

1. Introduction
2. Methodology
2.1 Shallow Water Equations (SWE)
2.2 Physics-informed Neural Networks (PINNs)
3. Experiments
3.1 Nonbreaking wave propagation
3.2 Dam breaking
3.3 Setting-up experiment
4. Results and Discussion
4.1 Dose the PINN method effectively approximate the outcomes of the conventional method?
4.2 How PINNs deal with the existence of discontinuous and shocking?
4.3 What are the comparative advantages of the PINN in contrast to the ANNs?
4.4 How does the spatial distribution of collection points influence the ultimate outcomes?
4.5 Limitations and Future Work
5. Conclusions
1. Introduction
The Shallow Water Equations (SWE)(de Saint-Venant, 1871) serve as a core mathematical model for describing the behavior of water flow in rivers, lakes, estuaries, and coastal regions (Bates et al., 2005; Hodges, 2019; Soares-Frazao et al., 2012). These equations, derived from the principles of conservation of mass and momentum, are widely used in hydrology, hydraulic and environmental engineering for predicting water levels, velocities, and the propagation of waves in such natural water systems (Bates et al., 2010; Ferrari et al., 2019; Van et al., 2016; Viero and Valipour, 2017).
Traditionally, numerical methods have been employed to solve SWE, such as finite difference (Kuffour et al., 2020; Lundgren and Mattsson, 2020), finite volume (An and Yu, 2014; Bermúdez et al., 1998; Cea and Bladé, 2015), and finite element methods (Ayog et al., 2021; Hai et al., 2008; West et al., 2017). Although these methods have made substantial contributions, they also demand greater effort and necessitate a profound comprehension of the inherent characteristics of SWE, including nonlinearity (Valiani and Caleffi, 2019), discontinuity, and shockwaves (Lu et al., 2020; Marras et al., 2018).
In recent years, machine learning (ML) and deep learning (DL) have received a lot of attention for the solution of partial differential equations (Beck et al., 2019; Han et al., 2018; Sirignano and Spiliopoulos, 2018). Furthermore, there have been also attempts to apply data-driven-based algorithms for the solutions of problems related to SWE (Guo et al., 2021; Kabir et al., 2020; Liu and Pender, 2015). In this type of approach, ML and DL are used to approximate the non-linear relationship between inputs and outputs obtained by numerical solver or simulated models. These models are generally referred to as surrogate models. However, one of the limitations of this approach is that the surrogate model often requires a sufficiently large amount of data in the training process (Vijayaraghavan et al., 2023). It could be computationally expensive to achieve data for training.
A novel computational framework has emerged, leveraging the power of physics-informed neural networks (PINNs), which combines the strengths of deep learning and governing physics equations to provide a robust and efficient approach to solving complex problems in various scientific and engineering problems (Lu et al., 2021; Mao et al., 2020; Raissi et al., 2019). One of the key advantages of PINNs is their ability to handle partial differential equations (PDE) with complex boundary conditions and spatiotemporal dynamics. Meanwhile, traditional numerical methods often struggle with high dimensionality, requiring significant computational resources and effort (Ni et al., 2020; Vacondio et al., 2014). In contrast, PINNs provide an elegant and efficient alternative by learning the underlying physics directly from data (Karniadakis et al., 2021). In addition, PINNs utilize automatic differentiation to represent differential operators, eliminating the explicit requirement for mesh generation (Cai et al., 2021). This data-driven approach circumvents the need for explicit analytical formulations or discretization schemes, making PINNs highly versatile and adaptable to a wide range of problems (Gao et al., 2021; Jagtap et al., 2022; Karniadakis et al., 2021; Lu et al., 2021; Zobeiry and Humfeld, 2021). Furthermore, through the inclusion of constraint PDEs in the loss function, the solutions obtained from PINNs are compelled to adhere to the underlying physics phenomena, facilitating their interpretability (Karniadakis et al., 2021; Ren et al., 2023; Xu et al., 2022).
Despite the substantial growth of research aimed at enhancing the PINNs algorithm, research on PINNs in the field of hydrology and water resources remains relatively scarce (Chen et al., 2023; Feng et al., 2023). Tartakovsky et al. (2020) proposed a PINNs method that estimates hydraulic conductivity in a subsurface flow environment. In a study by Bandai and Ghezzehei (2022), it was shown that PINNs employing locally layer-wise adaptive activation functions can yield solutions to the one-dimensional Richards’ equation that are comparable in accuracy to traditional numerical methods. The seamless integration of deep learning with SWE is also presented in previous studies. Feng et al. (2023) introduced a novel framework capable of assimilating diverse types of observations and directly solving the 1D Saint-Venant Equations. Notably, their study demonstrates the effectiveness of PINN-based downscaling, which incorporates observational data to generate more realistic subgrid solutions for along-channel water depth. The literature reviews discussed above highlight the potential efficacy of PINNs in approximating solutions to SWE. However, despite this potential promise, the widespread adoption of PINNs for solving the SWE system remains somewhat limited. Additionally, there is a distinct need for a deeper exploration of data-driven methodologies in approximating solutions to the SWEs. For instance, questions regarding the comparative efficiency of PINNs versus conventional Artifical Neural Network (ANN) models remain unaddressed. Moreover, the implications of data distribution on the accuracy and precision of PINNs model have yet to be systematically elucidated. This necessitates a comprehensive investigation into the performance and data sensitivity of PINNs in the context of SWE solutions.
As a consequence, the main objective of this paper is to explore the capabilities of PINNs for solving shallow water equations and to assess their effectiveness in accurately approximating water flow dynamics. We present a comprehensive methodology that encompasses the mathematical formulation of the SWE, the architecture and training strategy employed in PINNs, and the data generation techniques used for modeling training and validation. Our study endeavors to underscore the competence and efficacy of PINNs in accurately capturing and simulating fluid flow behavior. This investigation considers scenarios involving both steady flow conditions and instances characterized by highly pronounced fluctuations in flow. Initially, we analyze PINNs' capabilities concerning nonbreaking wave propagation experiments. Subsequently, we extend this assessment to a more intricate scenario involving the utilization of PINNs for simulating dam failure. Moreover, our study rigorously evaluates PINNs' ability to approximate solutions, employing comparisons with ANNs and examining the influence of data point distribution on the precision and reliability of the PINNs model outputs. Ultimately, this exploration accentuates the advantages and potentials inherent in the application of PINNs within fluid dynamics simulations.
The rest of the paper is formulated into the following sections: Section 2 presents briefly SWE and the structure of PINNs, Section 3 presents experiments in the current study, and Section 4 presents results and discussions. The main finding of the study will be concluded in Section 5.
2. Methodology
2.1 Shallow Water Equations (SWE)
The governing equations, represented by Eqs. (1) and (2), are derived from the 1D shallow water equations. These equations are a fundamental mathematical model and are generally utilized to describe the behaviors of water in the channels and rivers. The shallow water equations are derived from the principles of mass and momentum conservation, assuming incompressibility and negligible vertical velocities.
In the given equations, represents the water depth (m), denotes the water velocity (m/s), corresponds to the acceleration due to gravity (m2/s), So represents the bed slope.
2.2 Physics-informed Neural Networks (PINNs)
In this study, the solutions of 1D-SWE are approximated by PINNs, instead of by numerical methods. Fig. 1 illustrates an artificial neural network (ANN) that takes spatiotemporal coordinates as input data and approximates the corresponding variables of interest in SWE.
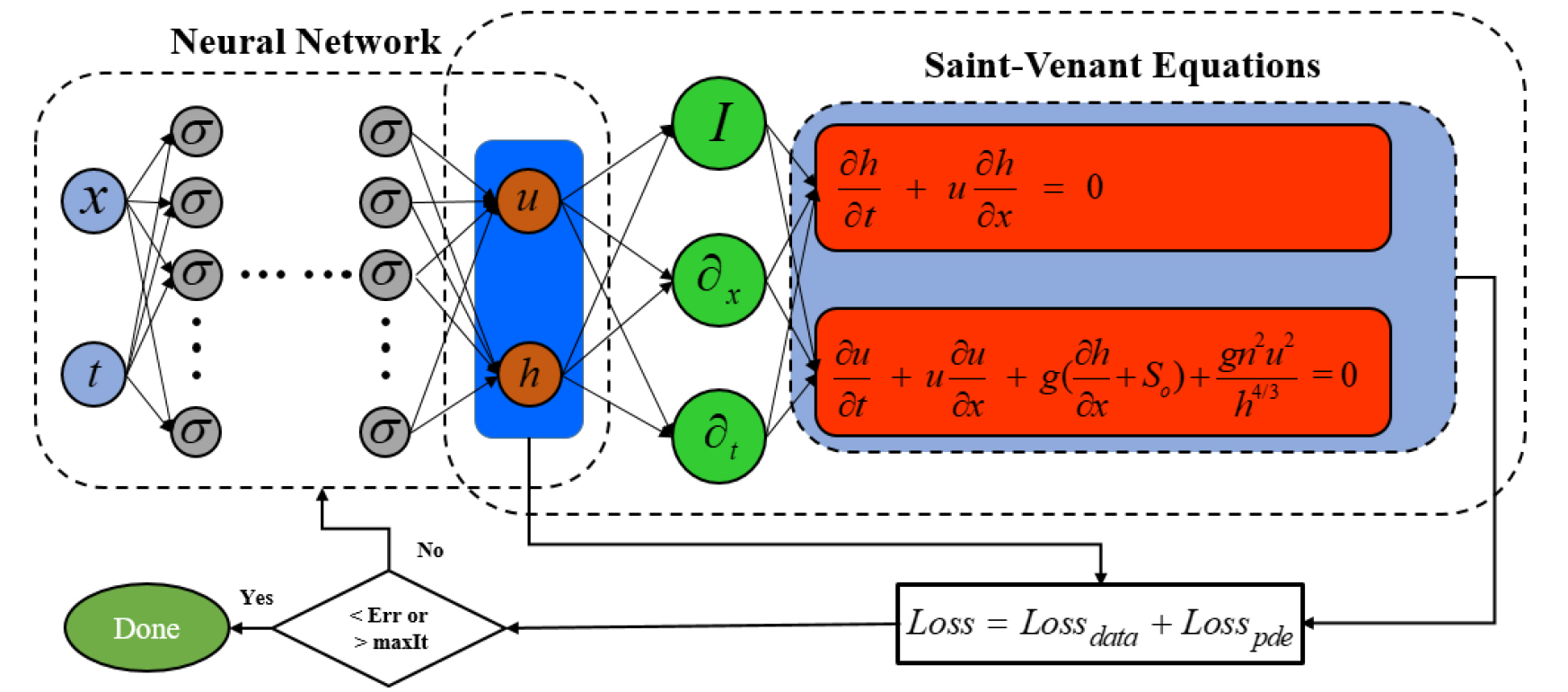
Fig. 1.
The diagram illustrates the configuration of PINNs for solving the SWE. On the left side, an uninformed neural network (NN), while on the right side, an informed NN is depicted, incorporating the conservation law. Both neural networks share the same set of hyperparameters and contribute to the overall loss function during training
Eq. (3) describes the fully connected nature of the neural network architecture employed in this study. The network consists of l hidden layers, with N neurons in each hidden layer. The inputs of the ith layer () are obtained by connecting the results of the previous layer (). This interconnected structure enables the flow of information throughout the network, facilitating the transformation and computation required to generate the desired outputs.
The weight matrix () and bias vector () at the lth layer are parameters that are determined through the training process. These parameters play a crucial role in the neural network's ability to capture the desired behavior. The activation function (𝜎) introduces nonlinearity to each output component, aiding in the network's ability to model complex relationships. In the current work, the tanh () is selected as an activation function. The and are initialized using the Xavier scheme. The loss function presented in Eq. (4) includes two components. The first component involves the MSE between the ANN approximation and the boundary condition (BC) and initial condition (IC) data. The second component is the residuals of the PDEs, which are the summed residual errors of Eqs. (1) and (2) when using and as inputs. By incorporating both the PDE residuals and the data errors, this comprehensive loss function ensures that the network captures the governing physics and effectively approximates the solution to the problem, optimizing the network's performance.
While , and present with weight loss of BC, IC, and PDE, respectively. The loss of each component in Eq. (4) is presented below:
The importance of weighting coefficients () in the loss function (Eq. (4)) for training PINNs has been highlighted in previous studies (Feng et al., 2023; Wang et al., 2021). These coefficients play a crucial role in balancing the contributions of different loss terms, as an imbalance can hinder the convergence of the PINNs solution. Selecting appropriate weights is problem-dependent, as the optimal combination varies based on system properties and conditions. Typically, weights are tuned through trial-and-error procedures or empirically selected methods (Lee et al., 2022; Raissi et al., 2019; Zhang, 2022) because this method is relatively easy to implement. However, this method has been demonstrated to be time-consuming in looking for optimal parameters (Feng et al., 2023; Jin et al., 2021). Recently, McClenny and Braga-Neto (2020) have proposed a self-adaptive weight approach for automatically tuning the weights in the training process. Although, this method could provide acceptable accuracy, however, it also substantially increases the computational demand. To get out of the above situation, in this study, an effective method has been demonstrated in previous study (Chen et al., 2023; Feng et al., 2023; Wang et al., 2021) was adopted. This method employs dynamic weighting coefficients to scale various loss terms, ensuring balanced gradients during the back-propagation process of ANN training. The weighting coefficients are updated at each iteration of the training based on the previous iteration's loss (Loss). The formulation of the ANN parameters is defined by Eq. (9).
The at the th iteration is calculated using the learning rate (𝜂) and the current iteration step () according to the equation:
The updated weighting coefficients are calculated using a moving average approach.
The hyperparameter , with a value of 0.9 as suggested by Feng et al. (2023) and Wang et al. (2021), controls the decay rate of the previous weight to maintain stability during training. The optimization of the DNN in PINNs is employed with the Adam optimizer. To facilitate convergence toward the correct solution, it is crucial to normalize the input data. Consequently, both spatial and temporal variables are mapped to the interval [-1, 1], where the input vector X corresponds to the concatenated value of and . This normalization step is essential to enhance the efficiency and accuracy of the PINNs model (Raissi et al., 2019).
3. Experiments
As stated above, the main aim of this study is to explore the ability of PINNs to solve SWE. For that reason, the PINNs framework formulated in Section 2 will be applied to experiments. Specifically, a nonbreaking wave propagation problem (Bates et al., 2010; Feng et al., 2023; Hunter et al., 2005), which exists analytical solution under certain assumptions will be selected. After that, a comprehensive evaluation was carried out to compare the solution obtained from PINNs with the analytical solution.
3.1 Nonbreaking wave propagation
By considering flow over a planar surface, the continuity and momentum equations of the shallow water can be expressed in a simplified 1D form. Consequently, Eqs. (13) and (14) can be reformulated as follows:
Assuming a constant flow velocity over space and time, we can introduce a moving boundary condition where = 0 at Given that, = 0, the analytical solution for can be obtained by integrating the equation directly and incorporating the moving boundary condition.
This yields the following expression:
The boundary condition at = 0 is obtained from the analytical solutions:
For the simulation duration of 7200s, the reference solution in Eq. (15) is computed with the values u = 1 (m/s) and n = 0.01 (m-1/3s).
3.2 Dam breaking
Dam-breaking involves the phenomena of the sudden release of stored water due to the failure or breach of a dam structure. In the event of a dam failure, the flow characteristics frequently manifest through phenomena such as discontinuities and shockwaves. For the 1D dam break simulation, the governing equations were described by Eq. (17).
Where h is present for water depth (m), u is water velocity (m/s) and g is gravity acceleration. This study evaluates the ability of PINNs to simulate the behavior of the dam break problem. Specifically, how PINNs could be handled with the existence of discontinuities and shockwaves.
Fig. 2 depicts the schematic representation of a 1D dam structure employed for simulating dam failure. The simulation domain is confined within the x range of (-5, 5), and the temporal scope spans from t = 0 to t = 1. Initial conditions were prescribed as follows: h (x, 0) = 3 (m) for x less than or equal to zero, and h = 1 (m) for x greater than 0, with an initial velocity of 0(m/s). To assess the accuracy of PINNs in this scenario, we initially utilized a numerical method (Finite Volume Method) to approximate the solution in Eq. (17). Subsequently, PINNs were employed to track the flow dynamics associated with dam failure.

3.3 Setting-up experiment
In our study, we investigated the performance of the PINNs model in approximating the 1D shallow water wave equation through a series of experiments. In Experiment 1, we constructed a PINNs framework with 6 hidden layers, each containing 64 neurons, to approximate the solution of the nonbreaking wave problem. This experiment provided valuable insights into the PINNs model's efficacy in this context. By using the identical manner as in Experiment 1, the accuracy of PINNs was investigated in situations existing shocking and discontinuous in Experiment 2. Furthermore, to understand the benefits of utilizing the PINNs model in comparison to the ANN model, we conducted Experiment 3. Notably, the structural configuration of the ANN model remained identical to that of the PINNs, with the sole exception being the inclusion of the governing equation. This comparative analysis shed light on the advantages of choosing the PINNs model over the conventional ANN approach. Additionally, the distribution of residual point collection within the domain of interest played a significant role in the performance of the PINNs model, as has been highlighted in prior research. In Experiment 4, we examined how the accuracy of the SWEs solution was influenced by the choice of collection point distribution. Two distinct collection point schemes, namely random sampling and selective sampling, were employed in this experiment to comprehensively understand the impact of data distribution on the accuracy of the PINNs model in approximating the SWEs.
The performance of the PINNs framework was assessed by calculating relative L2 error and root mean squared error (RMSE) using the following equations:
where and are the water level (m) estimated from PINNs (or ANN in Experiment 2) and analytical method, respectively.
4. Results and Discussion
In this section, the results of three experiments are presented and discussed, following the configurations described in Section 3.
4.1 Dose the PINN method effectively approximate the outcomes of the conventional method?
This first experiment serves to demonstrate the effectiveness of PINNs in solving simplified SWE with moving boundaries. The focus is on comparing the spatial-temporal evolution of water depth obtained from the analytical solution with PINNs.
By incorporating a limited set of IC and BC, along with the information from collection points within the calculation of the domain, PINN showcases its ability to accurately approximate the dynamic behavior of the water level. In addition, the results represented in Fig. 3 also indicate that PINNs can capture the underlying physics of the system and learn to simulate the evolution of water depth over time.

By leveraging the flexibility and adaptability of PINNs, the comparison of water surface elevation presented in Fig. 4 indicates that PINNs are capable of effectively approximating the complex interactions and dynamics involved in the SWE problem with a moving boundary with almost insignificant differences. This allows for a more accurate representation of the real-world scenario compared to the traditional methods. In the field of hydrodynamics and coastal engineering, accurate predictions of water depth evolution are essential for designing and maintaining coastal structures, managing coastal erosion, and assessing flood risk. Furthermore, the relatively low difference which was plotted in Fig. 3(c) offers a new approach for various practical applications, and can potentially complement traditional methods, providing more efficient and accurate solutions for realistic applications.

4.2 How PINNs deal with the existence of discontinuous and shocking?
Experiment 2 aims to assess the efficacy of PINNs in handling a particularly challenging scenario- the simulation of dam failure, known for its complexity and difficulty even for traditional numerical methods.
The disparity between the outcomes derived from the numerical method and the PINNs method appears negligible. Fig. 5 illustrates the spatiotemporal evolution of water depth. A comparative analysis between the PINN-derived outcomes and those from the numerical method reveals that the PINNs approach adeptly captures the overarching trends. Simultaneously, the diagrams displaying the spatial variation of water depth at different time intervals, as depicted in Figs. 5(c) and 5(d), underscore the capacity of PINNs to approximate solutions to the 1D SVEs equation. This is particularly notable in scenarios involving discontinuities and shock-like phenomena. Nonetheless, the visual examination in Fig. 5(b) underscores that the solution derived from the PINNs method does not encompass the entirety of water depth variations as comprehensively as the numerical method's outcomes. This distinction becomes particularly evident towards the conclusion of the simulation period and in the downstream region of the dam. The preceding analysis indicates that PINNs exhibit a commendable capacity in solving the SVE equation system. Nevertheless, in specific scenarios, such as those encountered in Experiment 2 of this study, where abrupt flow fluctuations arise, the accuracy of PINNs has not attained parity with solutions derived from numerical methods.

Fig. 5.
Spatial and temporal distribution of water depth from numerical method (NMM) (a); the water approximated by PINNs (b); The graph of water depth at t = 40 (s) and t = 100 (s) in (c) and (d), respectively. The green points and black points in (a) present for initial condition and residual points
4.3 What are the comparative advantages of the PINN in contrast to the ANNs?
The primary objective of this experiment is to evaluate and compare the performance of PINNs against ANN in terms of their respective merits. Specifically, the goal is to determine the merits of PINNs over ANN, which are renowned for their high performance and perceived difficulty to surpass in terms of accuracy. Fig. 6 displays the spatial and temporal distribution of input data for two models: ANNs (Fig. 6(a)) and PINNs (Fig. 6(b)). Green dots signify the initial condition, while red dots denote the boundary condition. Notably, the primary distinction between these models resides in their input data. While both models utilize initial and boundary conditions as inputs, the PINNs model integrates additional data from collection points to enhance the optimization of the loss function detailed in Eq. (5). Notably, the inter-model hyperparameters, such as model structure, activation function, and optimization function, are identical, facilitating a more straightforward assessment of their accuracy.

Table 1 presents a comprehensive comparison of the performance between PINNs and ANNs for Experiment 2. The table includes essential details concerning the number of input data points utilized by both models. The results demonstrated in Table 1 clearly indicate that the PINNs model outperforms the ANN model. Notably, the most compelling evidence of superior performance lies in the significantly lower error achieved by the PINNs model, despite it having the same structure as the ANN model, except for constraint of PDE part. Specifically, the L2 error for ANN is 5.360e-2 (m), while the PINNs model achieves a lower L2 error of 3.638e-2(m). Furthermore, the RMSE for ANN is 0.041(m), whereas the PINNs model demonstrates a more favorable RMSE of 0.028(m). Based on the aforementioned analysis, the examination not only confirms the superior performance of the PINNs model over the ANN model but also sheds light on the underlying strengths of the PINNs approach. This prompts the question of the source of these advantages, given that both models share identical hyperparameters. The key lies in the additional information incorporated by the PINNs model, derived from collection points within the computational domain. This enriched dataset allows the PINNs model to optimize the solution of the SWE by effectively minimizing the loss function while considering the physical constraints imposed by the governing equations. By integrating the governing equations or physical principles as additional constraints, PINNs can effectively guide the learning process toward solutions that adhere to underlying physics (Karniadakis et al., 2021; Peng et al., 2021; Raissi et al., 2019). Various studies have consistently highlighted the limitations of ANN models in handling sparse data, leading to non-physical outcomes event when applied (Riley, 2019; Wang et al., 2020; Zobeiry and Humfeld, 2021). Furthermore, the reliance on a significant amount of labeled data during the training process further compounds the challenge, particularly in scientific machine-learning applications where such data ofter scarce (Gao et al., 2021; Sun and Wang, 2020). The finding of this experiment confirms the inherent advantage of PINNs in effectively approximating solutions to PDEs, exemplified by their successful application to SWE where PINNs’ solutions adhere to the laws of physics. Additionally, the results underscore the superiority of PINNs when faced with scenarios involving sparse training data, further highlighting the robustness and capability in handling data limitations.
Table 1.
Comparison between ANN and PINNs in terms of L2-norm and RMSE
| Models | L2-norm (m) | RMSE (m) | |||
| ANN | 5 | 10 | - | 5.360e-2 | 0.041 |
| PINNs | 5 | 10 | 500 | 3.638e-2 | 0.028 |
4.4 How does the spatial distribution of collection points influence the ultimate outcomes?
The final experiment in our study aims to address the question of how the results obtained from the PINNs model are influenced by different sampling methods for collection points within the computational domain. Two sampling methods are investigated in this experiment. The first method involves randomly drawing collection points, similar to Experiment 1, 2 and 3. In contrast, the second sampling method is specifically designed to target areas of high error in the calculation of domain. Based on observation from the results, it is evident that the errors of PINNs predominantly concentrate in the diagonal region of the computation domain. Consequently, collection points are deliberately selected around this high error region instead of employing random sampling. It is important to emphasize that the total number of input data points for the two PINNs in this experiment remains identical. The sole distinction lies in the distribution of the collection points.
Fig. 7(a) displays the spatial and temporal distribution of data points obtained through random sampling, whereas Fig. 7(b) showcases the deliberate selection sampling approach. Both models utilize an equal total number of collection points, with Nc = 720. Furthermore, the boundary condition and initial condition data points are specified as NBC = 10 and NIC = 5, respectively. Upon examining the outcomes of two PINNs models employing different sampling strategies, depicted in Figs. 7(c) and 7(d), the impact of the sampling strategy on the model results appears inconclusive. However, a notable distinction emerges when comparing the results obtained from PINNs with the analytical solution, as illustrated in Figs. 7(e) and 7(f). Evidently, when collection points are intentionally selected from the high-error region as input for PINNs, superior outcomes are achieved compared to randomly selected collection points.

The error indicators presented in Table 2 emphasize a more pronounced distinction between the two sampling strategies. In the case of the random selection strategy, the L2 error is reported as 2.748e-2(m) and the RMSE as 0.021(m). However, with the alternative sample selection strategy, the error indicators exhibit a significant reduction, with an L2 error of 1.645e-2(m) and an RMSE of 0.013(m). Upon comparing the outcomes presented in Experiment 1 and Experiment 4 concurrently, a discernible pattern emerges, underscoring the pivotal role of residual collection methods in augmenting the accuracy of the PINNs model. As shown by Fig. 8 regarding water level elevation at different times, it becomes evident that the utilization of a selective sampling approach yields results nearly indistinguishable from the analytical solution when employed in conjunction with the PINNs model.
Table 2.
Comparison between the random sample and selected sample schemes
| Schemes | L2-norm (m) | RMSE (m) | |||
| Random | 5 | 10 | 720 | 2.748e-2 | 0.021 |
| Selected | 5 | 10 | 720 | 1.645e-2 | 0.013 |

The primary focus of PINNs lies in optimizing the PDE loss, ultimately guaranteeing the coherence between the trained network and the PDE under consideration (Karniadakis et al., 2021; Raissi et al., 2019). The PDE loss is assessed at a diverse array of scattered residual points. Consequently, the precise location and distribution of these residual points assume paramount importance in optimizing the performance of PINNs (Mao et al., 2020; Wu et al., 2023). Previous studies primarily employed a random uniform or nonuniform selection process for collection points, overlooking the importance of deliberate sample selection (Lu et al., 2021; Raissi et al., 2019; Tartakovsky et al., 2020). However, the results obtained in this study clearly indicate that the process of sample selection merits more careful consideration than simply randomly drawing residual points within the computational domain.
4.5 Limitations and Future Work
While the employed method in this study has demonstrated its effectiveness, it is important to acknowledge its limitations. The conducted experiments focused on relatively simple scenarios, calling for future research to expand the methodology to encompass more intricate and realistic situations, including complex topography and multiphase flow problems. Additionally, as the primary objective of this study was to assess the capability of PINNs in obtaining numerical solutions for SWE, the hyperparameters remained constant throughout the study. Thus, there is scope for refining the structure of PINNs, necessitating further investigations into hyperparameter optimization strategies to identify the most optimal configuration.
5. Conclusions
In this research, we have thoroughly investigated the application of Physics-Informed Neural Networks (PINNs) in estimating the solution of the 1D shallow water equations, with a specific focus on modeling the physics phenomena of non-breaking wave propagation over a flatbed. Our proposed approach leverages both measured data and the governing physical laws, creating a powerful synergy between empirical observations and mathematical constraints. Through three meticulously designed experiments, we have assessed the capabilities of PINNs and have drawn several key conclusions, which hold particular significance in the context of non-breaking wave phenomena:
1. PINNs have proven to be highly effective in providing numerical solutions for the 1D shallow water equations, accurately simulating the intricate dynamics of non-breaking wave propagation over a flatbed.
2. Unlike traditional Artificial Neural Networks (ANN), PINNs seamlessly integrate the governing physics knowledge into the training process, employing physics constraints within the loss functions. This unique characteristic allows us to represent the physical processes of wave behavior more faithfully.
3. PINNs have demonstrated clear advantages over traditional deep learning methods, particularly in situations with sparse data. This holds immense promise for applications where data may be limited, such as studying non-breaking wave phenomena in real-world scenarios. Nevertheless, further comprehensive investigation is required to ascertain the applicability of PINNs in scenarios characterized by abrupt and sudden alterations in flow dynamics.
4. Our experiments have unveiled that the distribution of collection points within the computational domain significantly influences the accuracy of the final solution, a critical insight for accurately modeling the non-breaking wave behavior over flatbeds.
Overall, this work represents a significant step toward harnessing the power of PINNs to model and understand complex physical phenomena, particularly in the context of non-breaking wave dynamics, and it sets a potential tool for future applications of the PINNs in real-world scenarios.
