

1. 서 론
2. 연구방법
2.1 강우-유출모형
2.2 강우-유출모형 매개변수 최적화
2.3 강우-유출모형의 적합성 평가 절차
2.4 앙상블(ensemble) 구축
3. 대상 유역 및 자료
4. 결 과
4.1 강우-유출모형 최적화 결과
4.2 강우-유출모형의 유량구간별 재현능력 평가
4.3 앙상블 모형 구축 결과
5. 결 론
1. 서 론
우리나라의 기후 변동성 증가로 인하여 최근 10년간 극치 사상의 빈도가 증가하고 있으며, 이에 대한 대응 및 대비를 위해 장기적인 관점에서 수자원계획을 수립하는 과정에서 물수지 분석을 통해 물부족 및 물가용성 평가 등이 중요한 사안으로 인식되고 있다. 그러나, 안정적인 물수지 분석을 위해서는 장기간의 유출자료가 필수적이나 댐 상류 유역을 제외하고 장기간의 유출자료 취득은 요원한 것이 현실이며, 물수지 분석에 활용되는 자료는 물 사용 및 조절 행위가 없는 자연유출량 자료가 요구된다. 자연유출량 자료를 취득하기 위해 모든 하천에 대하여 직접계측을 통한 방법은 현실적으로 어려우므로 장기간 강우자료를 연속강우-유출모형의 입력자료로 활용하여 일유출자료를 생산하는 과정이 현실적인 방법이다.
강우-유출모형을 통한 일유출자료 생산을 위해서는 모형 검정을 통하여 매개변수를 조정하는 과정을 수행한다. 그러나 제한적인 자료 사용과 수문순환의 복잡한 물리적인 과정을 과도하게 단순화하는 과정에서 불확실성이 발생하게 된다(Lyne and Hollick, 1979). 연속강우-유출모형의 불확실성은 크게 모형 구조, 입력자료 및 매개변수로 인해 발생하며, 이러한 불확실성은 모형 최적화 과정에서 매개변수들의 독립성 가정 및 사용되는 최적화 기법의 제약조건 등 다양한 방식으로 증가할 수 있다. 이러한 불확실성의 원인이 고려되지 않는 경우 불확실성은 과소평가될 수 있다(Tajiki et al., 2020). Montanari and Brath (2004)는 강우-유출모형을 활용하여 산정된 유출량과 관측값의 오차에 대한 확률분포를 추정하기 위하여 Meta-Gaussian 기법을 이용하여 불확실성을 평가하였으며, Duan et al. (2007)은 다수의 모형의 모의결과를 BMA (Bayesian model averaging)기법을 이용하여 모형에 가중치를 부여하여 불확실성을 전반적으로 개선하였다.
강우-유출모형은 관점에 따라 다른 특징을 가지고 있어 각 모형의 특징을 고려한 연구 및 다수의 강우-유출모형을 활용하는 연구가 진행되어왔다. 고유량에 초점을 맞춘 연구로는 실시간 홍수 예측 및 경보, 홍수 빈도 추정, 홍수 추적, 토지이용의 변화에 따른 홍수량 변화 등을 평가하기 위한 연구들이 진행 중이다(Khazaei et al., 2012; Młyński et al., 2018; Moussa and Chahinian, 2009). 동시에, 농업용수 공급, 생공용수 공급, 수력발전 등 수자원 이용 측면과 더불어 수질 관리의 측면에서 유량자료 활용성을 개선하기 위하여 저유량 모의 개선에 초점을 맞춘 연구들이 진행되고 있다(Garcia et al., 2017; Smakhtin et al., 1998). Garcia et al. (2017)는 강우-유출모형의 결과가 모형의 매개변수의 선정과 더불어 목적함수에 따라 모의결과가 변화하는 특징을 고려하여 저유량에 대한 모의결과를 개선하기 위해 다목적함수(multi objective function)를 이용을 제안하였다. Sitterson et al. (2018)가 다수의 강우-유출모형의 장·단점을 비교하는 연구를 진행하여 연구범위 및 목적에 부합하는 모형을 가용할 수 있는 자료, 유역의 형상등을 고려하여 결정할 것을 제안하였다. Daliakopoulos and Tsanis (2016)는 ANN기법 중 하나인 IDNN을 활용하여 유출량을 모의하여 기존의 SAC-SMA 모형을 비교하는 연구를 통해 SAC-SMA 모형이 저유량에 대한 재현성이 IDNN을 활용한 유출량 모의보다 적합하며 극히 일부 지역에 대해 고유량에 대한 재현성이 IDNN을 활용한 모의가 적합하다는 것을 확인하였다. 따라서, 앙상블 모형을 활용하여 유출량을 예측하는 방안이 더 적합하다는 결론을 도출하였다.
국내에서는 Bae and Lee (2011)는 대유역의 홍수모의가 가능한 강우-유출모형을 개발하였으며 Kwon et al. (2008)은 소양댐 유역의 일강수량 및 일유입량을 자료를 통해 Sacramento 강우-유출모형과 Bayesian MCMC 기법과 결합하여 일유입량을 모의하였다. Kim et al. (2016)은 매개변수의 불확실성을 고려함과 동시에 강우모의기법과 연계하여 입력 강우자료의 불확실성을 고려한 유출모의기법을 제시하였다. 또한, Lee et al. (2018)은 홍수량 산정을 위해 여러 예측모형에 가중치를 부여하여 결합하는 Blending 기법을 제시하고 유출해석 결과에 불확실성을 제시하였다.
본 연구에서는 연속강우-유출모형을 대상으로 매개변수를 추정함에 있어 고유량과 저유량으로 분리하여 매개변수를 추정하고 이에 따른 유출 재현특성을 평가하고자 한다. 국내외에서 활용되고 있는 다수 강우-유출모형을 대상으로 고유량과 저유량 측면에서 재현특성을 우선적으로 평가하고 최종적으로 2가지 목적에 부합할 수 있는 앙상블 유출 시나리오를 생산하는 일련의 해석과정을 제시하는데 목적이 있다.
2. 연구방법
2.1 강우-유출모형
개념적 강우-유출모형은 다양한 수문학적 이론을 개념적 모형으로 접근하여 해당 집수구역에 대하여 다양한 방법을 통하여 강우-유출 분석을 실시하는 과정이다. 이러한 개념적 강우-유출모형은 매개변수의 개수 및 홍수추적 구조 등 수문학적 특성을 현실적으로 반영하여 해석방식에 따라 SACRAMENTO, TOPMODEL, SYMHYD, TANK, GR4J 모형 등으로 다양하다. 개념적 강우-유출모형은 계산이 비교적 간단하며 비교적 적은 입력자료를 통해 모의가 가능하여 활용성이 높은 장점이 있다. 그러나 모형의 해석과정은 모형에 따라 다소 차이가 존재하여 해석특성이 다양하고 목적함수에 따라 모형을 선정하는 방법이 명확히 제시되지 않아 객관적인 평가가 어렵다.
본 연구에서는 46개의 연속강우-유출모형을 검토대상으로 하였으며, 이에 대한 참고논문을 Table 1에 정리하였다. 또한, 최종적으로 통계적 검토를 통해 선정한 9개의 모형을 기반으로 결론을 도출하였으며, 선정된 9개의 개념적 연속강우-유출모형을 아래에 요약하였다.
Table 1.
A reference thesis of continuous rainfall-runoff models
WETLAND, HILLSLOPE 및 PLATEAU 모형은 지형 및 지질학적 특징, 토양의 특징 등과 관련된 모형이다. 지질학적 특징에 따라 습지에서는 과포화로 인한 표면류(saturation excess overland flow)가 지배적인 유출이며, 경사진 지역은 저류 초과로 인한 중간유출(storage excess Interflow)이 지배적이다. 또한, 고원지역의 경우 초과 증발로 인한 깊은 침루(evaporation excess deep percolation)가 지배적인 흐름이다(Savenije, 2010).
GR4J모형은 Edijatno and Michel (1989)가 처음으로 단일 사상에 대한 유출을 모의하는 GR3 모형을 제안하였으며 Edijatno et al. (1999)가 장기유출 모의가 가능한 연속강우-유출모형으로 확장하였다. 이후, Perrin et al. (2003)이 GR3J 모형에서 저유량 모의를 개선하기 위하여 수학적 모형의 구조를 변형하여 4개의 매개변수를 이용한 일 단위 집중형 연속강우-유출모형인 GR4J를 개발하였다. Santos et al. (2018)은 일 단위의 GR4J 모형을 변형하여 차단(interception), 토양수분저류(production store) 및 홍수추적(routing store)의 3단계 과정을 거쳐 강우-유출과정은 동일하나 홍수추적에 대하여 단위유량도를 사용하지 않고 Nash cascade 방법을 활용한 GR4 모형을 개발하였다. 두개의 단위유량도에서 하나의 단위유량도로 단순화된 결과가 이전의 모의결과와 비교하여 크게 변동되지 않도록 개발하였다.
HYMOD 모형은 2개의 강우초과모형 매개변수와 3개의 홍수추적과 관련된 매개변수로 이루어진 연속강우-유출모형으로, Moore (1985)가 확률분포에 기반하여 개발한 모형이다. 유출이 속도에 따라 속도가 빠른 유출(quick flow)을 추적하는 세개의 탱크와 속도가 느린 유출(slow flow)이 병렬적으로 연결되어 있다.
SACRAMENTO모형은 Burnash et al. (1973)에 의해 제안된 집중형 개념적 강우-유출모형으로, 타 모형들과 매개변수 개수를 비교하면 17개의 매개변수로 다소 복잡한 과정을 통해 모의를 진행한다. 토양을 상부층과 하부층으로 구분하여 각 층에 부착되는 부착수와 자유수로 다시 한번 분리한다. 여기서 부착수는 오직 증발산에 의해서만 소모되며, 자유수는 증발산 및 침루에 의해 소모된다. 강우가 발생하면, 초기에는 상부토양층의 부착수의 형태로 이용되고 이후에는 상부층의 자유수의 형태로 존재한다. 상부층의 자유수는 중력에 의해 하부층에 침루하여 횡방향의 중간유출의 발생에 기여하며, 상층부 부착수를 모두 채우고 남은 물은 하층부 부착수에 저장되고 강우량 및 토양함수량에 따라 자유수가 먼저 채워질 수도 있도록 모형의 구조가 이루어져있다.
MODHYDROLOG 모형은 Porter and McMahon (1976)은 HYDROLOG 모형을 개발하였으며, Chiew and McMahon (1994)이 하천-대수층 상호작용과 지하수침투에 대한 모의를 향상시켜 지하수 알고리즘을 수정한 모형이다. 초기 일 강우량은 차단 저류량을 채우고 증발로 소실된다. 초과 강우량 중 일부는 토양으로 침투하여 토양수분저류량을 채우게 된다. 침투 후에 남은 물은 지면저류가 발생하는 동시에 직접유출을 발생한다.
SMAR (Soil Moisture Accounting and Routing) 모형은 Layer Model (O’connell et al., 1970)에서 발전된 모형으로, 유출을 발생시키는 과정을 관리하는 다양한 물리적 현상을 간단하게 모의 수행하는 물 수지 부분과 물 수지에 의해 발생한 유출의 추적 과정으로 분리되어있다.
NAM 모형은 덴마크 공과대학에서 만들어진 모형으로 집수구역에 대한 강우량과 증발산량이 모델의 입력자료로 활용된다(Nielsen and Hansen, 1973). 또한, NAM 모형은 4개(눈, 지표면, 뿌리층, 토양수분층)의 상호관련된 저수구역으로 나누어 수문학적 순환을 나타내었고 적설로 인한 저류는 눈이 없는 경우 배제하여 진행한다. 표면 저류는 식생에 의한 차단으로 발생하는 분수와 요면(凹面)부의 지면 저류로 인한 흐름을 의미하고 있으며 증발이나 중간유출의 형태의 흐름으로 인해 소실될 수 있다. 이러한 유출을 제외하고 초과하는 양은 표면류로 흐름이 발생하게 되고 침투 또는 뿌리 깊이의 낮은 구역 또는 지하수로 저장된다.
2.2 강우-유출모형 매개변수 최적화
비선형 관계의 강우-유출모형의 최적화를 위하여 MATLAB의 최적화 툴박스인 fmincon을 이용하였다. fmincon 함수는 비교적 대량의 자료를 최적화하는 문제에서 사용되는 알고리즘으로, 비선형 다변수 함수에서 제약조건을 고려하여 최솟값을 계산한다. 계산방법은 순차적 2차 계획법(sequential quadratic programming, SQP)을 이용하였다. 여기서, SQP 알고리즘은 주어진 목적함수와 제약조건을 2차 계획문제로 만들어 연속적으로 풀어 최적해를 구하는 방법이다. SQP알고리즘의 제약조건은 Eq. (1)과 같다.
여기서, A, b는 선형 부등식 제약조건이며, Aeq, beq는 선형 제약조건을 부여하는 등식 제약 조건 행렬이며, c(x), ceq(x)는 각각 비선형 등식, 부등식 제약조건이며, F(x)는 목적함수를 의미한다. 이때, Aeq, beq는 강우-유출모형에서는 선형 부등식 제약조건을 제외한 다른 조건들에 대하여 알 수 없으므로, 모두 값을 정의하지 않는다. 선형 부등식 제약조건은 매개변수 범위로 지정되므로, Eqs. (2) and (3)와 같이 표현되며, Eq. (4)는 매개변수 범위이다.
fmincon함수는 최솟값을 찾아 최적해를 구하므로 NSE를 음수로 변환하여 최솟값을 계산하였다. Eq. (5)는 fmincon을 이용하여 연속강우-유출모형을 계산하기 위한 목적함수이다.
여기서, 은 모의결과 값이며, , 는 각각 관측값과 관측값의 평균이다. 그러나, NSE를 통한 최적화는 고유량의 재현성이 높은 결과를 야기할 수 있어, 유량을 분리하여 상대적으로 저유량에 대한 재현성이 높은 모형을 4.2에서 재확인하는 절차를 수행하였다.
2.3 강우-유출모형의 적합성 평가 절차
본 연구에서는 앞에서 제시한 비선형 최적화 기법과 함께 제시한 목적함수인 NSE를 기준으로 선형제약조건 없이 선형 부등식 제약조건을 이용하여 최적화를 수행하였다. 매개변수가 상대적으로 적고 통계적 적합성이 우수한 강우-유출모형 9개를 선정하였다. 최종적으로 9개 모형 중 적합성을 평가하기 위하여 유황곡선을 작성하였으며, 고유량(Q95), 중간유량(Q185), 저유량(Q275) 및 갈수량(Q355)으로 분리하고 각 유량조건에 따른 모형의 적합성을 Akaike Information Criterion (AIC) (Akaikei, 1973) 및 Bayesian Information Criterion (BIC) (Schwarz, 1978)를 활용하여 평가하였다. 이때, 오차가 정규분포를 이룬다고 가정하여 우도함수(likelihood function)를 계산하여 AIC 및 BIC 산정에 적용하였다.
본 연구에서 AIC와 BIC를 계산하기 위해 오차의 분포가 정규분포를 따른다고 가정하였다. 일반 통계적 모형과는 다르게 강우-유출모형은 우도함수 설정 및 추정이 어려우며 이러한 점에서 오차분포(error distribution)가 평균이 0이며 분산이 를 따르는 정규분포로 가정하였으며, 이는 Eqs. (6) and (7)에 기술한 것과 같다.
여기서 Qobs, Qm는 각각 관측 유량 및 모의된 유량이며, 은 오차이다. 오차는 정규분포를 따르게 되며, 정규분포의 확률밀도함수는 Eq. (8)와 같다.
AIC 및 BIC에 사용된 우도함수는 Eq. (9)를 통해 산정하였다.
AIC는 모형의 적합정도를 나타내는 우도와 매개변수의 개수를 통계적으로 고려하여 정보의 총량을 정량적으로 표현할 수 있으며, AIC 결과가 작을수록 적합한 모형이다. AIC를 산정하는 일반적인 식은 Eq. (10)와 같이 나타낼 수 있다.
여기서, k는 매개변수 개수이며, 은 우도함수 이다.
BIC 또한 모형 선택에 활용되며 BIC 값이 작을수록 적합한 모형으로 선정된다. AIC와는 다르게 자료의 개수 n을 고려하게 되며 BIC를 산정하는 일반적인 식은 Eq. (11)와 같이 나타낼 수 있다.
여기서, k는 매개변수 개수이며, n은 자료의 개수이며, 은 우도함수이다.
2.4 앙상블(ensemble) 구축
선정된 모형을 개별적으로 적용하여 유출을 모의하는 것도 가능하나, 모형의 적합도를 기준으로 가중치를 결정하고 이를 앙상블로 구축할 수 있다. 본 연구에서는 연속강우-유출모형 앙상블로 확장하기 위하여 Bayesian MCMC (Markov Chain Monte Carlo) 기반의 가중치(weighting) 산정 기법을 개발하였다. 본 연구에서는 9개 모형의 가중치를 산정하기 위해 Bayesian 모형을 적용하였으며, 가중치에 대한 불확실성이 반영된 연속강우-유출모형 앙상블로 확장하였다. 모형평가를 위해 AIC 및 BIC 산정을 위해서는 매개변수의 개수와 샘플의 크기가 분명한 경우 적용이 가능하며, 계층적(hierarchical) Bayesian 모형에서는 Deviation Informative Criterion (DIC)을 이용하여 모형의 적합성을 평가할 수 있다. 이는 계층적 Bayesian 모형의 복잡성으로 인해 매개변수에 대한 개수를 명확하게 고려하는 것이 어려우므로 Spiegelhalter et al. (2002)가 Bayesian 모형의 비교 및 평가를 위해서 DIC 이론을 정립하였다. 일반적인 DIC 식은 Eq. (12)와 같다.
여기서 는 편차의 함수에 대한 기댓값이며, pD는 모형의 최적 매개변수 개수이다.
DIC는 계층적 Bayesian MCMC를 통해 매개변수의 사후분포를 추정하는 과정에서 산정이 가능하며 AIC 및 BIC와 동일하게 작은 DIC를 가지는 모형이 최적 모형으로 선정된다. 본 연구에서는 적합도 검정을 통하여 대수정규분포(lognormal distribution)를 관측유량의 확률분포로 채택하였으며, 오차는 평균이 0이고 분산 인 정규분포를 따른다고 가정하였다. 이를 식으로 표현하면 Eqs. (13) ~ (15)로 표현되며, 각 모형에 대한 가중치는 Eq. (16)으로 표현된다.
여기서 Qobs는 관측유량을 나타내며, 와 Wm는 m번째 모형의 모의유량 및 가중치를 의미한다. 또한 nm과 n은 사용된 모형 및 자료의 개수를 의미한다. 가중치의 초기값은 모두 동일하며, 가중치에 대한 사전분포(prior distribution)로 균일분포를 채택하였다. 가중치 및 사전분포에 대한 식은 Eqs. (17) ~ (19)로 표현된다.
3. 대상 유역 및 자료
본 연구의 대상 유역은 춘천시 신북읍과 동면에 위치한 소양강댐으로, 유역면적 2,703 km2, 길이 530 m 및 높이 123 m의 다목적댐이다. 수도권 지역(서울, 인천, 수원 등)에 생활용수, 공업용수 및 관개용수를 공급할 뿐만 아니라, 한강 하류부의 수해방지에 기여하고 있다.
본 연구에서는 선정된 연속강우-유출모형을 적용하기 위해 소양강댐의 유입량자료를 자연유출량으로 활용하였으며, 입력자료는 소양강댐 유역의 강수량, 기온 및 잠재증발산량 자료를 구축하여 모의에 활용하였다. 강우 및 기온자료는 기상청에서 관리하는 종관기상관측소(ASOS)자료 중 소양강댐 유역에 해당하는 자료 보유년수 30년 이상인 5개 지점(춘천, 홍천, 인제, 속초, 대관령)에 일단위 강수 및 온도 자료를 티센(thiessen)방법을 적용하여 유역평균값으로 추정하였다. 잠재증발산량 자료는 세계농업기구(FAO56)에서 사용하는 Penman-Monteith 방법을 활용하여 생산한 유역별 잠재증발산량 자료이다. Fig. 1은 소양강댐 유역에 영향을 주는 5개의 종관기상관측소이며, 소양강댐 및 기상 관측소의 제원과 자료기간을 Table 2에 기술하였다.
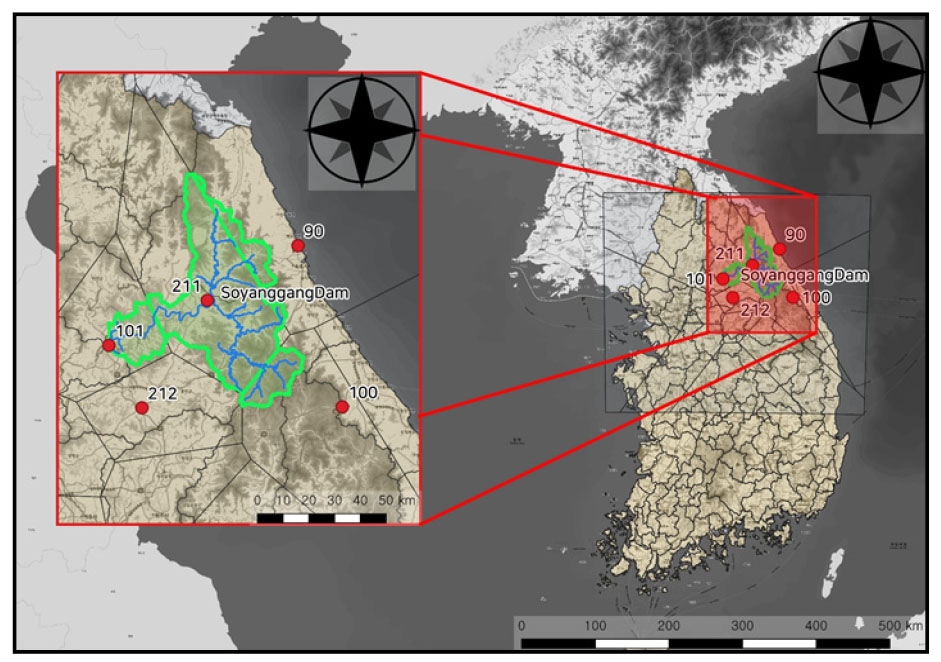
Table 2.
Specification of Soyanggang dam station and ASOS stations
4. 결 과
4.1 강우-유출모형 최적화 결과
본 연구에서는 국내외에서 개발되어 적용되고 있는 강우-유출모형으로부터 적합모형을 1차적으로 선정하기 위해 46개의 연속강우-유출모형을 검정기간(2016년 ~ 2017년) 및 검증기간(2018년)으로 분리하여 모형을 평가하였다. 3년이라는 상대적으로 짧은 기간을 대상으로 모형의 적합성을 검토한 것은 다수의 모형을 전기간에 걸쳐 최적화하는데 연산시간이 오래 소요되기 때문이며, 실제 최적모형을 선정하기에 앞서 1차적으로 모형의 적절성만을 검토하는데 목적이 있다. 검증기간에 해당하는 NSE 및 매개변수 개수를 비교하여 관측유량 재현성이 우수한 모형을 선정하였다. Table 3는 46개 모형에 대한 매개변수 개수 및 NSE 결과이다.
Kalin et al. (2010)은 예측모형의 정확도를 NSE를 기반으로 모형의 수행능력을 정량적으로 평가하였다(Very good: NSE ≥ 0.7, Good: 0.5 ≤ NSE < 0.7, Satisfactory: 0.3 ≤ NSE < 0.5, and Unsatisfactory: NSE < 0.3). NSE의 기준 0.3 이상이면 대체적으로 모형은 적합성을 갖는 것으로 알려지고 있다. 일반적으로 매개변수의 개수가 많을수록 NSE가 개선된 결과를 보여주고 있다. GR4J가 관측유량의 특성을 가장 효과적으로 재현하는 것으로 평가되었으며 주요 유량 크기별로 비교 검토하여 46개 모형 중 대표 모형을 선정하고자 한다.
Table 3.
Continuous rainfall-runoff models, their number of parameters and Nash-Sutcliffe efficiency
46개 연속강우-유출모형 중 국내외 적용사례, 매개변수 개수 및 NSE를 동시에 고려하여 상위 9개의 모형을 선정하였다. NSE가 높은 상위 9개의 모형을 선정 후, 9개의 모형을 재차 전체기간 중 70%에 해당하는 검정기간(1996년 ~ 2016년)과 전체기간 중 30%에 해당하는 검증기간(2017년 ~ 2018년)으로 적용하여 결과를 도출하였다. Table 4은 검증기간(2017년 ~ 2018년)에 대해 NSE를 비교한 결과이며, 검정 및 검증기간동안 개별 모형별 모의유량과 관측유량을 비교하여 Fig. 2에 나타내었다. Table 4에서 나타나듯이 대부분의 모형이 NSE 기준 0.7을 상회하는 값을 나타내고 있으며 우수한 예측능력을 확인할 수 있다.
Table 4.
Comparisons of Nash-Sutcliffe efficiency over the selected rainfall-runoff models during calibration and verification Phases
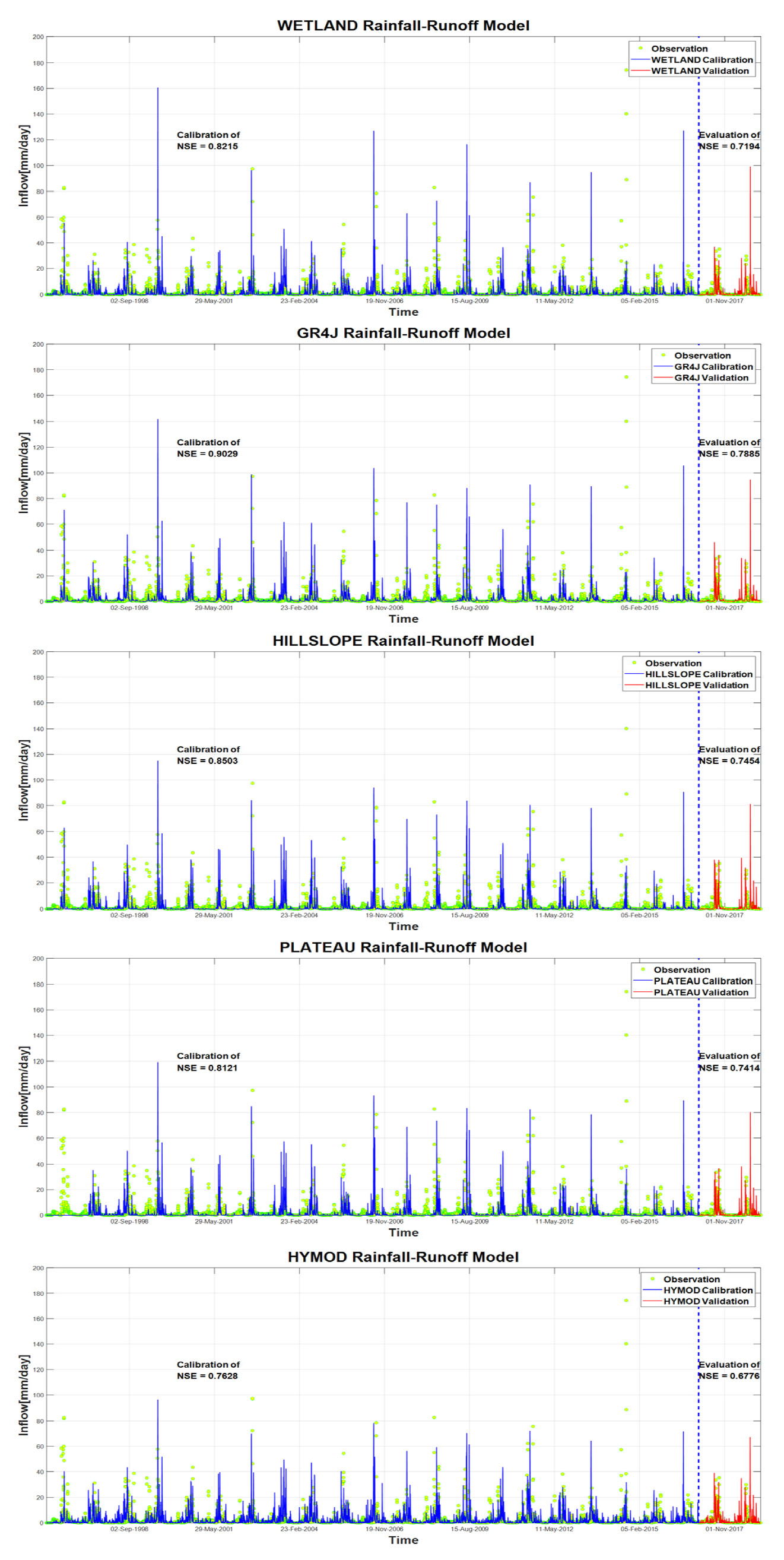
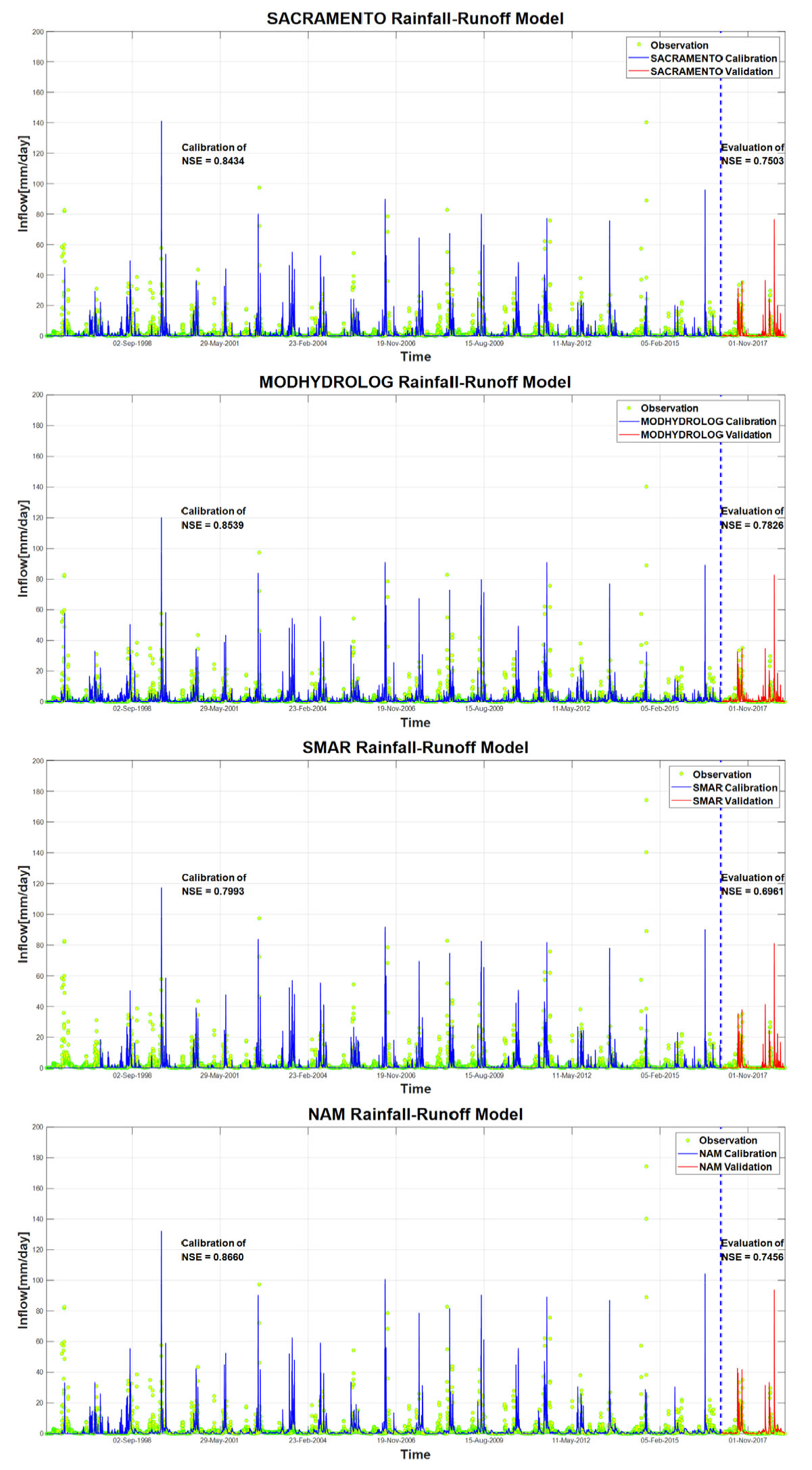
4.2 강우-유출모형의 유량구간별 재현능력 평가
선정된 9개의 연속강우-유출모형을 비교한 결과, Fig. 2에 도시한 것과 같이 비교적 고유량에 대한 재현성이 높은 모형들이 NSE가 높다는 것을 확인할 수 있다. 따라서, 모형의 재현능력을 유량의 크기별로 검토하여 모형특성을 좀 더 상세하게 판단하였다. 이를 위해 본 연구에서는 앞서 방법론에서 제시된 우도함수와 매개변수를 동시에 고려할 수 있는 AIC 및 BIC를 기준으로 유황곡선(flow duration curve, FDC)구간별로 적합성을 평가하였다. Fig. 3은 관측유량 및 개별 모형의 모의 유량을 유황곡선으로 비교하였으며, Table 5에서는 4개에 유량구간에 대해서 AIC, BIC 및 RMSE를 비교하였다.
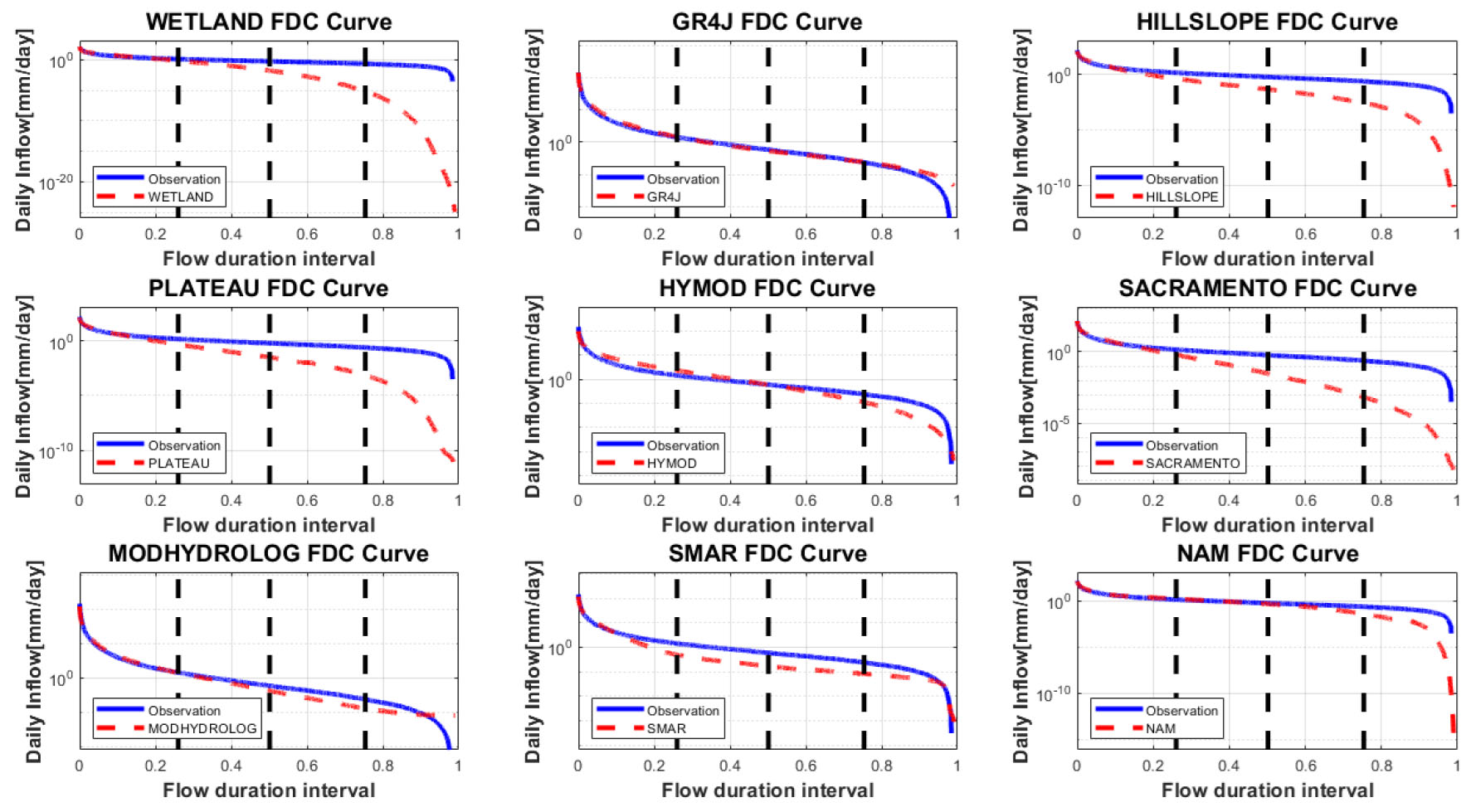
Table 5.
Comparisons of AIC, BIC and RMSE across the selected 9 rainfall-runoff models
유량별로 구분하여 모형을 비교한 결과, 고유량에서는 AIC, BIC 및 RMSE 모두 NAM 모형이 가장 유리하며, 중간유량, 저유량, 갈수량에 해당하는 영역에서는 GR4J가 가장 재현성이 높은 것을 확인할 수 있다. 일반적으로 유량의 크기 측면에서 전체영역을 대상으로 모형의 적합성을 평가하는 연구들이 주로 진행되었다. 그러나 본 연구에서 제시된 바와 같이, 각 유량구간별로 모형이 가지는 재현능력이 확연하게 다르다는 점을 확인할 수 있으며, 강우-유출 모형의 재현능력 평가 시 이에 대한 고려가 충분히 필요할 것으로 판단된다. 본 연구에서 개별 모형별 특징과 유량구간별 재현능력에 대한 관계를 구분하여 설명하는 것도 필요할 것으로 판단되나 본 연구의 범위를 벗어나는 부분으로서 향후 연구에서 다루고자 한다. 유량 구간별로 각 모형이 가지는 재현능력이 다른 점을 고려한다면 개별 강우-유출 모형을 통한 유량 산정보다는 각 모형의 장점을 최대한 활용할 수 있는 방안의 도입이 필요하다. 이러한 점에서 본 연구에서는 각 모형별 우수한 특징을 최대한 활용하기 위한 목적으로 Bayesian MCMC 기반의 강우-유출 모형 앙상블 구축방안을 제시하였으며 관련 결과는 다음 절에 제시하였다.
4.3 앙상블 모형 구축 결과
본 연구에서는 앞서 언급한 바와 같이 Bayesian MCMC 기법을 이용하여 연속강우-유출모형 앙상블을 구축하였으며, 매개변수의 수렴을 위하여 3개의 Chain을 독립적으로 시행하여, 3000번의 모의 발생을 하였으며, 1,000번의 시행을 제거(burn-in)하여 남은 2,000번의 결과의 표본을 이용하여 앙상블 구축에 이용하였다. 이때, 구성된 모형의 적합성 및 상대적인 우수성을 비교하기 위해서 DIC 값을 비교하였다. 즉, DIC가 최소인 모형을 최적의 강우-유출모형 앙상블로 선정하였다. Table 6는 모형의 개수에 따른 DIC 및 NSE 결과를 나타내며, DIC가 낮을수록 NSE는 높은 경우가 가장 적합모형의 조합이라 할 수 있다.
Table 6.
Comparisons of model performance with DIC and Nash-Sutcliffe efficiency with different combinations of models
결과적으로, RMSE 및 AIC, BIC를 비교한 결과 GR4J, MODHYDROLOG 및 NAM 모형이 상위 9개의 연속강우-유출모형을 모두 이용하는 것보다 통계적으로 가장 우수한 모형으로 분류될 수 있다. 최적 조합인 3개의 모형을 이용하였을 때 NSE는 개별 모형기준 GR4J에서 가장 높은 결과를 보였던 0.79보다 상대적으로 우수한 0.90을 나타내고 있다. 최적 앙상블모형을 구축을 위해 각 모형별 가중치를 산정해 보면 GR4J 모형은 0.49, MODHYDROLOG 모형은 0.23, NAM 모형은 0.28로 산정되었다. GR4J 모형이 타 모형에 비해 큰 가중치를 갖는 것은 앞서 검증과정에 제시되었듯이 고유량을 제외한 중간유량, 저유량, 갈수량에 대한 관측유량 재현성이 우수한 점에 기인한 것으로 판단된다. Fig. 4는 모형의 앙상블 결과를 도시한 것이다. Bayesian MCMC 모형을 통해 산정된 가중치는 불확실성을 정량적으로 제시하게 되며, 결과적으로 유량 앙상블도 확률분포형태로 제시되게 된다. 즉, 유량의 확률예보 및 불확실성 평가 측면에서 다양한 장점을 제공한다 하겠다.
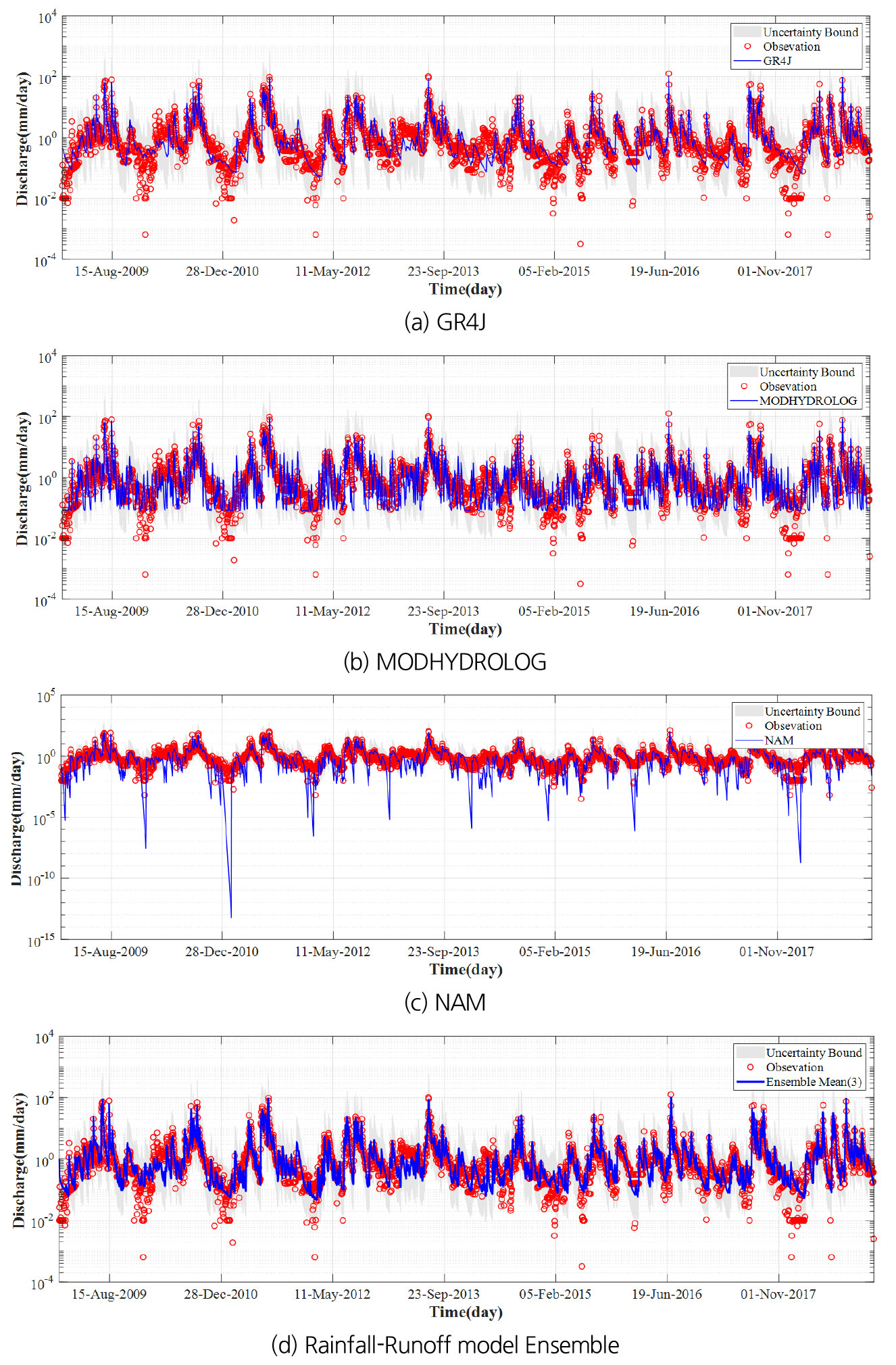
Fig. 4에서 나타난 것과 같이 저유량에 대한 모의가 향상됨을 확인할 수 있으며, 앙상블 결과를 보다 다양한 통계지표를 통해 평가하기 위해서 상관계수(correlation coefficient, CC), 편의(bias), 일치계수(index of agreement, IoA) 및 평균제곱근오차(root mean square error, RMSE)를 활용하였다. 여기서 IoA, CC 검증은 1에 가까울수록 적합성이 높다. Table 7은 평균제곱오차, 일치계수, 상관계수 등을 비교한 것이다. 본 연구를 통해 제시된 앙상블 모형은 개별 모형에 비해 모든 지표에서 개선된 결과를 확인할 수 있다. 앙상블 결과 비교에 사용된 통계지표의 산정식은 Eqs. (20) ~ (22)와 같다.
Table 7.
Comparison of statistical measures over different 9 models and rainfall-runoff model ensemble
5. 결 론
본 연구에서는 소양강댐 유역에 해당하는 종관기상관측소 기온자료, 강수량 및 잠재증발산량 자료를 기반으로 국내외 주요 강우-유출모형을 대상으로 관측유량 재현특성을 평가하였다. 모형별 장점을 고려할 수 있도록 강우-유출모형 앙상블 기법을 개발하였다. Bayesian MCMC을 이용하여 개별 강우-유출 모형에 가중치에 대한 사후분포를 효과적으로 유도할 수 있었으며, 이들 매개변수(가중치)를 활용하여 강우-유출모형 앙상블 모형으로 확장될 수 있도록 하였다. 해석결과에 대한 불확실성 구간도 동시에 제공할 수 있었으며 다양한 통계지표를 통하여 앙상블 모형의 적합성을 검토하였다. 본 연구의 결론을 요약하면 아래와 같다.
1) 소양강댐 유역을 대상으로 국내외 다수의 연속강우-유출모형을 통해 유량모의를 진행하였다. 모의 결과를 관측값과 비교하기 위하여 NSE를 활용하였으며, NSE가 높은 모형 중 비교적 다수의 연구사례가 존재하며 매개변수의 수가 적은 모형을 선정하였다. 이러한 기본적인 기준을 통해 선정된 모형은 모두 9개로서 WETLAND, GR4J, HILLSLOPE, PLATEAU, HYMOD, SACRAMENTO, MODHYDROLOG, SMAR, NAM 모형이 선정되었다.
2) 본 연구에서는 최적화 시 목적함수를 NSE를 활용하여 진행하였으나, NSE는 고유량에 대한 재현성을 평가하는데 유리한 특징이 있으며, 이러한 점을 고려하여 고유량, 중간유량, 저유량 및 갈수량에 대한 재현성을 추가적으로 평가하였다. 유량 구간별 모형의 재현 능력을 비교하기 위하여 유황곡선을 기준으로 통계지표인 AIC, BIC 및 RMSE를 재산정하여 모형별 특징을 검토하였다. 고유량에서는 NAM모형이 가장 적합하며 중간유량, 저유량 및 갈수량은 GR4J 모형이 적합함을 확인할 수 있었다. 강우-유출 모형에 대한 검증 시 유량의 전체분포를 대상으로 모형의 적합성을 평가하는게 일반적이다. 그러나 본 연구에서 제시된 바와 같이, 각 유량구간별로 모형이 가지는 재현능력이 확연하게 다르다는 점을 고려할 때 모형에 대한 검증 방법에 대한 개선도 필요할 것으로 판단되며, 이들 모형들의 조합을 통한 강우-유출 모형의 개선 측면도 타당성을 가진다 하겠다.
3) 모형특성을 반영한 연속강우-유출모형 앙상블을 구축하기 위해 Bayesian MCMC 기법을 이용하여 모형에 가중치를 부여하였다. 최종적으로 DIC를 이용하여 최적의 모형 조합이 가능하였다. 즉, DIC를 기반으로 최적의 모형 조합은 GR4J, MODHYDROLOG 및 NAM모형으로 구성되며 모형별 가중치 추정 및 적용 통해 효율성 있는 앙상블 모형 구축이 가능하였다. 강우-유출 모형 평가에 주로 활용되는 통계지표인 상관계수, 편의, 일치계수, 평균제곱근오차를 활용하여 앙상블 모형 결과에 대한 우수성을 평가하였으며 개별 모형 적용 결과보다 대부분의 통계지표에서 우수함을 확인할 수 있었다.
