토되었다.
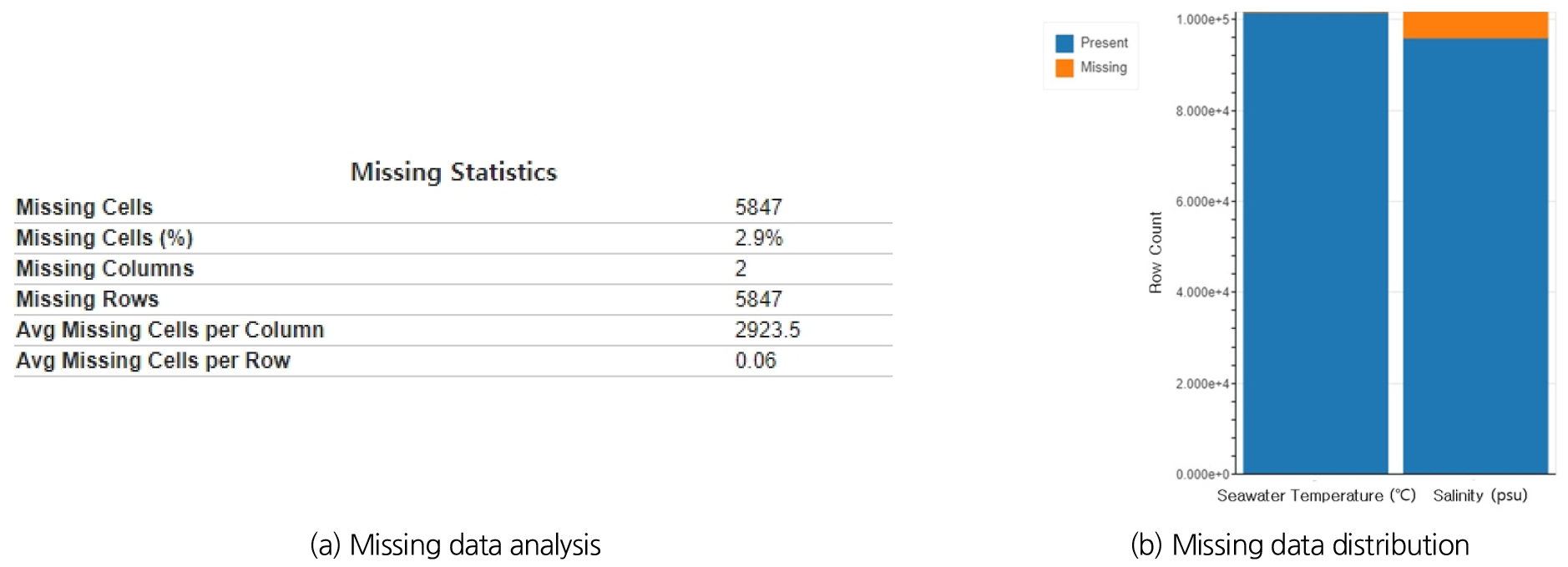
국가 해양환경 정보통합시스템(MEIS) 자료는 1997년부터 2020년(24년)까지 조사되어 가장 오랜 기간동안 측정된 값이 있지만, 연간 4회 자료가 측정되어 총자료의 수가 많지 않아 예측 모델의 입력자료로 사용하기에는 부족하다고 판단되었으며, 금회 모델은 자료는 2003년부터 2014년까지 1시간 간격으로 측정된 자료(약 10만건)가 있는 국립해양조사원(KHOA)의 실시간 데이터를 적용하였다. 주요 변수, 결측치 비중 등을 활용하기 위해 탐색적 데이터 분석(Exploratory Data Analysis, EDA)를 실시하였으며, 결측치를 제외한 자료의 개수는 수온자료 101,601건, 염분도 95,956건으로 나타났다. 각 자료의 분포는 Fig. 9와 같고, 수온의 결측치는 101건(0.1%), 염분도의 결측치는 5,746건(5.7%)으로 나타나, 염분도 결측치가 수온에 비해 다소 많지만 전체 자료의 5% 수준이므로 모델 구축을 하는데 큰 문제는 없는 것으로 판단하였다.
결측치 분포를 상세하게 검토하기 위해 수온 및 염분도에 추가적인 분석을 실시하였으며, 결측치 비중은 Fig. 10과 같이 나타난다.
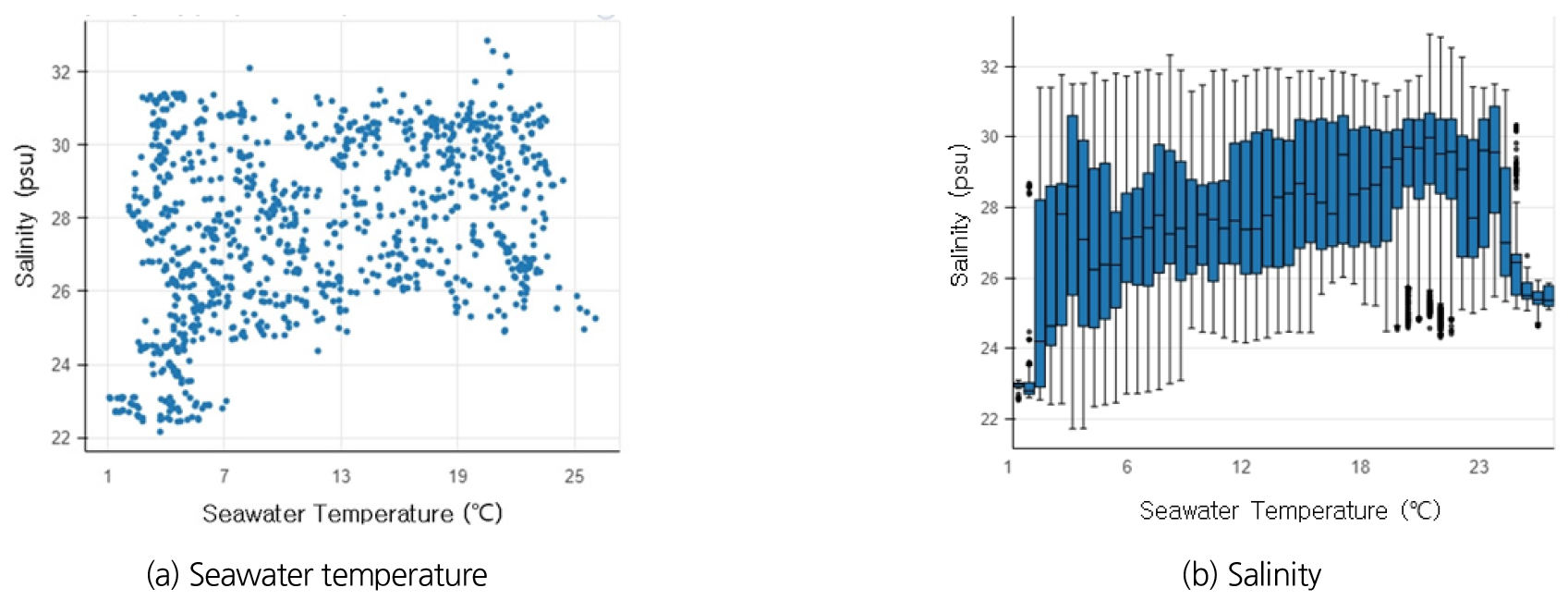
수온 및 염분도와 상관관계를 검토하기 위해 자료를 분석하였고, Fig. 11과 같이 수온 및 염분도는 큰 상관관계가 없는 것으로 검토되었다.
3.3 예측 모델 구축
대산지역의 2003년부터 2014년까지의 월별 수온 및 염분도는 Tables 1 and 2와 같다.
Table 1.
Monthly seawater temperature in Daesan (2003~2014)
Table 2.
Monthly salinity in Daesan (2003~2014)
해양수질(수온, 염분도) 예측을 위해 딥러닝 모델을 구축하였으며, 구글에서 무료로 제공되는 Tensorflow를 활용하였다. Tensorflow는 오픈소스 프로그램으로서 데이터 흐름 그래프를 사용하며, 그래프 노드는 수학 연산, 그래프의 선은 노드 간에 전달하는 데이터 배열(Tensor)를 나타낸다. Keras API를 통해 CPU 또는 GPU로 연산이 가능하며, Tensorflow 라이브러리를 기반으로 RNN-LSTM 딥러닝 모델을 구축하였다. Python Language로 개발되었고, 각 패키지 모델은 딥러닝 모델을 구축할 때 적용되며, Numpy, pandas, seaborn은 데이터 가공 및 계산용, matplotlib는 수식을 그래프로 나타내기 위한 패키지이며, 모델 구축 시스템 사양 및 사용된 패키지 정보는 Tables 3 and 4와 같다.
Table 3.
System specifications for model building
| Item | Description |
| OS | Window 10 |
| Programming Tool | Google Colab Pro |
| Language | Python 3.7.10 |
| Deep Learning Library | Tensorflow 2.5.0 |
| Deep Learning API | Keras 2.5.0 |
| Algorithm | RNN-LSTM |
Table 4.
Python package information
| Package program | Version |
| numpy | 1.19.5 |
| pandas | 1.1.5 |
| matplotlib | 3.1.1 |
| seaborn | 0.11.1 |
구축된 모델은 시계열 자료 길이에 따른 가중치 손실을 막기 위해 RNN-LSTM 모델을 적용하였다. 전체 Data Set에서 Training Set (Training & Validation) 80%, Test Set 20%로 구분하여 학습을 진행하였고, 대산지역의 2003년부터 2014년까지의 수온 및 염분도 자료를 활용하여 장래 예측(6년) 수행하였다. 학습 횟수는 1000회로 설정하였으며, 오차함수로 mean_squared_error, 안정적인 학습을 위해 최적화(optimizer) 함수는 선행연구에서 많이 적용되며 일반적으로 사용되는 adam을 선정하였다(Xiao et al., 2019). Activation 함수는 relu를 사용하였으며, 모델 실행 이전에 성과를 저장하고, 5회 이상 모델의 성과 향상이 없으면 최적화 단계에서 자동으로 학습을 중단하여 과적합을 방지하는 알고리즘(early_stop)을 적용하였다.
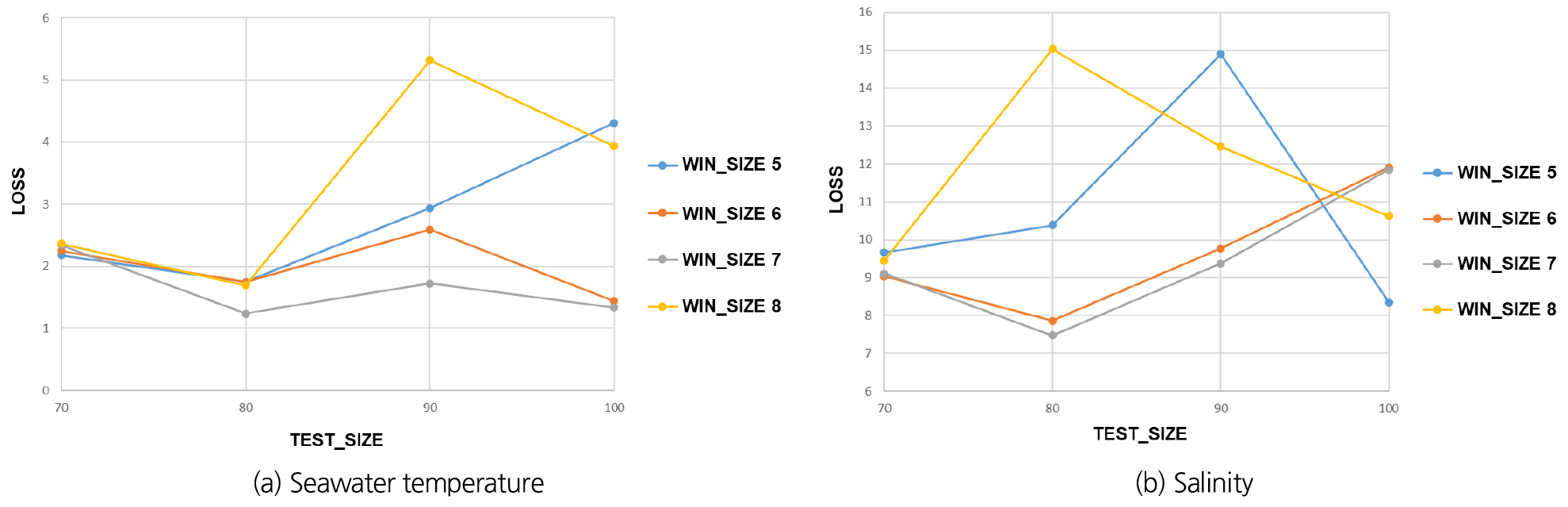
모델 성능 최적화를 위해 하이퍼파라미터 튜닝은 Test Size (1회 학습시킬 데이터 개수) 및 Win Size (예측 값 이전에 연속적으로 입력되는 자료 개수)를 검토하였으며, 수온에 대한 Loss 값은 1.24097~5.31512, 염분도는 7.47934~15.02981로 분포되었고, Fig. 12와 같이 TEST_SIZE는 80, WIN_SIZE는 7일 때 Loss 값이 가장 낮게 나타났다.
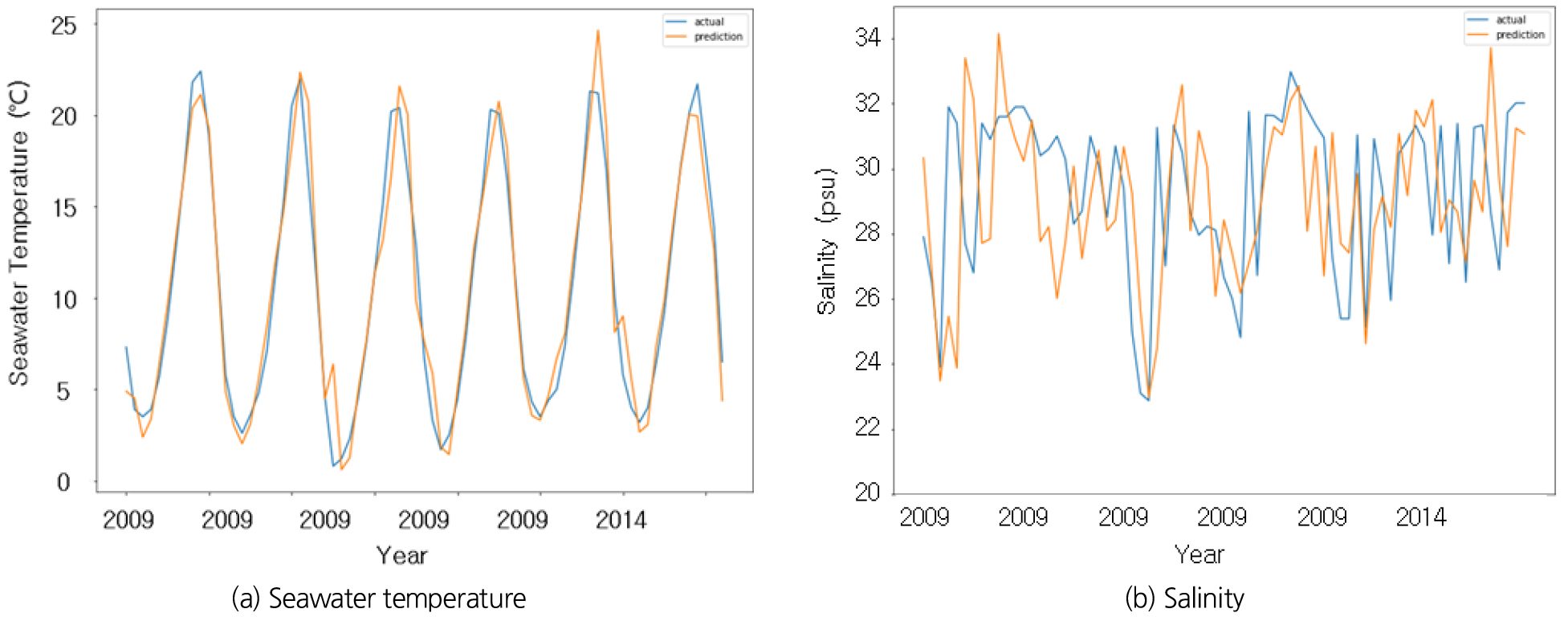
RNN-LSTM은 신경망 모델중에서도 시계열 예측에 뛰어난 것으로 알려져 있으며, 이전의 시간차를 이용해 미래를 예측하기 때문에 자료가 주기성(Seasonality) 및 자기상관성(Autocorrelation)이 높을수록 예측이 정확해진다. 예측된 값의 성능 비교를 위해 수정결정계수(adj. R2), 평균제곱근오차(Root Mean Squre Error, RMSE), 절대오차(Mean Absolute Error, MAE)를 검토하였고, 금회 검토된 대산지역의 수온은 adj. R2 0.9398, RMSE 1.5989, MAE 1.1827, 염분도는 adj. R2 0.1151, RMSE 2.3429, MAE 1.9996로 계산되었다. Fig. 13(a)와 같이 수온은 일정한 주기성을 가지고 있지만, Fig. 13(b)와 같이 염분도는 태풍 및 집중호우 등에 의한 하천 방류량에 대한 영향이 있어 예측 정확도가 상당히 낮아지고, 예측 값이 불규칙하게 나타났다. 그러나 향후 해안에서 먼 곳에서 해수가 취수된다면 하천 및 담수 영향이 적어지기 때문에 염분도 예측 정확도가 향상될 것으로 판단된다.
3.4 해수담수화 시설 전력비 비교
염분 및 수온 장래 데이터 예측값(2015~2020년)과 기존자료(2003~2014년)를 반영한 전력비 비교를 위해 물리화학식을 적용하여 검토하였다(Kim and Youm, 2019; K-water, 2019; Voutchkov, 2010). 주요 고려사항은 염분도, 수온, 유입수 성상, RO 공정구성 및 막 종류 등이 영향을 미치며, 염분도 및 수온 이외에는 설계단계에서 선정되기 때문에 염분도 및 수온에 대한 변화만 고려하였다. 세부적으로 적용된 내용은 Table 5와 같이 기존에 검토된 K-water (2019) 보고서를 참조하였으며, 대산해수담수화 시설의 용량은 일평균 기준 100,000 m3/d, 총 11개 계열(1개 예비)로 구성되어 한 계열 당 10,000 m3/d 으로 구성된다.
Table 5.
RO process (K-water, 2019)
역삼투 공정에서 삼투압은 회수율에 따라 염분이 농축되면 증가한다. 농축된 염분도(TDSc, psu), 원수 염분도(TDSf, psu), 생산수 염분도(TDSp, psu) 및 회수율(Pr, %)로 나타낼 수 있고, Eq. (3)과 같다. 기존 대산지역 자료(2003~2014년) 원수 최대 염분도 32.98 psu, 회수율 50%, 생산수 염분도 0.2 psu를 적용하면, 농축된 염분도는 65.76 psu로 나타난다.
온도가 증가함에 따라 삼투압도 증가하게 되며, 해수의 삼투압(Po, bar), 기체상수(R, 0.0809(L·bar)/(mol·K)), 수온(T, ℃), 해수 이온농도의 합(mi)으로 나타낼 수 있으며, Eq. (4)와 같다. 기존 대산지역 자료(2003~2014년) 최소 수온 0.8℃, 해수 이온농도 2.0927(= 65.76 psu / 35 psu × 1.1135)를 적용하면, 삼투압은 46.35bar로 계산된다.
역삼투압 공정에 소모되는 전력(Ppump)은 Eq. (5)과 같이, 펌프 유량(Q, m3/min), 양정(H, m), 효율(), 여유율(, 0.1~0.15)로 계산될 수 있으며, 기존 대산지역 자료(2003~2014년) 1개 계열의 유량 6.9444 m3/min, 양정 463.5 m, 펌프효율 0.84, 여유율 0.15을 고려할 경우, SWRO 전력비는 1.72 kWh/m3로 계산되었다. 총 전력비는 SWRO 전력비의 약 45%(BWRO 전력비 30%, 기타 15%)를 할증한 2.50 kWh/m3로 검토되었으며(K-water, 2019), 장래 예측된 수질자료를 반영한 전력비는 Table 6과 같다.
기존 대산지역 2003년부터 2014년까지의 최소 수온은 0.8℃, 최대 염분도 32.98 psu이며, 금회 예측된 장래 최소 수온은 1.1℃, 장래 최대 염분도는 32.67 psu로 나타나 과거의 최소 또는 최대 값을 크게 벗어나지 않는 것으로 검토되었다. 해수담수화 전력비는 Table 6과 같이 기존 2.50 kWh/m3에서 금회 2.48 kWh/m3로, 약 0.02 kWh/m3가 감소 되었으며, 해수담수화에 필요한 전력은 장래에는 약 0.80% 줄어드는 것으로 나타났다.
현재 계획된 시설물은 적정한 것으로 판단되며, 장래 해수담수화 시설을 운영할 경우에는, 해수 수질변화를 고려한 시설물 운영방안이 필요할 것으로 검토되었다. 운영 최적화는 펌프의 효율을 최대화 할 수 있는 방안이 필요하기 때문에, 향후에는 해수담수시설 펌프 효율을 최적화 할 수 있도록, 더 많은 자료와 다양한 예측 모델을 적용한 연구가 필요할 것으로 판단된다.
Table 6.
Power consumption comparison of existing and prediction value
4. 결 론
본 연구를 통하여 머신러닝 기반의 전력비 예측을 통한 에너지 절감 방안을 모색하고, 기존 설계에 대한 대안을 제시하여, 해수담수화 시설의 규모가 과대 또는 과소하게 계획되는 것을 사전에 검토할 수 있었다. 해수담수화 공정에서 가장 많은 에너지를 소모하는 역삼투압공정의 전력비를 예측하기 위한 모델을 구축하고, 입력 자료는 국립해양조사원(KHOA)의 2003년부터 2014년까지 수집된 대산지역의 1시간 간격의 자료(약 105,000건)를 적용하였다. 수온은 월평균 수온은 최저 0.77℃, 평균 15.63℃, 최대 25.97℃이며, 월평균 염분도는 최저 24.12 psu, 평균 31.04 psu, 최대 32.98 psu로 나타났다.
전체 자료는 학습(Training Data, 80%) 및 테스트(Test Data, 20%) 자료로 구분하여, 주요 인자인 해수 수온 및 염분도에 대해 예측하였다. 장래 수온 및 염분도는 시계열의 자료 길이에 따른 가중치 손실을 막기 위해 RNN-LSTM 알고리즘을 적용하여 예측할 수 있는 머신러닝 기반의 모델을 구축했으며, 예측된 값은 테스트 자료와 검증하였다. 하이퍼파라미터 튜닝은 Loss 함수를 최소화하는 값을 비교하고, 최적화하는 방향으로 Test Size 및 Win Size 튜닝을 수행하였으며, Loss 값은 수온 1.24097, 염분도 7.47934로 나타났다.
장래 해양수질을 예측한 결과, 일정한 주기성 및 자기상관성이 높은 수온의 경우 예측이 상대적으로 잘되는 것으로 나타났고, 염분도는 폭우 및 태풍 등의 영향을 받아 불규칙한 패턴이 발생하여 Loss 값이 다소 높게 나타났다. 해수담수화 전력비는 염분도, 수온, 유입수 성상, RO 공정구성 등 전체적으로 고려하여 계산되었고, 과거자료 기준 2.50 kWh/m3, 금회 예측된 수질 기준으로는 2.48 kWh/m3로 나타나 해수담수화 전력비는 0.80%가 줄어드는 것으로 예측되었다.
최근 경영환경이 급격하게 변하고 있으며, ESG (Environment, Social, Governance)가 중요한 고려사항이 되고 있다. 향후 사회기반시설을 계획할 때에는 친환경, 사회적 책임 경영, 지배구조 개선 등 사회책임투자 및 지속 가능한 투자와 같이, 다양한 기준이 고려되어야 하며, 특히, 에너지를 많이 사용하는 건설 및 환경 플랜트는 이러한 요구는 점차 더 강해질 것으로 판단된다. 따라서, 전력비 최소화를 위한 운영 최적화는 앞으로도 풀어야 할 과제로 더 많은 연구가 필요하다. 본 연구에서 구축된 모델로, 해수담수화 시설의 운영전력비를 낮추면, 탄소 발생이 그만큼 줄기 때문에 운영자 입장에서는 에너지 절감으로 인한 경제적 이익뿐만 아니라, 탄소세 및 기업 이미지 제고 등의 부가적인 수익도 창출할 수 있을 것으로 검토되었다.
지금까지 장래 해수담수 시설물 규모에 대한 적절한 평가 방법 및 대안 제시가 없었기 때문에, 해수 온도 및 염분도 과거 자료를 활용하여, 역삼투압의 전력비를 예측하는 모델 개발 및 장래 해수의 수질 변화에 따른 전력비를 제안하였다는데 의의가 있다. 다만 본 연구에서 적용된 입력자료의 측정 기간이 짧고, 대상지역이 대산으로 제한된 점은 한계점으로 나타났다. 이번 연구에서는 장래 수질예측 모델을 구축하고 검토하는데 집중하였으며, 향후 연구에서는 이를 보완하여 다양한 지역의 해양관측소 자료 활용하고 장래 해수담수시설의 수집되는 수질 자료를 추가로 적용한다면 보다 신뢰성 있는 예측 모델을 구축할 수 있을 것이다.
머신러닝을 기반으로 한 빅데이터 분석을 산업 혁신과 변화에 적극적으로 적용하는 전략이 검토되어야 하는 시점에서 본 연구를 기반으로 다양한 예측모델 알고리즘을 검토하고 개발해 나갈 수 있을 것이다. 이러한 과정을 통해 해수담수 전력비 예측 모델의 정확도는 더욱 높아질 것이며, 시설물의 설계를 최적화하여 에너지 비용 절감에 기여할 것으로 기대된다.
