

1. 서 론
2. 연구 방법
2.1 LSTM-s2s
2.2 Attention Mechanism
2.3 대상유역 및 입력자료
2.4 평가지표
3. 모형 구축 및 분석
3.1 모형 구축
3.2 LSTM-s2s와 Attention을 첨가한 모형 간 최적화 및 비교 분석
3.3 유입량 예측 평가
4. 요약 및 결론
1. 서 론
댐의 유입량을 정확하게 예측하는 것은 효율적인 수자원 이수와 치수에 필수적이다(Kwon and Shim, 1997). 현재 우리나라에서는 수자원 관리 및 물 관련 재해 대응을 위한 21개의 다목적댐과 14개의 용수댐을 포함해 약 18,000여 개의 댐이 운영되고 있고(Choi et al.,2016), 댐 운영에서 매시간 유입량을 고려해 적절하게 방류하는 것이 중요한 과제이다(Kwon and Shim, 1997). 이를 위해 시간 단위 유입량을 높은 정확도로 예측할 필요가 있다.
과거에 유입량 예측 시 주로 사용된 모델로는 수문학적 현상들을 물리법칙으로 설명하는 물리적 모델(Physically based model)과 물리적 모델을 바탕으로 수학적 계산을 하는 개념적 모델(Conceptual model)이 있다(Devia et al., 2015; Bicknell et al., 1996; Kim et al., 2007; Noh and Lee, 2011; Kwak et al., 2009). 하지만 정교한 물리적 모델일지라도 기상, 지형 등의 특성을 전부 반영하기 힘들며, 이를 반영하려 해도 매개변수의 증가로 인한 오차 누적으로 불확실성이 증가하게 된다(Jung et al., 2017).
최근에는 인공신경망(Artificial Neural Network, ANN)과 같이 복잡한 비선형 구조를 잘 표현하는 경험적 모델(Empirical model)이 활발하게 활용되고 있다(Nourani, 2017; Dawson and Wilby, 2001; Tiwari and Chatterjee, 2010; Nourani et al., 2009). 인공신경망은 종류가 다양한 만큼 복잡한 모델링 시스템에서 각각의 장단점이 명확하다(Kao et al., 2020). 특히 그중에서 순환신경망(Recurrent Neural Network, RNN)은 시계열 데이터를 효과적으로 처리하기 위한 알고리즘이지만, 긴 데이터에서는 기울기가 소실되거나 폭발하는 단점이 있다.
이 문제를 극복하기 위해 Hochreiter and Schmidhuber (1997)이 Long Short-Term Memory (LSTM)을 대안으로 제안하였고, 최근 LSTM은 시계열 자료를 통해 강의 홍수를 예측(Le et al., 2019)하고 저수지의 유입량을 예측(Qi et al., 2019)하는 등 긴 기간의 입력자료를 이용한 예측에 많이 쓰이고 있다. LSTM을 활용해 댐의 유입량을 예측하면 더 효과적이라고 알려져 있다(Fu et al., 2020; Cho and Kim, 2022).
LSTM은 입출력 데이터 길이를 변경함과 동시에 다른 도메인으로 전환할 수 있는 s2s (sequence-to-sequence)를 모델에 적용해 효과적으로 훈련시킬 수 있다(Sutskever et al., 2014). 강우-유출 과정은 강우 시퀀스에서 유출 시퀀스로 구현되어 강우를 통해 한발 앞서 댐의 유입량을 예측할 수 있다(Kao et al., 2020). LSTM에 s2s를 적용한 LSTM-s2s 모델은 입력과 출력에 다른 길이의 고정된 벡터를 사용하게 됨으로써, 두 개의 LSTM이 각각 인코더(Encoder)와 디코더(Decoder)로 작동하게 된다. 그러나 LSTM-s2s도 입력데이터가 너무 길어지게 되면 여전히 입력정보들이 제대로 전달되지 않는다는 단점이 존재한다. 이를 해결하기 위한 Attention 기법은 인코더 입력에 다시 한번 주목함으로써 성능을 개선하는 방법이다. 최근에 태양광 전력 예측(Zhou et al., 2019), 기계번역(Choi et al., 2018), 이미지 분석(Song et al., 2018), 영상 분석(Li et al., 2018) 등 여러 분야에 적용되고 있지만, 아직 수문 분야에는 적용 사례가 적다.
Kao et al. (2020)은 LSTM과 LSTM-s2s의 비교를 통해 시간 유입량 예측분석을 진행하였고, Yan et al. (2021)은 LSTM과 LSTM에 attention을 첨가한 모델의 비교를 통해 시간 유입량 예측분석을 진행하였다. 국내에서는 Han et al. (2021)이 LSTM-s2s를 통한 일 유입량 예측을 연구하였으며, 관련 연구는 매우 부족한 실정이다. 주로 이전 연구들에서는 LSTM-s2s 혹은 attention만을 첨가한 모델, 둘 중 하나를 택하여 연구를 진행하였다.
본 연구에서는 상류의 소양강댐 유역을 대상으로 LSTM-s2s와 LSTM-s2s에 attention까지 첨가한 모델을 구축하고 평가하였다. 특히, 시간 단위 자료를 사용하고 유입량을 예측하는 연구를 통해 실제 댐 운영에 모델들의 활용 가능성을 확인하고자 하였다.
2. 연구 방법
2.1 LSTM-s2s
LSTM은 기존 순환신경망(RNN)이 가지고 있던 장기간 데이터 분석 시 발생하는 기울기가 소실되고 폭주하는(exploding and vanishing gradient) 문제를 해결하기 위해 Hochreiter and Schmidhuber (1997)이 제안한 알고리즘이다. LSTM-s2s 모델(Sutskever et al., 2014)은 인코더-디코더 모델로도 알려져 있으며, 기계번역, 영상 분할과 같은 분야에서 주로 사용된다(Costa-jussà, 2018; Marmanis et al., 2018). LSTM의 구성요소인 셀(Cell)에는 세 개의 게이트(gate), 망각게이트(Forget gate, ft), 입력게이트(Input gate, it), 그리고 출력게이트(Output gate, ot)가 존재한다(Fig. 1). 망각게이트(ft)에서는 정보를 어느 정도 제거할지를 결정하고, 입력게이트(it)에서는 새로운 입력데이터 중 업데이트할 데이터를 결정하고, 출력게이트(ot)에서는 셀에 저장된 정보 중 다음으로 전파할 정보를 결정한다. 이런 과정은 다음 Eqs. (1)~(6)를 통해 이루어진다.
여기서, 는 시그모이드(sigmoid) 활성화함수, tanh는 하이퍼볼릭 탄젠트(hyperbolic tangent) 활성화함수이다. Wf, Wi, Wo, Wc는 각 단계의 가중치, ht‒1는 이전 단계 출력값, ht는 현 단계 출력값, xt는 입력값, bf, bi, bo, bc는 각 단계의 편향값이다. Ct‒1는 이전 단계 셀 상태이고 는 활성화함수를 거친 새로운 셀 상태이다. 본 연구에서는 강우-유출 과정에 적용할 때, 강수 시퀀스가 댐 유입량 시퀀스로 전환되는 과정을 LSTM-s2s 모델을 이용해 댐 유입량 예측을 진행하였다. Fig. 1은 길이 m의 입력데이터와 길이 n의 출력데이터를 가진 LSTM-s2s의 모식도를 나타내고 있다(Xiang et al., 2020). 본 연구에서 입력자료 xt에는 강수, 기온, 그리고 이전 시점 댐 유입량 자료를 넣고, 이 정보가 압축된 context vector (문맥 벡터)는 디코더의 첫 은닉상태가 된다. 또한, ot는 모델예측값을 말한다. 그리고 각 인코더의 입력 시퀀스와 디코더의 출력 시퀀스의 길이가 m과 n인데, 이는 적절하게 수정할 수 있으며 s2s 모델에서 이를 찾는 것은 매우 중요하다(Kao et al., 2020).
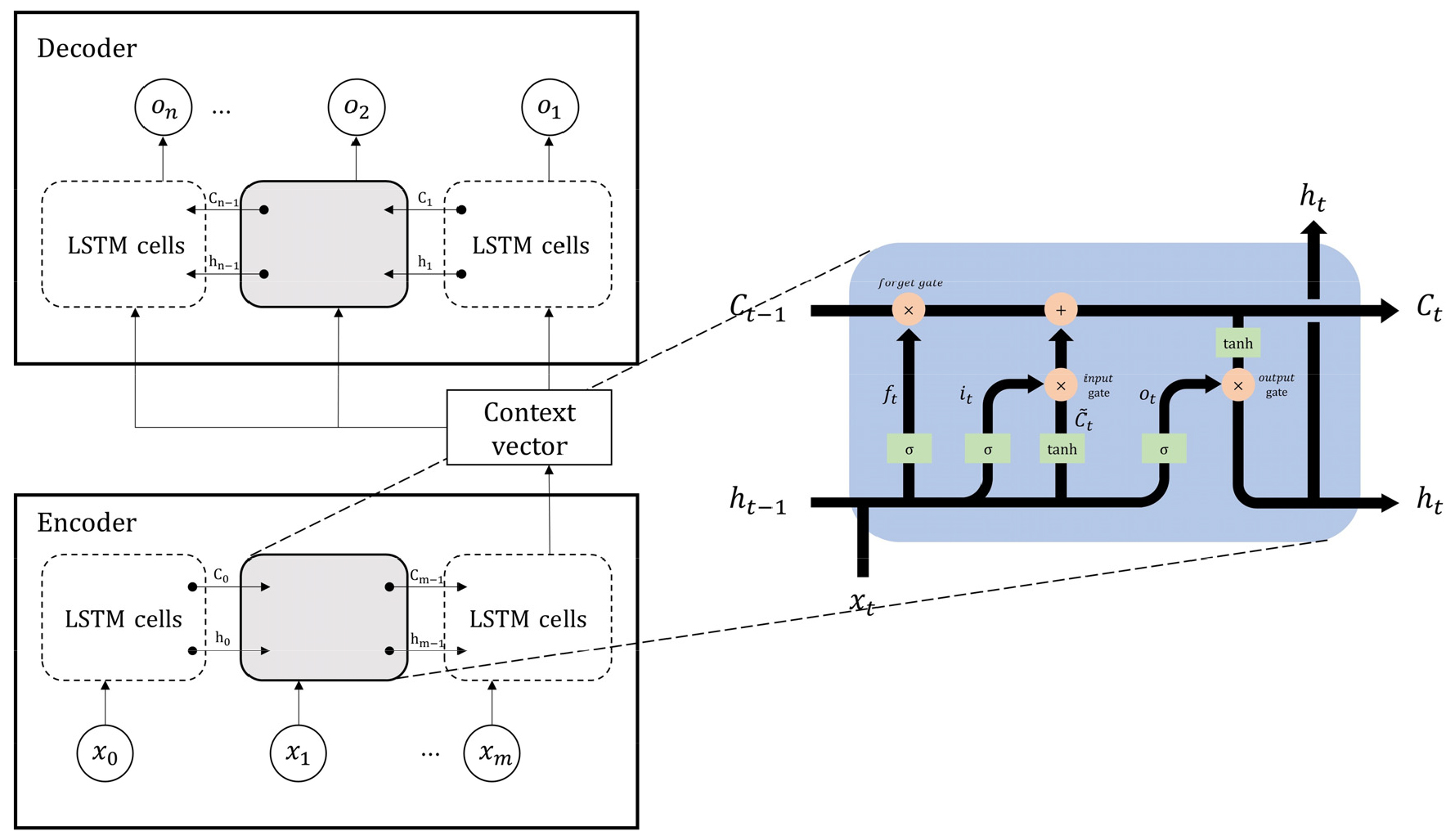
Fig. 1.
Conceptual diagram of the LSTM-based s2s model with m time step input and n time step output reproduced from xiang (Xiang et al, 2020)
2.2 Attention Mechanism
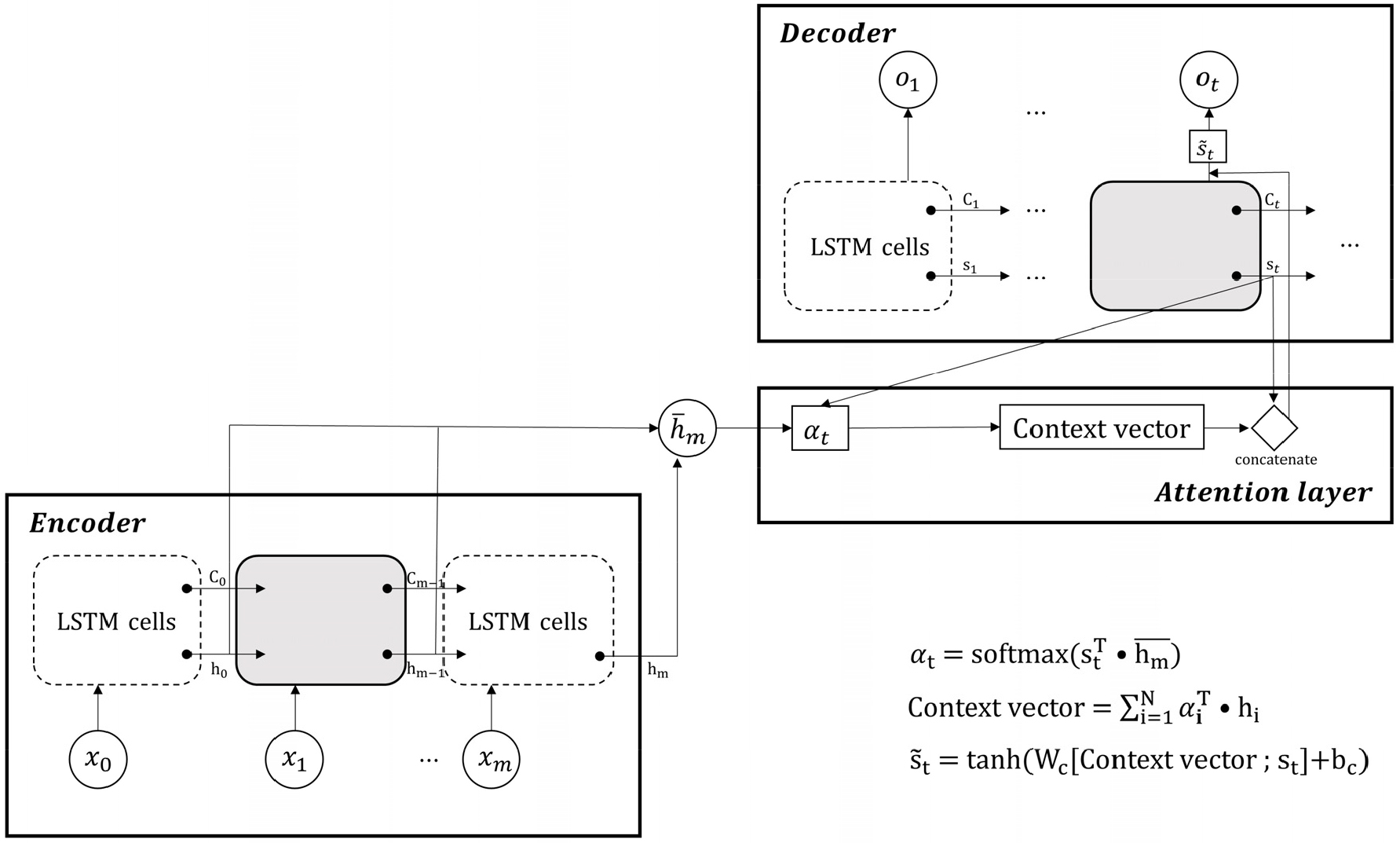
LSTM-s2s 모델이 출력하는 값은 이전 모든 시점을 고려한 값이지만, 입력데이터들이 길어지면 인코더가 생성한 context vector는 제한된 메모리로 입력데이터의 정보를 효과적으로 담기 어려워진다. 이를 해결하기 위해 디코더가 예측할 때, 인코더 입력에 다시 한번 주목하는 Attention 기법이 제안되었다. Attention 기법은 기계번역(Choi et al., 2018), 이미지 분석(Song et al., 2018), 영상 분석(Li et al., 2018) 등에 많은 분야에 사용되고 있으며, 긴 입력자료가 있는 LSTM의 기능을 향상할 수도 있다(Zhou et al., 2019).
Attention 기법은 시점 t에서 출력값을 예측하기 위해 Attention score가 필요하다. 본 연구는 그중에서도 Luong et al. (2015)이 제안한 Luong attention을 사용하였다. Luong attention의 사용은 강우-유출 과정을 통한 시퀀스 전환에서 유출을 예측할 때, 전체 입력데이터를 Attention score의 비율만큼 재참고하여 예측력을 높여주게 된다. Attention score를 계산하고 디코더의 예측값을 위한 입력값을 생성하는 과정과 식은 Eqs. (7)~(10)와 같다(Fig. 2).
여기서 은 인코더의 모든 은닉상태, st는 디코더 현시점의 은닉상태이다. 각 는 현시점 Attention score를 소프트맥스(softmax) 함수로 정규화한 Attention 가중치를 의미하며, st는 디코더 현시점 은닉상태, context vector;st는 둘이 병렬로 연결된 것을 의미하고, 는 현시점 디코더 출력층 입력값을 나타낸다.
2.3 대상유역 및 입력자료
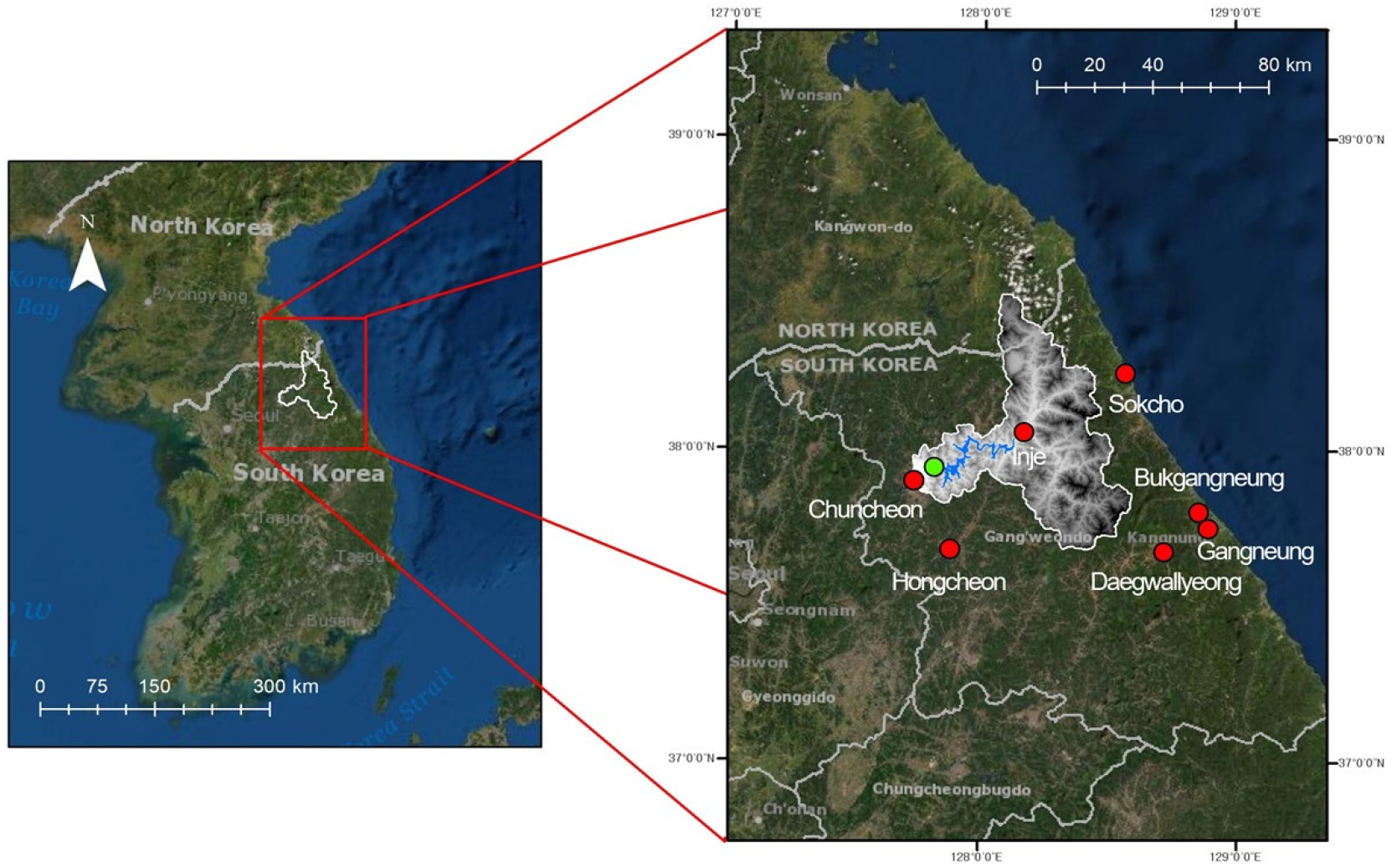
본 연구는 북한강 상류에 위치한 소양강댐 유역을 대상으로 수행하였다(Fig. 3). 소양강댐은 춘천 북동쪽에 위치하며 북한강 유역의 유일한 다목적댐이다(Han et al., 2021). 소양강댐 유역은 그 유역면적이 2,703 km2, 유역연평균강우량은 1,100 mm이며(WAMIS, 2003) 유역면적의 90% 이상이 산림이다(Han et al., 2021). 소양강댐 유역 상류에는 다른 수공 구조물이 없어 이전의 유입량 자료를 통해 이후의 유입량을 예측하기에 적절한 유역이다(Cho and Kim, 2022).
본 연구에 사용한 2013년부터 2020년까지의 시간별 소양강댐의 유입량 자료는 한국수자원공사(K-water)에서 제공하는 자료를 사용하였다. 시간별 종관기상관측(Automated Synoptic Observing System, ASOS) 기온과 강수량 자료는 강릉, 대관령, 북강릉, 속초, 인제, 춘천 그리고 홍천에서 관측된 일 기온, 강수량 자료를 사용하였다(Fig. 3).
2.4 평가지표
본 연구에서는 모델의 예측 성능을 평가하기 위한 지표로 결정계수(Coefficient of determination, R2), 상대평균제곱근오차(Relative Root Mean Squared Error, RRMSE), 상관계수(Correlation coefficient, CC), Nash-Sutcliffe 효율계수(Nash-Sutcliffe efficiency, NSE), 그리고 평균편차비율(Percent bias, PBIAS)을 사용하였고, 식은 Eqs. (11)~(15)와 같다.
여기서, Oi는 관측값, 는 관측값의 평균, Pi는 모델예측값, 는 모델예측값의 평균, 그리고 n은 데이터의 개수이다. R2는 관측값과 모델추정값의 상관관계에 대한 지표이며, 0에서 1까지의 범위를 가진다. 1에 가까울수록 모델 적합도(goodness-of-fit)가 좋은 것이며 0에 가까울수록 안 좋은 것이다(Legates and McCabe, 1999). RRMSE는 RMSE가 관측값의 평균으로 나뉜 지표이며, 오차값을 알 수 있는 RMSE는 상대적인 오차 정도를 알기 어렵기에 RRMSE를 사용하였다. CC는 결정계수와 같이 관측값과 모델추정값의 상관관계에 대한 지표이며, -1에서 1까지의 범위를 가진다. 1에 가까울수록 모델추정값이 관측값과 강한 양의 상관관계가 있다는 의미이다. NSE는 관측값의 분산에 대한 관측값과 모델추정값의 차이를 비교한 지표이다. -∞에서 1까지의 범위를 가지며, 큰 값을 가질수록 좋은 값을 의미한다(Legates and McCabe, 1999). PBIAS는 관측값과 모델추정값의 총량을 비교하는 지표이다. 0에 가까울수록 모델 적합도가 좋은 것이고, 양의 값을 가지면 모델예측값이 과소 추정을, 음의 값을 가지면 과대 추정을 하는 것이다(Li et al., 2009).
3. 모형 구축 및 분석
3.1 모형 구축
본 연구에서는 2013년 1월 1일부터 2017년 10월 15일까지 학습 기간, 2017년 10월 15일부터 2018년 12월 31일까지 검증 기간으로 선정하였다. 그리고 전체 기간 중 30%인 2019년 1월 1일부터 2020년 12월 31일까지의 유입량 자료를 통해 평가 기간으로 설정하여 모델 훈련을 진행하였다.
머신러닝에서 모형 성능을 위해 적절한 Hyperparameter(하이퍼 파라미터)를 찾는 것은 중요하다. 특히 s2s 모델에서는 적절한 인코더의 입력 시퀀스와 디코더의 출력 시퀀스의 길이를 찾는 것이 중요하다(Kao et al., 2020). 본 연구에서는 입력데이터와 출력데이터의 시퀀스 길이를 결정하기 위한 지표로 R2, RRMSE, CC, NSE, 그리고 PBIAS를 사용하였다. 입력 시퀀스 길이의 경우, Kao et al. (2020)의 연구에서 Shihmen Reservoir 유역의 강우-유출 자료를 통해 가장 긴 홍수 전파 시간이 8시간으로 계산된 것을 참고하여, 8시간을 전후로 4시간, 20시간, 24시간을 추가로 진행하였다. 출력 시퀀스 길이는 2시간부터 24시간까지는 2시간 간격으로, 이후 48시간까지는 4시간 간격으로 두고 진행하였다.
LSTM-s2s과 LSTM-s2s에 attention을 첨가한 모델 모두 노드(node)의 개수는 90개이며 노드의 개수는 trial and error를 통해 결정하였다. 최적화 방법으로는 keras에서 제공하는 Adam을 훈련단계에서 사용하였고, 과적합을 방지하기 위해 드롭아웃과 배치 정규화를 적용하였다.
3.2 LSTM-s2s와 Attention을 첨가한 모형 간 최적화 및 비교 분석
LSTM-s2s 모델과 Attention을 첨가한 모델은 디코더의 예측 과정에서 달라지는 메커니즘 때문에 결과에서도 차이를 보였다. 두 모델의 성능 평가를 위해 각 출력 시퀀스 결과별 평균을 활용하였다(Fig. 4, Table 1). PBIAS를 제외한 모든 지표가 출력 시퀀스 길이가 길어질수록 성능이 떨어지는 것을 알 수 있다. R2의 경우에는 출력 시퀀스가 28시간이 되어서야 s2s, Attention 두 모델 전부 0.5 이하의 값을 갖게 되었다. RRMSE는 모든 출력 시퀀스 길이에서 Attention 모델이 s2s 모델보다 좋은 값을 보여주었다. CC는 출력 시퀀스가 14시간이 되어서야 두 모델 전부 0.8에 도달했고, 32시간부터 두 모델의 성능 차이가 생겼으며 s2s 모델은 48시간에 0.6이 되었다. NSE는 출력 시퀀스가 6시간일 때 두 모델 모두 0.75가 되었고, s2s은 약 38시간(36시간: 0.3733, 40시간: 0.3498), Attention은 약 46시간(44시간: 0.3801, 48시간: 0.3464)일 때 0.36이 되었다. 그리고 PBIAS는 s2s 모델의 경우 출력 시퀀스가 10시간일 때 25를 넘어갔고, Attention 모델의 경우 출력 시퀀스가 2시간일 때를 제외하고 44시간에 넘어갔다. 대체로 완만한 상승과 함께 PBIAS가 25를 벗어난 s2s 모델과는 달리, Attention 모델은 0과 25 내에서 변화를 보였다.
앞선 지표들을 바탕으로, 모델 설명력을 만족하는 범위 내 선행 시간(lead time)은 LSTM-s2s의 경우, PBIAS에서 10시간, Attention 모델의 경우, R2에서 28시간이다. 각 모델의 최적 조합은 단조 증가 또는 단조 감소만 하는 RRMSE, R2, CC, NSE에서는 항상 최소 예측 시간(prediction hour)가 유리하다. 따라서 단조 증감을 보이지 않는 PBIAS를 통해 선행 시간을 결정하게 되면 LSTM-s2s는 4시간, Attention 모델은 8시간인 것을 알 수 있다. 이러한 결과는 입력데이터가 길어 디코더가 예측 시 인코더 입력에 한 번 더 주목하는 Attention 모델이 메모리가 제한된 context vector로 정보를 담는 s2s모델보다 유입량 예측에 더 효율적임을 보여주고 있다.
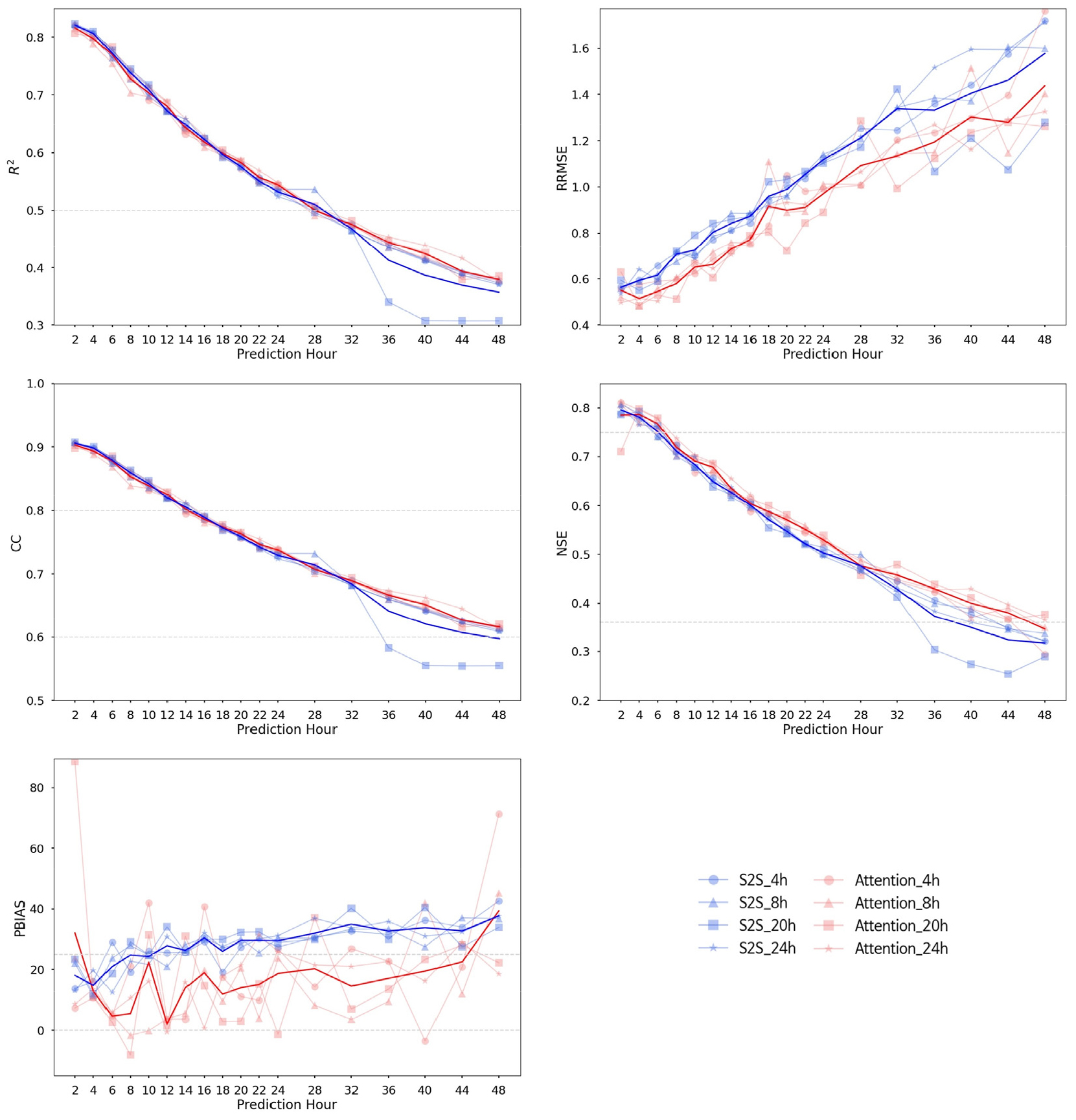
Table 1.
Summary of evaluation result for 8h input sequence and prediction hour from the LSTM-s2s and LSTM-s2s with attention added
3.3 유입량 예측 평가
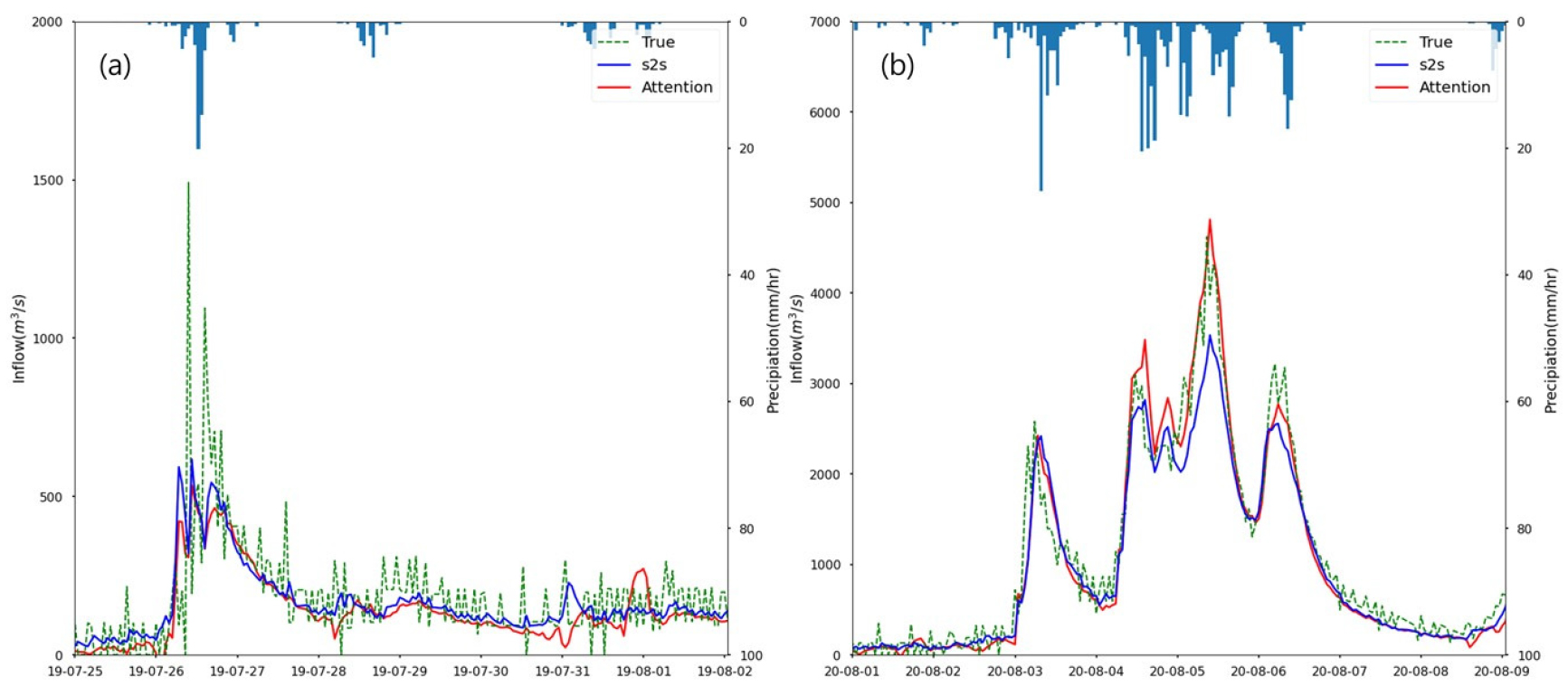
본 연구에서는 LSTM-s2s 모델과 attention을 첨가한 모델을 통한 유입량 예측을 유입량 곡선으로 평가하였다. 앞서 보았듯 출력 시퀀스를 줄이면 성능은 좋아지지만, 그만큼 예측 시간이 줄어들기 때문에 성능이 수용 가능한 범위 내 trade-off를 고려하여 최종 예측분석에 입력-출력 시퀀스 길이 8시간-8시간을 선택하였다. 평가 기간(2019.01.01 - 2020.12.31) 중 2019년과 2020년 각 연도에 가장 유입량이 많았던 두 시점을 선택하였다. 2019년 07월 25일 - 08월 02일(Fig. 5(a)), 2020년 08월 01일 - 08월 09일(Fig. 5(b)) 기간이다.
두 유입량 곡선을 통해, 2019년에서는 두 모델 모두 실제 첨두값을 예측하지 못하였고, 2020년에서 s2s 모델은 전체적인 추이는 따라가지만 첨두값은 실제 유입량보다 과소 추정하였음을 알 수 있다. Fig. 5(a)에서 2019년도의 첨두값이 발생한 지점 부근의 평균절대오차(Mean Absolute Error, MAE)는 attention 모델의 경우 199.7 m3/s였지만, s2s모델의 경우는 209.0 m3/s으로 attention의 평균절대오차가 더 미세하게 낮았다. 다음으로 Fig. 5(b)에서 2020년도의 유입량 곡선을 보면 실제 유입량의 첨두값은 약 5000 m3/s이고 attention 모델의 예측값만이 그 값에 도달하였고, s2s 모델은 그보다 낮은 약 3500 m3/s로 예측하였다. Attention 모델의 경우, 첨두값이 발생한 지점 부근의 평균절대오차는 s2s 모델보다 234.4 m3/s낮은 수치로 매우 근사하게 예측한 것을 알 수 있다. 또한, 두 유입량 곡선에 대한 s2s 모델과 attention 모델의 예측 결과는 비교적 관측된 경향성과 어느 정도 일치하는 것을 확인할 수 있었다. 하지만, 실제 유입량은 시간에 따라 큰 변동성을 가지며 진행되는데 그 불규칙함을 s2s, attention 두 모델 모두 온전하게 예측하지는 못하는 모습을 보였다.
4. 요약 및 결론
본 연구에서는 소양강 다목적댐 유역을 대상으로 LSTM-s2s 모델에 긴 입력자료에 강한 attention 기법을 첨가하여 유입량 예측 분석을 시행하였다. 입력 자료로는 2013년부터 2020년까지의 시간별 소양강댐 유입량 자료와 종관기상관측 지점인 강릉, 대관령, 북강릉, 속초, 인제, 춘천 그리고 홍천에서 관측된 기온과 강수량 자료를 사용하였다. LSTM 모델들은 학습, 검증, 평가로 나누어 훈련을 진행해 결과를 도출하였다.
LSTM-s2s 모델은 입·출력 시퀀스(sequence) 길이를 조절할 수 있는데, 입력 시퀀스 길이는 4시간, 8시간, 20시간, 24시간으로, 이에 따른 출력 시퀀스 길이를 변화하여 예측분석을 진행하였다. 성능과 모델 훈련시간의 trade-off를 고려하여 최종적으로 입력-출력 시퀀스 길이 8시간-8시간 모델을 선택하였다. 8시간-8시간일 경우, LSTM-s2s 모델과 attention을 첨가한 모델로부터 예측된 유입량은 모두 실제 관측값과 비슷한 결과를 보였다. 두 모델의 예측값들은 실제 유입량과 비교하여 볼 때, 전반적인 추세를 잘 따라갈 뿐 아니라 첨두값 예측에도 좋은 성능을 보였다. 다만, s2s 모델과 attention 모델이 예측 시, 5가지 평가지표 중 4가지 지표에서 예측 출력시간이 길어지면서 인코더 입력에 주목 여부에 따라 눈에 띄는 성능 차이를 보였다(3.1 참고). 2013년부터 2020년까지의 8년간 시간 단위의 자료는 attention 기법이 영향을 주는 긴 입력데이터 길이로 판단된다.
예측기간 중 2개의 유입량 곡선을 통해, s2s 모델과 attention 모델의 첨두값 예측 성능에도 차이를 볼 수 있었다. 첨두값을 과소평가하는 s2s 모델과 달리, attention 모델이 첨두값을 더욱 정확하게 예측하는 모습을 확인할 수 있었다. 그러나 실제 시간 단위 유입량은 매우 불규칙하여 s2s 모델과 attention 모델 둘 다 온전히 예측하지 못한 것으로 나타났다. 이를 통해, 두 모델 모두 전체적인 추세를 따라가는 데에는 문제가 없었으나, 시간 단위로 변하는 유입량을 현재의 자료와 모델로 정확하게 예측하기에는 한계가 있었다.
LSTM-s2s에 attention 기법을 첨가한 모델은 LSTM-s2s보다 유입량을 예측하는데 높은 성능을 보여주었다. 본 연구에서는 소양강댐 유역 근방 강수와 기온, 그리고 과거 유입량 자료를 통해 유입량 예측을 하였지만 시간 단위의 불규칙한 패턴까지 예측하기는 어려웠다. 추후 변동모드분해(Variational Mode Decomposition, VMD)를 이용해 시계열 자료를 특정한 주기를 가지는 하위 시계열 자료로 나누어 여러 개의 모델을 훈련하고, 부스트 방식 앙상블을 통해 시간 단위 유입량을 예측을 향상할 것으로 예상된다(He et al., 2020).
